
안녕하세요. ManVSCloud 김수현입니다.
오늘은 긴 시간 미뤄왔던 AWS AURORA의 FAILOVER에 대한 포스팅을 해보려합니다.
이 포스팅에서는 인스턴스 생성 과정 및 보안그룹 설정과 같은 간단한 작업은 생략하였습니다.
AWS 콘솔에서 [장애조치]를 하여 장애조치 과정을 1초마다 확인할 수 있도록 쉘 스크립트를 생성하여 EC2에서 장애조치에 소요되는 시간과 어떻게 변화가 이루어 지는지 확인해볼 것입니다.
그럼 DB 생성부터 시작하도록 하겠습니다.
AURORA DB 생성
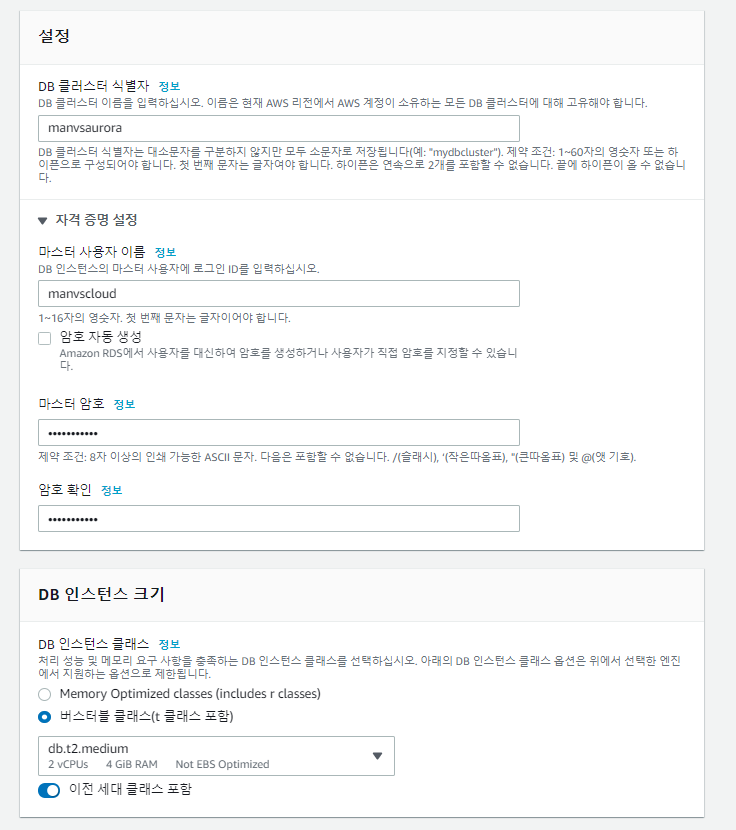
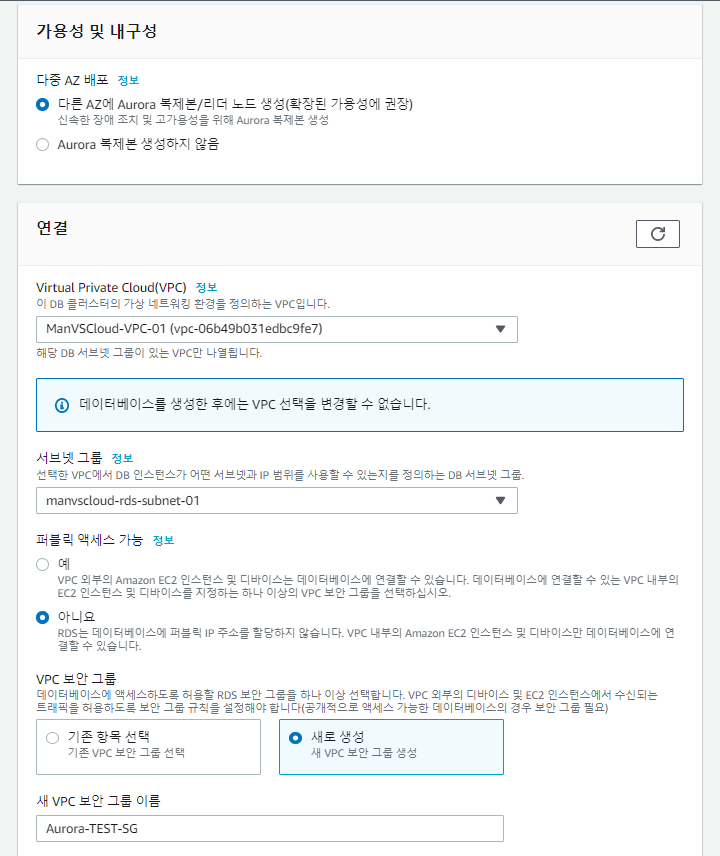
버전은 Aurora (MYSQL 5.7) 2.07.2로 하였으며 DB 생성은 위와 같이 생성하였습니다.
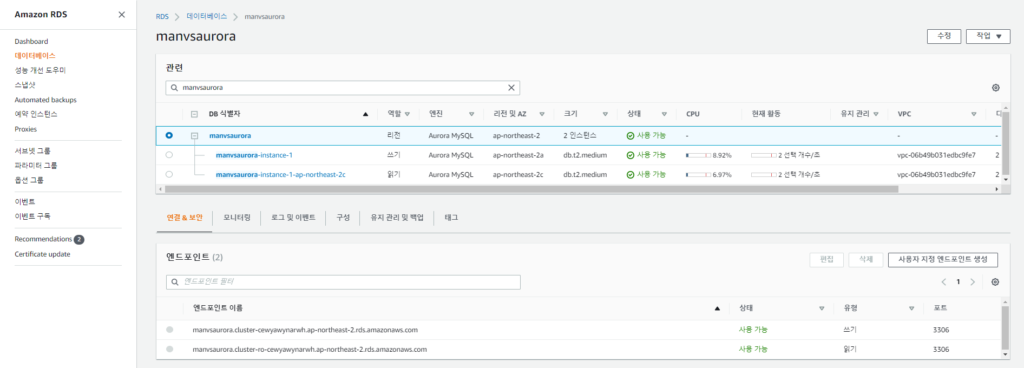
생성하는 부분은 간단하니 추가적인 설명없이 이미지만 첨부하도록 하겠습니다.
이미지가 잘 보이지않을 경우 새 탭을 이용하여 크게 볼 수 있습니다.
EC2 생성
AURORA DB 생성 후 테스트용 EC2를 추가로 생성하였습니다.
해당 EC2로 FAILOVER가 되는 과정을 확인해보려 합니다.
EC2 생성 후 해당 EC2로 접근하여 FAILOVER를 스크립트로 확인하기 위해 date를 국내 시간으로 맞춰주고 mysql client를 설치해주었습니다.

Shell Script 생성과 FAILOVER 테스트
기본적인 준비가 완료되었다면 FAILOVER가 진행되는 과정을 볼 수 있는 스크립트를 만들어보겠습니다.
cd
vi failover.sh
#!/bin/bash
while true
do
DATE=$(date +"%Y년%m월%d일 %H시%M분%S초")
AZ2A=$(echo "show variables like '%innodb_read_only%';" | mysql -u'manvscloud' -p'PW' -h manvsaurora-instance-1.cewyawynarwh.ap-northeast-2.rds.amazonaws.com | grep read | awk '{print $2}')
AZ2C=$(echo "show variables like '%innodb_read_only%';" | mysql -u'manvscloud' -p'PW' -h manvsaurora-instance-1-ap-northeast-2c.cewyawynarwh.ap-northeast-2.rds.amazonaws.com | grep read | awk '{print $2}')
WRITE=$(echo OFF)
READ=$(echo ON)
echo "#########$DATE#########"
if [ $AZ2A == $WRITE ]; then
echo "manvsaurora-instance-1_2A [쓰기]"
elif [ $AZ2A == $READ ]; then
echo "manvsaurora-instance-1_2A [읽기]"
else
echo "FAILOVER 진행중"
fi
if [ $AZ2C == $WRITE ]; then
echo "manvsaurora-instance-1-ap-northeast-2c_2C [쓰기]"
elif [ $AZ2C == $READ ]; then
echo "manvsaurora-instance-1-ap-northeast-2c_2C [읽기]"
else
echo "FAILOVER 진행중"
fi
sleep 1
done
FAILOVER가 되는 과정을 쓰기와 읽기가 바뀌는 것을 이용하여 확인해볼 것입니다.
아래 사진과 같이 show variables like ‘%innodb_read_only%’; 를 이용하여 인스턴스의 읽기/쓰기 상태를 확인합니다.

만들어진 스크립트를 실행할 수 있도록 권한을 변경해주고 아래 명령어를 이용하여 FAILOVER를 진행 상태를 확인해보도록 하겠습니다.
chmod 755 failover.sh
/root/failover.sh 2> /dev/null

백그라운드로 실행하여 텍스트파일로 저장하고 싶으신 경우 위 사진처럼
/root/failover.sh 2> /dev/null > failover.txt & 를 실행하면 failover.txt 파일로 생성되며 데이터가 쌓이게됩니다.
그만 쌓이게 하려면 실행된 프로세스를 kill 하시면됩니다. 위 사진을 예로 kill -9 9402 입니다.
또는 ps 명령어를 이용하여 실행되고 있는 프로세스 PID 를 확인해보시기 바랍니다.
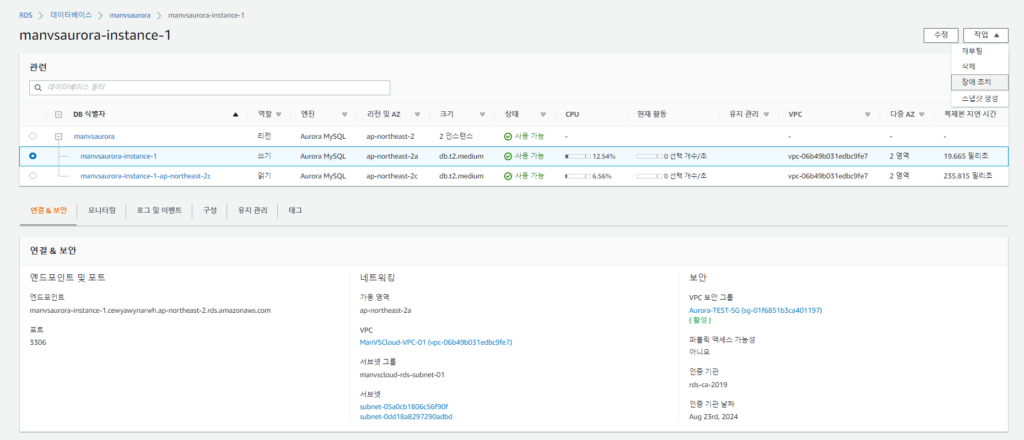
AWS 콘솔로 돌아가 AURORA DB 장애조치를 시작해보겠습니다.
쓰기 인스턴스에 장애조치를 실행해보겠습니다.
-. 현재 상태
ap-northeast-2a : [쓰기]
ap-northeast-2c : [읽기]
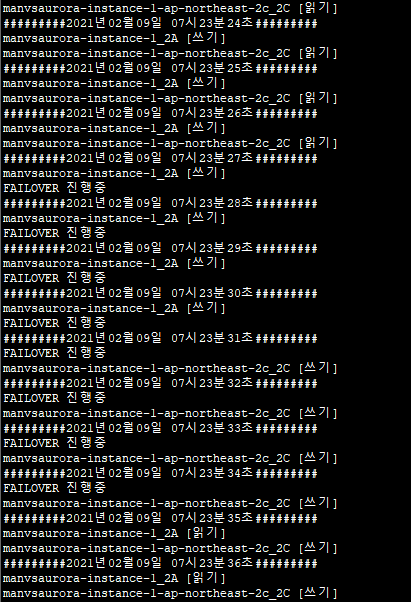
1초마다 인스턴스의 읽기/쓰기 상태가 나오고 있습니다.
[장애조치]를 실행하고 얼마지나지않아 ‘FAILOVER 진행중’ 상태로 변하게됩니다.
두 인스턴스 모두 정상으로 돌아오기까지 약 7~8초가 소요되었습니다.
또한 사진을 보시다시피 2C 가용 영역의 인스턴스가 FAILOVER가 진행되고 얼마 지나지 않아 [쓰기] 상태로 변하고 2A 가용 영역의 인스턴스가 FAILOVER 상태가 되며 [읽기] 상태로 변하게 된 것을 확인할 수 있었습니다.
우선 순위
AURORA DB가 FAILOVER 될 때 먼저 FAILOVER 되는 우선 순위가 있습니다.
장애 복구 시 가장 우선 순위의 티어를 우선적으로 장애 복구를 시작하고
2개 이상의 읽기 복제본이 같은 우선 순위일때는 이전 기본 인스턴스와 같은 용량을 우선 선택하여 장애 복구됩니다.
(동일한 크기의 인스턴스를 FAILOVER 하는 것이 장애 복구 지연 시간을 최소화 할 수 있습니다.)
또한 둘 이상의 Aurora 복제본이 동일한 우선 순위와 크기를 공유하고 있을 경우 동일한 프로모션 계층에서 임의의 복제본을 장애 복구하며, 둘 이상의 Aurora 복제본이 동일한 우선 순위를 공유하는 경우 크기가 가장 큰 복제본을 우선 장애 복구하게 됩니다.
그렇다면 장애 조치 우선 순위는 어떻게 설정하는가?
우선 순위를 변경할 인스턴스를 클릭 후 [수정]을 선택하여 아래 그림과 같이
장애 조치 우선 순위를 변경합니다.
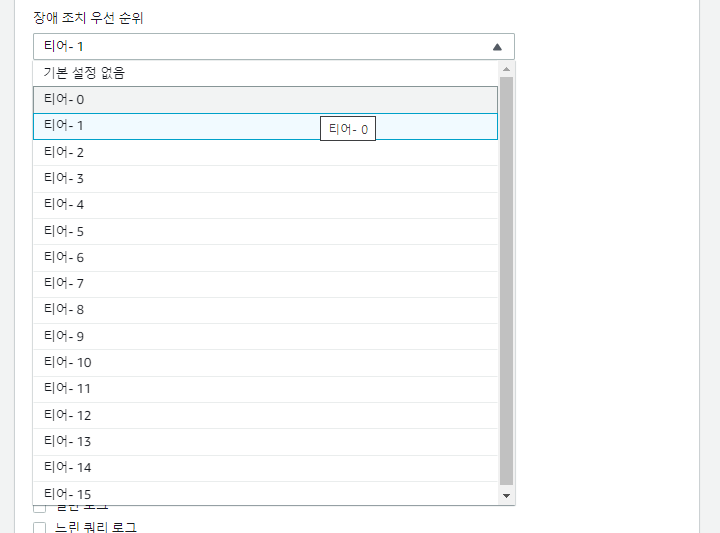
인스턴스가 여러개일 경우 우선 순위 설정을 이용하여 우선 장애조치 순위를 설정하도록 합시다.

추가로 RDS Proxy를 이용하면 장애 조치 시간을 Aurora DB의 경우 최대 79% 일반 RDS 데이터베이스는 최대 32%까지 단축할 수 있다고 합니다.
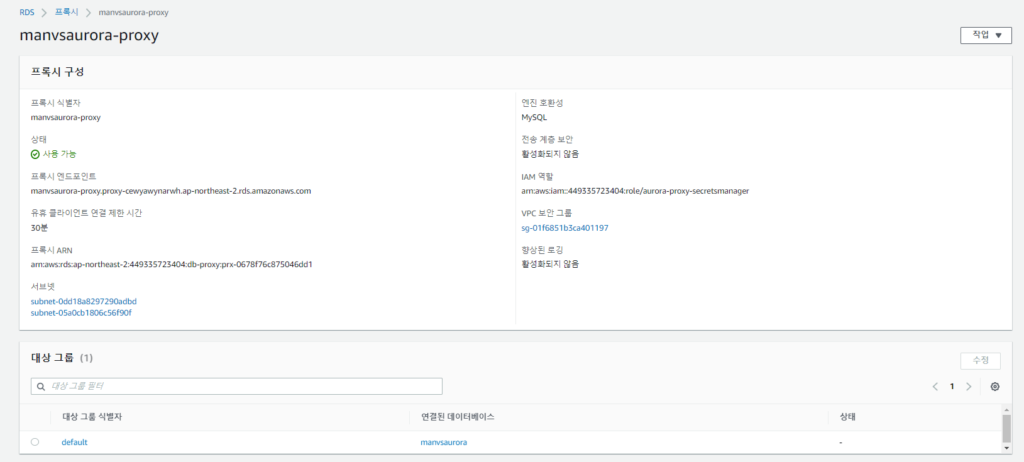
이것 역시 테스트 해봤는데 생성은 잘 됐는데 아래와 같이 핸드쉐이크 에러가 발생하며 접속이 되지않아 포기했습니당…
ERROR 2013 (HY000): Lost connection to MySQL server at ‘handshake: reading initial communication packet’, system error: 11
프록시 엔드포인트로 붙지않네요…
이건 다음에 시간나면 추가 테스트를 진행해보아야겠습니다.
이상 AWS Aurora의 FAILOVER 와 우선 순위에 대해 알아보았습니다.
긴 글 읽어주셔서 감사합니다.
No Comments