
안녕하세요. MANVSCLOUD 김수현입니다.
AWS 환경에서 개발하다 보면 가장 조심해야 할 것 중 하나가 바로 IAM Access Key 관리입니다. 실수로 GitHub에 .env 파일을 푸시하거나 공개 저장소에 키가 노출되는 순간 공격자는 짧은 시간 내에 이를 악용할 수 있습니다. 실제로 GitHub에 업로드된 AWS Credential은 평균 5분 이내에 스캔되고 악용된다고 합니다.
사실 이러한 문제를 해결하기 위해 AWS는 키가 노출될 경우 AWS Health 서비스를 이용하여 사용자에게 알려주고 있습니다.
하지만 평소에 메일을 잘 확인하지 않거나 관리하는 계정이 많아서 자칫 메일을 놓칠 수 있습니다. 따라서 메일 알림을 확인하기까지 시간이 소요되거나 유출된 사실 조차 모른채 지나갈 수 있습니다. 또한 뒤늦게 키 유출 시 시스템에 사용되는 정상적인 호출만 되었는지, 악용된 호출이 있는지 CloudTrail 로그를 수동으로 확인하며 영향 범위를 파악하기에는 오랜 시간이 소요됩니다. 뿐만 아니라 야간이나 휴일에 이러한 사고가 발생한다면 사고 대응 지연으로 이어질 수도 있구요.
오늘은 이러한 문제를 해결하기 위해 AWS의 관리형 서비스들을 조합하여 IAM Access Key 유출 사고를 자동으로 탐지-분석-대응하는 End to End 파이프라인을 구축하는 방법을 소개하겠습니다. 특히 Bedrock Agent를 활용한 AI 기반 사고 분석과 Step Functions의 JSONata를 활용한 유연한 워크플로우 제어에 중점을 두었습니다.
이 시스템을 구성하기 위해 aws-samples에 있는 위 ‘AWS Access Key Exposure Detection and Remediation System’ URL을 참고하였고, 저와 같이 Email이 아닌 다른 솔루션으로 알림을 받길 원하시거나, CloudFormation 형태가 아니라 실제 콘솔에서 직접 구축하여 관리를 원하시는 분들을 위해 조금 더 업그레이드하여 포스팅을 진행했습니다.
시스템 아키텍처 개요
전체 시스템은 이벤트 기반(Event-Driven) 아키텍처로 설계되었으며 Cloud-Native 서비스만으로 구성되어 별도의 인프라 관리 부담 없이 운영할 수 있습니다.
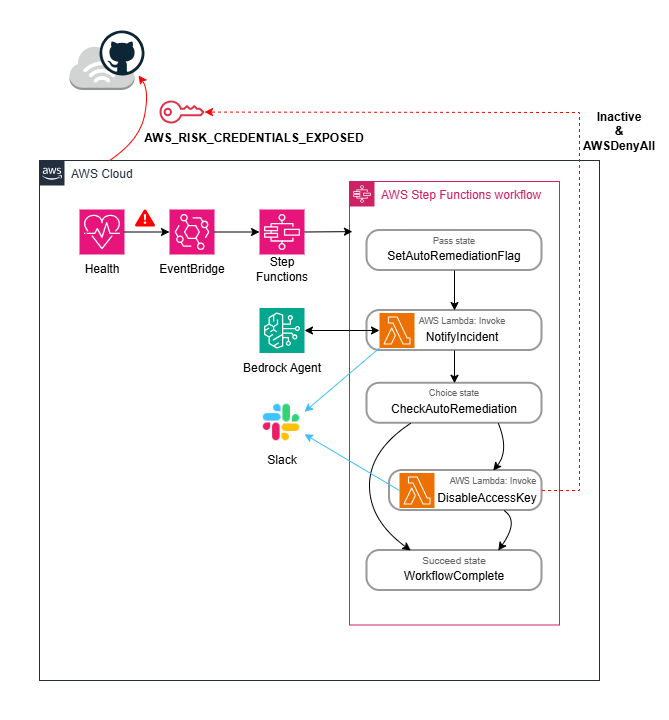
시스템의 전체 흐름은 다음과 같습니다.
- AWS Health가 IAM Access Key 유출을 감지하면
AWS_RISK_CREDENTIALS_EXPOSED이벤트를 발생시킵니다. - EventBridge가 이 이벤트를 포착하여 Step Functions 워크플로우를 시작합니다.
- Step Functions가 Lambda 함수들을 순차적으로 오케스트레이션합니다.
- NotifyIncident Lambda가 CloudTrail을 분석하고 Bedrock Agent로 AI 분석을 수행한 후 Slack으로 알림을 전송합니다.
- 환경변수 설정에 따라 자동으로 Access Key를 비활성화하거나 수동 조치를 대기합니다.
핵심 컴포넌트 구현
1. EventBridge Rule 설정
EventBridge Rule은 AWS Health 이벤트 중 IAM 크레덴셜 유출 이벤트만 필터링하여 Step Functions를 트리거합니다.
{
"source": ["aws.health"],
"detail-type": ["AWS Health Event"],
"detail": {
"eventTypeCode": ["AWS_RISK_CREDENTIALS_EXPOSED"]
}
}
해당 이벤트 패턴을 통해 IAM 관련 보안 사고만 선별적으로 처리할 수 있습니다.
2. Step Functions 워크플로우
Step Functions는 전체 대응 프로세스를 시각적으로 관리하고 오케스트레이션합니다.
콘솔에서 시각적으로 하나씩 선택하여 연결할 수도 있겠지만 본 포스팅에서는 작성된 Amazon States Language(ASL)을 공유하겠습니다.
{
"Comment": "A description of my state machine",
"StartAt": "SetAutoRemediationFlag",
"States": {
"SetAutoRemediationFlag": {
"Type": "Pass",
"Next": "NotifyIncident"
},
"NotifyIncident": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Arguments": {
"FunctionName": "arn:aws:lambda:us-east-1:888888888888:function:manvscloud-risk-credentials-exposed-lmd:$LATEST",
"Payload": "{% $states.input %}"
},
"Output": "{% $states.result.Payload %}",
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2,
"JitterStrategy": "FULL"
}
],
"Next": "CheckAutoRemediation"
},
"CheckAutoRemediation": {
"Type": "Choice",
"Choices": [
{
"Next": "DisableAccessKey",
"Condition": "{% $states.input.enableAutoRemediation = true %}"
}
],
"Default": "WorkflowComplete"
},
"DisableAccessKey": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Arguments": {
"FunctionName": "arn:aws:lambda:us-east-1:888888888888:function:manvscloud-disable-accesskey-lmd:$LATEST",
"Payload": "{% $states.input %}"
},
"Output": "{% $states.result.Payload %}",
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2,
"JitterStrategy": "FULL"
}
],
"Next": "WorkflowComplete"
},
"WorkflowComplete": {
"Type": "Succeed"
}
},
"QueryLanguage": "JSONata"
}
이 과정에서 JSONata를 사용하면 Lambda 함수에 전달할 데이터를 코드 없이 변환할 수 있습니다.
{
"accessKeyId": $.detail.affectedEntities[0].entityValue,
"userName": $.detail.affectedEntities[0].tags.userName,
"eventTime": $.time
}
워크플로우의 주요 단계는 다음과 같습니다.
1) NotifyIncident 단계: CloudTrail 분석 및 AI 기반 사고 요약 생성
2) CheckAutoRemediation 단계: 환경변수 기반으로 자동 복구 여부 확인
3) DisableAccessKey 단계: 자동 모드인 경우 Access Key 비활성화
3. Lambda 함수
- Credentials Exposed Notification
이 Lambda 함수는 보안 사고 대응의 핵심 로직을 담당하며 크게 네 가지 역할을 수행합니다.
1) CloudTrail 로그 분석
: 유출된 Access Key로 수행된 최근 7일간의 모든 API 호출을 분석합니다. 이를 통해 다음 정보를 수집합니다.
– 사용된 AWS 리전 목록
– 호출된 API 작업 유형 및 빈도
– 접근 소스 IP 주소 분석
– 에러 발생 여부 (권한 부족 시도 등 의심스러운 행동 패턴)
# CloudTrail API 호출 예시
cloudtrail_client = boto3.client('cloudtrail')
response = cloudtrail_client.lookup_events(
LookupAttributes=[
{
'AttributeKey': 'AccessKeyId',
'AttributeValue': access_key_id
}
],
StartTime=datetime.now() - timedelta(days=7),
MaxResults=50
)
위 분석을 통해 공격자가 이미 해당 키를 악용했는지, 어떤 리소스에 접근을 시도했는지 파악할 수 있습니다.
2) Bedrock Agent 기반 AI 분석
: 현재 구현하고자 하는 시스템에서 Bedrock Foundation 모델을 그냥 사용해도 되지만 굳이 Bedrock Agent를 사용한 이유는 Lambda 코드에 지저분하게 프롬프트를 깍아가며 관리하지 않고 Agent의 에이전트 지침으로 프롬프트를 관리하며 Versioning을 활용하여 교체하는 방식으로 사용하고 싶었기때문입니다.
수집된 CloudTrail 데이터를 Bedrock Agent에게 전달하여 AI 기반 분석을 수행합니다.
Bedrock Agent는 단순 패턴 매칭을 넘어 전체 컨텍스트를 이해하고 종합적인 분석을 제공합니다.
– 사고의 심각도 평가 (Critical/High/Medium/Low)
– 영향 받은 서비스 및 리소스 식별
– 잠재적 피해 범위 예측
– 권장 후속 조치 제안
예를 들어 S3 버킷 접근 시도가 있었다면 데이터 유출 가능성을, EC2 인스턴스 생성 시도가 있었다면 암호화폐 채굴 위험을 자동으로 언급합니다.
# Bedrock Agent 호출 예시
bedrock_agent = boto3.client('bedrock-agent-runtime')
response = bedrock_agent.invoke_agent(
agentId=agent_id,
agentAliasId=agent_alias_id,
sessionId=session_id,
inputText=f"다음 CloudTrail 로그를 분석해주세요: {cloudtrail_summary}"
)
```
Bedrock Agent를 효과적으로 활용하기 위해서는 적절한 프롬프트 설정이 중요합니다:
```
당신은 AWS 보안 전문가입니다. 다음 CloudTrail 로그를 분석하여:
1. 사고 심각도를 평가하세요 (Critical/High/Medium/Low)
2. 공격자가 접근한 리소스를 식별하세요
3. 잠재적 피해 범위를 예측하세요
4. 권장 후속 조치를 제안하세요
JSON 형식으로 구조화된 응답을 제공하세요.
3) Slack 알림 전송
분석 결과를 Slack 채널로 실시간 전송합니다. 사실 요즘 이메일은 주기적으로 잘 확인을 안하게 되어 Slack을 선택했습니다. Slack 알림에는 다음 정보가 포함됩니다.
- 유출된 Access Key 정보 (Key ID, IAM User)
- CloudTrail 분석 결과 요약 (사용된 리전, API 호출 통계, 소스 IP)
- AI가 생성한 위험도 평가 및 분석
- 자동 조치 실행 여부
- Step Functions 실행 링크 (상세 추적용)
4) 환경변수 기반 동작 제어
이 부분은 선택적 요소인데 ENABLE_AUTO_REMEDIATION 환경변수를 통해 자동/수동 대응 모드를 제어할 수 있습니다.
– true : Access Key를 즉시 자동 비활성화
– false : 알림만 전송하고 수동 조치 대기
제 코드에 적용된 환경 변수는 아래와 같습니다.
- BEDROCK_AGENT_ALIAS_ID
- BEDROCK_AGENT_ID
- ENABLE_AUTO_REMEDIATION
- MANAGED_PRIMARY
- MANAGED_SECONDARY
- SLACK_WEBHOOK_URL
- SYSTEM_OWNER
5) IAM 역할에 포함된 정책
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:us-east-1:888888888888:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:us-east-1:888888888888:log-group:/aws/lambda/manvscloud-risk-credentials-exposed-lmd:*"
]
},
{
"Sid": "EC2DescribeRegions",
"Effect": "Allow",
"Action": [
"ec2:DescribeRegions"
],
"Resource": "*"
},
{
"Sid": "CloudTrailLookupEvents",
"Effect": "Allow",
"Action": [
"cloudtrail:LookupEvents"
],
"Resource": "*"
},
{
"Sid": "BedrockInvokeModel",
"Effect": "Allow",
"Action": [
"bedrock:InvokeAgent"
],
"Resource": [
"arn:aws:bedrock:us-east-1:888888888888:agent/*",
"arn:aws:bedrock:us-east-1:888888888888:agent-alias/*"
]
}
]
}
이를 통해 프로덕션 환경의 중요 키는 수동 승인 후 처리하고 개발 환경은 즉시 자동 차단하는 등 유연한 정책 적용이 가능합니다. 환경별로 Lambda 함수를 분리하거나 태그 기반으로 정책을 달리 적용할 수도 있습니다.
# manvscloud-risk-credentials-exposed-lmd
import json
import boto3
from datetime import datetime, timedelta, timezone
from collections import defaultdict
import os
import urllib.request
import urllib.error
import traceback
def analyze_cloudtrail_events(access_key_id, start_time=None):
results = {
'events': [],
'total_events': 0
}
try:
ec2 = boto3.client('ec2')
regions = [region['RegionName'] for region in ec2.describe_regions()['Regions']]
regions.append('us-east-1')
except Exception as e:
print(f"Error getting regions: {str(e)}")
regions = ['us-east-1']
if not start_time:
start_time = datetime.now(timezone.utc) - timedelta(days=7)
for region in set(regions):
try:
cloudtrail = boto3.client('cloudtrail', region_name=region)
paginator = cloudtrail.get_paginator('lookup_events')
for page in paginator.paginate(
LookupAttributes=[{
'AttributeKey': 'AccessKeyId',
'AttributeValue': access_key_id
}],
StartTime=start_time
):
for event in page.get('Events', []):
try:
event_data = json.loads(event.get('CloudTrailEvent', '{}'))
api_name = event_data.get('eventName', 'Unknown')
source_ip = event_data.get('sourceIPAddress', 'Unknown')
results['events'].append({
'region': region,
'api_name': api_name,
'source_ip': source_ip
})
results['total_events'] += 1
except Exception as e:
print(f"Error parsing CloudTrail event: {str(e)}")
continue
except Exception as e:
print(f"Error in region {region}: {str(e)}")
continue
return results
def get_ai_incident_summary_with_agent(incident_details, event_summary):
"""Bedrock Agent를 사용하여 사고 분석 생성"""
try:
print("=== INITIALIZING BEDROCK AGENT RUNTIME CLIENT ===")
bedrock_agent_runtime = boto3.client('bedrock-agent-runtime', region_name='us-east-1')
agent_id = os.environ.get('BEDROCK_AGENT_ID')
agent_alias_id = os.environ.get('BEDROCK_AGENT_ALIAS_ID')
if not agent_id:
raise ValueError("BEDROCK_AGENT_ID environment variable is not set")
if not agent_alias_id:
raise ValueError("BEDROCK_AGENT_ALIAS_ID environment variable is not set")
print(f"Agent ID: {agent_id}")
print(f"Agent Alias ID: {agent_alias_id}")
# CloudTrail 이벤트 데이터 포맷팅
event_counts = {}
for event in event_summary['events']:
key = (event['region'], event['api_name'], event['source_ip'])
event_counts[key] = event_counts.get(key, 0) + 1
event_activities_list = []
for (region, api, ip), count in sorted(event_counts.items(), key=lambda x: x[1], reverse=True):
event_activities_list.append(f"Region: {region}, API: {api}, IP: {ip}, Count: {count}")
event_activities = "\n".join(event_activities_list) if event_activities_list else "최근 7일간 활동 기록 없음"
# Agent에게 전달할 프롬프트
prompt = f"""AWS IAM Credential 유출 사고를 분석해주세요.
사고 정보:
{incident_details}
CloudTrail API 활동 분석 (최근 7일):
총 이벤트 수: {event_summary['total_events']}
활동 내역:
{event_activities}
다음 항목들을 포함하여 분석해주세요:
1. 사고 요약 (2-3문장)
2. 주요 API 활동 분석
3. 리전별 활동 분석
4. 위험도 평가 (HIGH/MEDIUM/LOW)
모든 응답은 한국어로 작성해주세요."""
# 세션 ID 생성
session_id = f"incident-{datetime.now().strftime('%Y%m%d-%H%M%S')}"
print(f"=== INVOKING BEDROCK AGENT ===")
print(f"Session ID: {session_id}")
print(f"Prompt length: {len(prompt)} characters")
# Bedrock Agent 호출
response = bedrock_agent_runtime.invoke_agent(
agentId=agent_id,
agentAliasId=agent_alias_id,
sessionId=session_id,
inputText=prompt,
enableTrace=True, # 디버깅을 위해 trace 활성화
endSession=False
)
print("=== AGENT INVOCATION SUCCESSFUL ===")
print(f"Response keys: {list(response.keys())}")
# 응답 스트림 처리
completion_text = ""
chunk_count = 0
print("=== PROCESSING AGENT RESPONSE STREAM ===")
if 'completion' not in response:
raise Exception("No 'completion' field in agent response")
event_stream = response['completion']
for event in event_stream:
try:
# chunk 이벤트 처리
if 'chunk' in event:
chunk = event['chunk']
if 'bytes' in chunk:
chunk_text = chunk['bytes'].decode('utf-8')
completion_text += chunk_text
chunk_count += 1
print(f"Chunk {chunk_count}: {len(chunk_text)} bytes")
# trace 이벤트 처리 (디버깅용)
elif 'trace' in event:
trace = event['trace']
trace_type = trace.get('trace', {}).get('type', 'unknown')
print(f"Trace event type: {trace_type}")
# 에러 이벤트 처리
elif 'internalServerException' in event:
error = event['internalServerException']
raise Exception(f"Agent internal server error: {error}")
elif 'validationException' in event:
error = event['validationException']
raise Exception(f"Agent validation error: {error}")
elif 'throttlingException' in event:
error = event['throttlingException']
raise Exception(f"Agent throttling error: {error}")
except Exception as stream_error:
print(f"Error processing stream event: {str(stream_error)}")
print(f"Event content: {json.dumps(event, default=str)}")
# 스트림 에러는 계속 진행
continue
ai_summary = completion_text.strip()
print(f"=== AGENT RESPONSE COMPLETE ===")
print(f"Total chunks received: {chunk_count}")
print(f"Total response length: {len(ai_summary)} characters")
if not ai_summary:
raise Exception("Agent returned empty response")
print(f"Response preview (first 200 chars): {ai_summary[:200]}")
return ai_summary
except Exception as e:
error_msg = f"Error in get_ai_incident_summary_with_agent: {str(e)}"
print(error_msg)
print("=== FULL TRACEBACK ===")
print(traceback.format_exc())
return f"AI 분석 생성 중 오류 발생: {str(e)}"
def format_slack_message(access_key_id, user, account_id, exposed_url, event_time,
ai_summary, event_summary):
current_time = datetime.now(timezone.utc)
event_counts = {}
for event in event_summary['events']:
key = (event['region'], event['api_name'], event['source_ip'])
event_counts[key] = event_counts.get(key, 0) + 1
api_activity = ""
for (region, api_name, source_ip), count in sorted(event_counts.items(),
key=lambda x: x[1],
reverse=True)[:20]:
api_activity += f"• `{region}` | `{api_name}` | `{source_ip}` | {count}회\n"
if not api_activity:
api_activity = "• 최근 7일간 활동 기록 없음\n"
managed_primary = os.environ.get('MANAGED_PRIMARY', 'test1@example.com')
managed_secondary = os.environ.get('MANAGED_SECONDARY', 'test2@example.com')
system_owner = os.environ.get('SYSTEM_OWNER', 'test3@example.com')
slack_message = {
"blocks": [
{
"type": "header",
"text": {
"type": "plain_text",
"text": "🚨 [CRITICAL] AWS IAM Credential 유출 확정 감지"
}
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*AWS Health Event를 통해 AWS가 공식적으로 IAM Credential 유출을 확정했습니다.*"
}
},
{
"type": "divider"
},
{
"type": "section",
"fields": [
{
"type": "mrkdwn",
"text": f"*이벤트 유형*\n`AWS_RISK_CREDENTIALS_EXPOSED`"
},
{
"type": "mrkdwn",
"text": f"*감지 시각*\n`{current_time.strftime('%Y-%m-%d %H:%M:%S UTC')}`"
}
]
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"*영향받은 IAM Credential*\n```{access_key_id}```"
}
},
{
"type": "divider"
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*사고 정보*"
}
},
{
"type": "section",
"fields": [
{
"type": "mrkdwn",
"text": f"*Access Key ID*\n`{access_key_id}`"
},
{
"type": "mrkdwn",
"text": f"*사용자명*\n`{user}`"
},
{
"type": "mrkdwn",
"text": f"*계정 ID*\n`{account_id}`"
},
{
"type": "mrkdwn",
"text": f"*발생 시간*\n`{event_time}`"
}
]
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"*노출 URL*\n{exposed_url}"
}
},
{
"type": "divider"
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"*사고 요약 (AI 생성)*\n{ai_summary}"
}
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"*API 활동 분석 (최근 7일, 상위 20개)*\n총 이벤트: {event_summary['total_events']}회\n{api_activity}"
}
},
{
"type": "divider"
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*즉시 대응 필요*"
}
},
{
"type": "section",
"fields": [
{
"type": "mrkdwn",
"text": f"*Managed 담당(정)*\n{managed_primary}"
},
{
"type": "mrkdwn",
"text": f"*Managed 담당(부)*\n{managed_secondary}"
},
{
"type": "mrkdwn",
"text": f"*시스템 담당자*\n{system_owner}"
}
]
},
{
"type": "divider"
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*권장 대응 순서*\n:one: 해당 Access Key 즉시 비활성화 또는 삭제\n:two: IAM User 권한 점검 및 Quarantine 여부 확인\n:three: 최근 CloudTrail 로그 분석\n:four: 비용 이상 여부 확인\n:five: 필요 시 보안 사고로 에스컬레이션"
}
}
]
}
return slack_message
def send_slack_notification(webhook_url, message):
try:
data = json.dumps(message).encode('utf-8')
req = urllib.request.Request(
webhook_url,
data=data,
headers={'Content-Type': 'application/json'}
)
with urllib.request.urlopen(req) as response:
if response.status == 200:
print("Slack notification sent successfully")
return {
'statusCode': 200,
'body': json.dumps('Slack notification sent successfully')
}
else:
print(f"Slack API returned status: {response.status}")
return {
'statusCode': response.status,
'body': json.dumps(f'Slack API returned status: {response.status}')
}
except urllib.error.HTTPError as e:
error_msg = f'HTTP Error sending to Slack: {e.code} - {e.reason}'
print(error_msg)
return {
'statusCode': e.code,
'body': json.dumps(error_msg)
}
except Exception as e:
error_msg = f'Error sending to Slack: {str(e)}'
print(error_msg)
return {
'statusCode': 500,
'body': json.dumps(error_msg)
}
def lambda_handler(event, context):
try:
print("=== LAMBDA HANDLER STARTED ===")
print("=== RECEIVED EVENT ===")
print(json.dumps(event, indent=2, default=str))
detail = None
if 'event' in event and isinstance(event.get('event'), dict) and 'detail' in event.get('event', {}):
print("=== CASE 1: EventBridge format ===")
health_event = event.get('event', {})
detail = health_event.get('detail', {})
elif 'detail' in event:
print("=== CASE 2: Direct Step Functions format ===")
detail = event.get('detail', {})
elif 'detail-type' in event and event.get('detail-type') == 'AWS Health Event':
print("=== CASE 3: Raw AWS Health Event format ===")
detail = event.get('detail', {})
else:
print("=== ERROR: Invalid event structure ===")
print(f"Event keys: {list(event.keys())}")
return {
'statusCode': 400,
'body': json.dumps('Invalid event structure. Missing "detail" field.')
}
print("=== DETAIL STRUCTURE ===")
print(json.dumps(detail, indent=2, default=str))
print(f"Detail keys: {list(detail.keys())}")
if 'eventMetadata' not in detail:
print("=== ERROR: eventMetadata not found in detail ===")
return {
'statusCode': 400,
'body': json.dumps(f'eventMetadata not found in detail. Available keys: {list(detail.keys())}')
}
event_metadata = detail.get('eventMetadata', {})
print(f"=== EVENT METADATA ===")
print(json.dumps(event_metadata, indent=2, default=str))
access_key_id = event_metadata.get('publicKey', 'N/A')
user = event_metadata.get('userName', 'N/A')
account_id = event_metadata.get('accountId', 'N/A')
exposed_url = event_metadata.get('exposedUrl', 'N/A')
event_time = detail.get('startTime', 'N/A')
print(f"=== EXTRACTED VALUES ===")
print(f"Access Key ID: {access_key_id}")
print(f"User: {user}")
print(f"Account ID: {account_id}")
print(f"Exposed URL: {exposed_url}")
print(f"Event Time: {event_time}")
print("=== STARTING CLOUDTRAIL ANALYSIS ===")
try:
event_summary = analyze_cloudtrail_events(access_key_id)
print(f"CloudTrail analysis completed. Total events: {event_summary['total_events']}")
except Exception as e:
print(f"ERROR in CloudTrail analysis: {str(e)}")
print(traceback.format_exc())
event_summary = {'events': [], 'total_events': 0}
incident_summary = f"""Access Key ID: {access_key_id}
User: {user}
Account ID: {account_id}
Exposure Source: {exposed_url}
Detection Time: {event_time}"""
print("=== CALLING BEDROCK AGENT FOR AI SUMMARY ===")
try:
ai_summary = get_ai_incident_summary_with_agent(incident_summary, event_summary)
print(f"AI summary generated successfully. Length: {len(ai_summary)}")
print(f"AI Summary preview: {ai_summary[:200]}...")
except Exception as e:
print(f"ERROR generating AI summary: {str(e)}")
print(traceback.format_exc())
ai_summary = f"AI 분석 생성 중 오류 발생: {str(e)}"
print("=== FORMATTING SLACK MESSAGE ===")
try:
slack_message = format_slack_message(
access_key_id, user, account_id, exposed_url, event_time,
ai_summary, event_summary
)
print("Slack message formatted successfully")
print(f"Message blocks count: {len(slack_message['blocks'])}")
except Exception as e:
print(f"ERROR formatting Slack message: {str(e)}")
print(traceback.format_exc())
return {
'statusCode': 500,
'body': json.dumps(f'Error formatting message: {str(e)}')
}
print("=== PREPARING TO SEND SLACK NOTIFICATION ===")
webhook_url = os.environ.get('SLACK_WEBHOOK_URL')
if not webhook_url:
print("ERROR: SLACK_WEBHOOK_URL environment variable not set")
return {
'statusCode': 500,
'body': json.dumps('SLACK_WEBHOOK_URL environment variable not set')
}
print(f"Webhook URL found (length: {len(webhook_url)})")
print("=== SENDING SLACK NOTIFICATION ===")
try:
result = send_slack_notification(webhook_url, slack_message)
print(f"Slack notification result: {result}")
# 환경변수에서 자동 복구 설정 읽기
enable_auto_remediation = os.environ.get('ENABLE_AUTO_REMEDIATION', 'false').lower() == 'true'
print(f"=== AUTO REMEDIATION SETTING: {enable_auto_remediation} ===")
# Step Functions로 전달할 응답 구성
response = {
'statusCode': result['statusCode'],
'body': result['body'],
'enableAutoRemediation': enable_auto_remediation,
'accessKeyId': access_key_id,
'userName': user,
'accountId': account_id
}
print("=== LAMBDA HANDLER COMPLETED SUCCESSFULLY ===")
print(f"Response: {json.dumps(response, indent=2)}")
return response
except Exception as e:
print(f"ERROR sending Slack notification: {str(e)}")
print(traceback.format_exc())
return {
'statusCode': 500,
'body': json.dumps(f'Error sending notification: {str(e)}'),
'enableAutoRemediation': False
}
except Exception as e:
# 최상위 예외 처리
print(f"=== UNHANDLED EXCEPTION IN LAMBDA HANDLER ===")
print(f"Error: {str(e)}")
print(traceback.format_exc())
return {
'statusCode': 500,
'body': json.dumps(f'Unhandled exception: {str(e)}'),
'enableAutoRemediation': False
}
Step Functions 과정에서 위 Lambda가 동작하면 아래와 같이 Slack으로 알림을 받을 수 있습니다.
유출 감지 시각, 유출된 계정 및 키 정보, 유출된 URL 그리고 Bedrock이 Cloudtrail을 먼저 빠르게 분석하여 알려주는 정보까지 Slack으로 결과만 보고 받고 사용자는 다음 행동을 판단하면 됩니다.
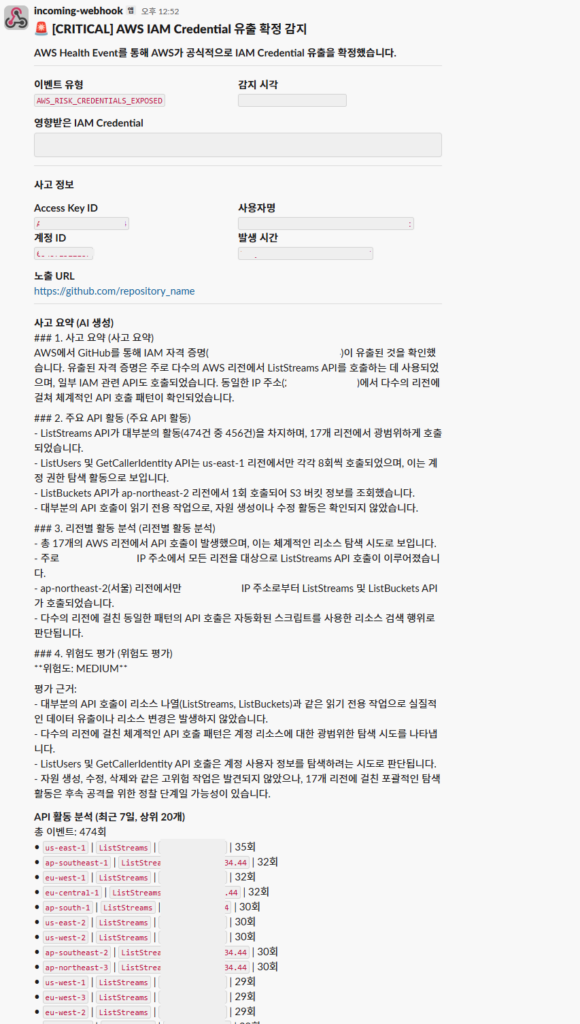
- DisableAccessKey
자동 복구 모드가 활성화된 경우 이 Lambda 함수가 유출된 Access Key를 즉시 비활성화합니다.
(요구 사항에 따라 Access Key 비활성화가 아니라 다른 조치가 진행되도록 변경할 수도 있습니다.)
import boto3
def lambda_handler(event, context):
iam_client = boto3.client('iam')
user_name = event['userName']
access_key_id = event['accessKeyId']
# Access Key 비활성화
iam_client.update_access_key(
UserName=user_name,
AccessKeyId=access_key_id,
Status='Inactive'
)
# 완료 알림 전송
send_slack_notification(f"Access Key {access_key_id}가 자동으로 비활성화되었습니다.")
return {
'statusCode': 200,
'body': 'Access Key disabled successfully'
}
1) 적용된 환경 변수
- DENY_POLICY_ARN
- SLACK_WEBHOOK_URL
2) IAM 역할에 포함된 정책
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:us-east-1:888888888888:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:us-east-1:888888888888:log-group:/aws/lambda/manvscloud-disable-accesskey-lmd:*"
]
},
{
"Sid": "DisableAccessKey",
"Effect": "Allow",
"Action": [
"iam:UpdateAccessKey"
],
"Resource": "arn:aws:iam::*:user/*"
},
{
"Sid": "AttachDenyPolicy",
"Effect": "Allow",
"Action": [
"iam:AttachUserPolicy"
],
"Resource": "arn:aws:iam::*:user/*",
"Condition": {
"ArnEquals": {
"iam:PolicyARN": "arn:aws:iam::888888888888:policy/manvscloud-CompromisedUserDenyAll-policy"
}
}
}
]
}
비활성화 후에는 CloudWatch Logs에 조치를 기록하고 Slack으로 완료 알림을 전송합니다. 멱등성이 보장되어 이미 비활성화된 키에 대해서도 에러 없이 처리됩니다.
# manvscloud-disable-accesskey-lmd
import json
import boto3
from datetime import datetime, timezone
import os
import urllib3
import traceback
http = urllib3.PoolManager()
def attach_existing_deny_policy(username):
"""Attach pre-created deny policy to the compromised user"""
try:
iam = boto3.client('iam')
# 환경 변수에서 정책 ARN 가져오기
policy_arn = os.environ.get('DENY_POLICY_ARN')
if not policy_arn:
return False, "DENY_POLICY_ARN environment variable not set"
print(f"Attempting to attach policy {policy_arn} to user {username}")
# 기존 정책을 사용자에게 연결
iam.attach_user_policy(
UserName=username,
PolicyArn=policy_arn
)
print(f"Successfully attached policy to {username}")
return True, f"Successfully attached deny policy: {policy_arn}"
except Exception as e:
error_msg = f"Failed to attach deny policy: {str(e)}\n{traceback.format_exc()}"
print(error_msg)
return False, error_msg
def send_slack_notification(username, access_key_id, account_id, policy_attached, policy_message):
"""Send Slack notification about remediation actions"""
try:
webhook_url = os.environ.get('SLACK_WEBHOOK_URL')
if not webhook_url:
print("SLACK_WEBHOOK_URL environment variable not set")
return False
current_time = datetime.now(timezone.utc)
# Slack 메시지 구성 (한국어)
slack_message = {
"text": "🛡️ AWS 액세스 키 자동 비활성화",
"blocks": [
{
"type": "header",
"text": {
"type": "plain_text",
"text": "🛡️ AWS 액세스 키 자동 비활성화",
"emoji": True
}
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*자동 보안 조치 완료*\n노출된 AWS 액세스 키가 자동으로 비활성화되었으며, 추가 보안 조치가 적용되었습니다."
}
},
{
"type": "divider"
},
{
"type": "section",
"fields": [
{
"type": "mrkdwn",
"text": f"*AWS 계정 ID:*\n`{account_id}`"
},
{
"type": "mrkdwn",
"text": f"*IAM 사용자:*\n`{username}`"
},
{
"type": "mrkdwn",
"text": f"*액세스 키 ID:*\n`{access_key_id}`"
},
{
"type": "mrkdwn",
"text": f"*액세스 키 상태:*\n`비활성화됨`"
},
{
"type": "mrkdwn",
"text": f"*Deny 정책 상태:*\n{'✅ 적용됨' if policy_attached else '❌ 실패'}"
},
{
"type": "mrkdwn",
"text": f"*조치 시각:*\n`{current_time.strftime('%Y년 %m월 %d일 %H:%M:%S UTC')}`"
}
]
},
{
"type": "divider"
},
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*다음 조치 사항:*\n• AccessKey 비활성화로 인한 서비스 이상 유무 확인\n• 필요 시 새로운 액세스 키 생성\n• 기존 액세스 키를 사용하는 애플리케이션 업데이트\n• 액세스 키 외부 업로드 및 유출 금지"
}
},
{
"type": "context",
"elements": [
{
"type": "mrkdwn",
"text": "_자동 보안 조치 알림입니다._"
}
]
}
]
}
# 정책 첨부 실패 시 추가 정보 표시
if not policy_attached:
slack_message["blocks"].insert(5, {
"type": "section",
"text": {
"type": "mrkdwn",
"text": f"⚠️ *정책 적용 오류:*\n```{policy_message}```"
}
})
print(f"Sending Slack notification to {webhook_url[:30]}...")
encoded_data = json.dumps(slack_message).encode('utf-8')
response = http.request(
'POST',
webhook_url,
body=encoded_data,
headers={'Content-Type': 'application/json'}
)
print(f"Slack response status: {response.status}")
if response.status == 200:
print("Slack notification sent successfully")
return True
else:
print(f"Failed to send Slack notification. Status: {response.status}, Response: {response.data}")
return False
except Exception as e:
error_msg = f"Failed to send Slack notification: {str(e)}\n{traceback.format_exc()}"
print(error_msg)
return False
def lambda_handler(event, context):
print(f"Received event: {json.dumps(event)}")
try:
# 이벤트 구조 파싱 - 두 가지 형태 지원
# 1. EventBridge에서 직접 온 경우: event['detail']['eventMetadata']
# 2. 다른 Lambda에서 전달된 경우: event 최상위 레벨에 데이터
detail = event.get('detail', {})
event_metadata = detail.get('eventMetadata', {})
# EventBridge 형태인지 확인
if event_metadata:
access_key_id = event_metadata.get('publicKey', '').strip()
username = event_metadata.get('userName', '')
account_id = event.get('account', '')
else:
# 최상위 레벨에서 데이터 추출
access_key_id = event.get('accessKeyId', '').strip()
username = event.get('userName', '')
account_id = event.get('accountId', '')
print(f"Processing remediation for account: {account_id}, user: {username}, key: {access_key_id}")
if not access_key_id or not username:
raise ValueError(f"Invalid event data - username: {username}, access_key_id: {access_key_id}")
# enableAutoRemediation 플래그 확인 (있다면)
enable_auto_remediation = event.get('enableAutoRemediation', True)
if not enable_auto_remediation:
print("Auto-remediation is disabled. Skipping...")
return {
'statusCode': 200,
'body': {
'message': 'Auto-remediation is disabled',
'user': username,
'keyId': access_key_id,
'accountId': account_id
}
}
# Disable access key
print(f"Attempting to disable access key {access_key_id} for user {username}")
iam = boto3.client('iam')
iam.update_access_key(
UserName=username,
AccessKeyId=access_key_id,
Status='Inactive'
)
print(f"Access key {access_key_id} disabled successfully")
# Attach pre-created deny policy
policy_attached, policy_message = attach_existing_deny_policy(username)
# Send Slack notification
slack_sent = send_slack_notification(username, access_key_id, account_id, policy_attached, policy_message)
result = {
'statusCode': 200,
'body': {
'message': 'Remediation actions completed',
'user': username,
'keyId': access_key_id,
'accountId': account_id,
'keyStatus': 'INACTIVE',
'policyAttached': policy_attached,
'slackSent': slack_sent
}
}
print(f"Remediation result: {json.dumps(result)}")
return result
except Exception as e:
error_msg = f"Failed to complete remediation actions: {str(e)}\n{traceback.format_exc()}"
print(error_msg)
return {
'statusCode': 500,
'body': {
'error': str(e),
'message': 'Failed to complete remediation actions',
'traceback': traceback.format_exc()
}
}
Step Functions 과정에서 해당 Lambda가 동작할 경우 유출된 Access Key에 Deny 정책 추가 및 액세스 키 비활성화만 진행되는 것이 아니라 아래와 같이 Slack으로 알림을 받을 수 있습니다.
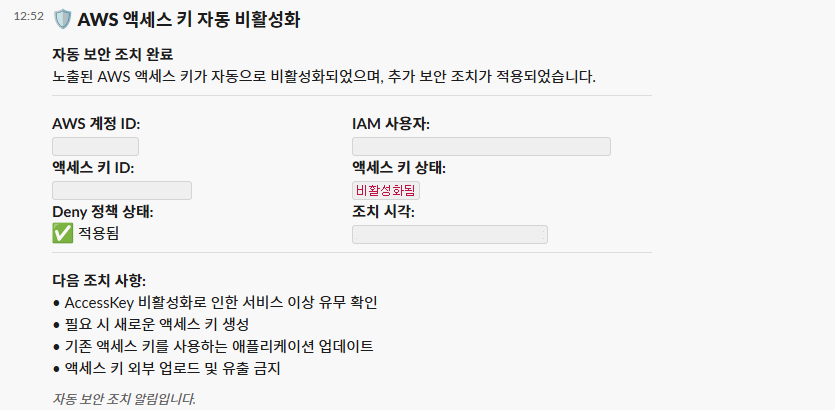
이 아키텍처는 다중 계정 환경으로도 확장이 가능합니다. AWS Organizations의 위임 관리자 계정에 중앙 집중식으로 배포하고 EventBridge의 크로스 계정 이벤트 전달을 활용하면 여러 AWS 계정의 보안 사고를 한 곳에서 관리할 수 있습니다.
Personal Comments
오늘 포스팅을 통해 AWS IAM AccessKey 유출 사고를 자동으로 탐지하고 대응하는 시스템을 구축하는 방법을 알아보았습니다.
이 시스템의 가장 큰 장점은 메일이 아닌 원하는 플랫폼의 WEBHOOK URL로 알림을 받아 빠르게 키 유출로부터 대응할 수 있고 특히 야간이나 휴일에 발생한 사고도 자동으로 대응할 수 있어 위험 부담을 크게 줄일 수 있다는 것입니다.
또한 Bedrock Agent를 활용한 AI 분석은 단순 로그 집계를 넘어 사고의 맥락을 이해하고 위험도를 평가하는 데 큰 도움이 됩니다. 또한 이를 통해 보안 문제 발생 시 분석 시간을 단축하고 단순 반복 작업에서 벗어나 더 전략적인 업무에 집중할 수 있습니다.
물론 이 포스팅을 통해 IAM AccessKey 유출에 대한 대응 방법이 있다는 것을 말하고자 하는 것이 아닙니다. 우리는 IAM AccessKey 사용을 지양하고 IAM Role을 적극적으로 사용할 필요가 있습니다. 다만, IAM AccessKey를 반드시 사용할 수 밖에 없는 상황이라는 게 결국 찾아온다면 이러한 대안을 미리 구성해둔다면 보안 위협으로부터 조금이나마 안전하게 서비스를 운영할 수 있을 것이라 생각됩니다.
이 글을 통해 AWS 환경에서 보안 자동화를 구현하는 데 도움이 되길 바랍니다.
긴 글 읽어주셔서 감사합니다.