
안녕하세요. MANVSCLOUD 김수현입니다.
얼마 전까지만 해도 우리는 인터넷 없이는 불편을 겪었던 시대에 살았습니다. 그러나 이제는 AI 기술 없이는 일상 생활과 직장에서 큰 불편함을 경험하게 되었습니다. AI는 다양한 영역에서 필수적으로 사용되고 있으며 최근에는 IT 관련 직무에서도 AI 역량이 필수 요소로 자리 잡고 있습니다.
또한 지난해 네이버 클라우드 유저 커뮤니티(NCUC) 연말 MeetUp에서 저는 관심 키워드로 Gen AI, Serverless, FinOps를 언급하며 2024년도에 집중 학습하겠다고 말했습니다.
이에 따라 6월 1일 ‘AI 막차 탑승: HyperCLOVA X 프로젝트 챌린지’를 기획 및 운영하게 되었고 이 활동을 통해 학습한 내용의 일부를 공유드리고자 합니다.
HyperCLOVA X와 CLOVA Studio
네이버 클라우드를 이용하여 AI 서비스를 만들기 전에 HyperCLOVA X와 CLOVA Studio에 대해 먼저 알아야합니다.
단, 이미 제 블로그에서 HyperCLOVA X에 대해 다룬 적이 있기때문에 길게 설명하지 않겠습니다.
간단하게 설명드리자면 HyperCLOVA X는 네이버의 최신 대형 언어 모델로 특히 한국어 처리 능력에서 뛰어난 성능을 자랑합니다. 이 모델은 기존 HyperCLOVA를 한 단계 업그레이드한 버전이며 뛰어난 이해력과 응답 능력을 보여 줍니다. 사용자가 이러한 고급 언어 모델을 활용하여 맞춤형 AI 서비스를 개발할 수 있도록 돕는 개발 도구가 바로 CLOVA Studio입니다. CLOVA Studio는 튜닝, 임베딩, 스킬 트레이너와 같은 기능을 제공하여 사용자의 특정 목적에 맞춰 서비스를 세밀하게 조정할 수 있게 해줍니다. 이를 통해 사용자는 자신만의 전문적인 AI 서비스를 쉽게 구축할 수 있습니다.
RAG(Retrieval-Augmented Generation)
추가로 이 블로그의 주제가 ‘네이버 클라우드 서비스를 활용한 AI 아키텍처 (With RAG Pipeline)’이므로 RAG에 대해서도 조금 설명하고자 합니다. 또한 Vector Database와 LangChain에 대해서도 조금 덧붙여보았습니다.
- RAG(검색 증강 생성)이란?
: RAG는 신뢰할 수 있는 외부 데이터 세트 또는 지식 기반 데이터베이스를 참조하는 프로세스로 기존 대규모 언어 모델(LLM)을 수정하지 않고 결합하여 정확하고 관련성 높은 정보를 기반으로 텍스트를 생성하기 위해 검색 기능을 이용하는 기술입니다. 이 방식은 관련 정보를 실시간으로 검색하고 이를 기반으로 응답을 생성하여, 정보의 최신성과 관련성을 보장할 수 있게 되기에 실시간 정보 반영이 중요한 챗봇, 질의응답 시스템 등에서 유용하게 사용할 수 있습니다.
- RAG를 위한 구성 요소
- Data Preprocessing (Extract/Parse, Chunk)
- 문맥을 이해한 문단 분리: 문서에서 의미 있는 단위로 내용을 분할합니다.
- Document Loading: 데이터베이스에서 문서를 로드합니다.
- Text Segmentation, Summarization: 텍스트를 세분화하고 요약하여 중요 정보를 추출합니다.
- Embedding
- 유사성을 가지고 있는 Vector 제공: 문서 내용을 벡터 형태로 표현하여 유사 문서 검색을 용이하게 합니다.
- 고차원의 벡터를 통해 세밀한 데이터 제공: 복잡한 데이터 특성을 정교하게 매핑합니다.
- LLM을 이용한 데이터 재생성: 언어 모델을 사용해 데이터를 다시 해석하고 생성 과정에 통합합니다.
- Vector Database (Index)
- Vector 기반 데이터 저장: 생성된 벡터들을 데이터베이스에 저장합니다.
- 유사성 검색: 저장된 벡터들 중 유사한 항목을 빠르게 검색합니다.
- 대규모 데이터 처리: 방대한 양의 데이터를 효율적으로 관리하고 검색할 수 있습니다.
- Data Preprocessing (Extract/Parse, Chunk)
- RAG(Retrieval-Augmented Generation)와 Fine-Tuning의 차이
: 둘 다 인공지능 모델을 특정 작업이나 요구에 맞게 최적화하는 방법론이지만 차이가 있습니다.
1) RAG는 실시간 정보 검색과 통합에 초점을 맞춘 반면 Fine Tuning은 특정 도메인이나 작업에 대한 모델의 전문성을 강화하는 데 초점을 맞춤
2) RAG는 동적으로 변화하는 외부 데이터 소스에서 정보를 검색하여 응답을 생성하는 반면 Fine Tuning은 주어진 특정 데이터셋을 사용하여 모델을 재학습함
3) RAG는 정보 검색이 중요한 질의응답 시스템이나 챗봇 등에서 유용하며 Fine Tuning은 특정 분야의 전문 지식을 필요로 하는 응용 프로그램에서 유용함
- RAG (Retrieval-Augmented Generation)
: RAG는 검색 기능을 이용하여 관련 정보를 찾아내고 그 정보를 기반으로 응답을 생성하는 방식입니다. RAG는 특히 데이터베이스나 문서 집합에서 실시간으로 필요한 정보를 검색하여 이를 통해 보다 정확하고 상세한 답변을 생성할 수 있게 도와줍니다. RAG의 주된 목적은 정보의 정확성과 신뢰성을 높이는 것이며 변화하는 데이터에 대응하는 능력을 강화하는 것입니다. - Fine-Tuning
: Fine Tuning은 기존에 사전 학습된 모델(예: GPT, BERT 등)을 특정 작업이나 도메인에 맞게 추가적으로 학습시키는 과정입니다. 이 방식은 사전 학습된 모델이 가진 일반적인 언어 이해 능력을 바탕으로, 특정 데이터셋을 사용하여 모델을 더욱 특화시키는 것을 목적으로 합니다. 예를 들어, 법률, 의료, 특정 기술 분야 등 특정 주제에 대한 모델의 성능을 향상시킬 수 있습니다.
- RAG (Retrieval-Augmented Generation)
- Embedding의 역할과 중요성
- 정의 : Embedding은 텍스트나 객체를 수치화된 벡터로 변환하는 과정을 말합니다. 이 과정을 통해 생성된 벡터는 단어나 문장의 의미를 수치적으로 표현하며 이러한 벡터들은 유사도 측정 및 머신러닝 모델의 입력으로 활용됩니다. 이를 통해 단어, 문장, 문서 간의 유사도를 계산하고 의미적, 문법적 정보를 함축적으로 나타낼 수 있습니다.
- 모델 예시 :
- Word2Vec, GloVe: 단어를 벡터 공간에 매핑하여 단어 간 유사도를 계산합니다.
- BERT Embeddings: 문장 전체의 문맥을 반영한 벡터를 생성하여 더 정교한 의미 분석을 가능하게 합니다.
- 정의 : Embedding은 텍스트나 객체를 수치화된 벡터로 변환하는 과정을 말합니다. 이 과정을 통해 생성된 벡터는 단어나 문장의 의미를 수치적으로 표현하며 이러한 벡터들은 유사도 측정 및 머신러닝 모델의 입력으로 활용됩니다. 이를 통해 단어, 문장, 문서 간의 유사도를 계산하고 의미적, 문법적 정보를 함축적으로 나타낼 수 있습니다.
- Vector Database의 개념과 예
- 정의 : Vector Database는 벡터 형태로 저장된 데이터를 효과적으로 관리하고 검색할 수 있는 데이터베이스입니다. 생성된 벡터들을 효율적으로 저장하고, 유사 벡터 검색을 위한 색인 기능을 제공합니다. 이는 유사도 기반 검색을 가능하게 하여 RAG 시스템의 성능을 극대화하기 때문에 검색 모듈에 중요한 역할을 합니다.
- 예시 :
- Faiss : 고차원 벡터의 유사성 검색에 최적화된 라이브러리로, 대규모 벡터 검색을 빠르게 수행할 수 있습니다.
- Elasticsearch : 텍스트와 벡터 데이터 모두를 처리할 수 있는 유연한 검색 엔진으로, 다양한 형태의 데이터 검색을 지원합니다.
- PostgreSQL(+PGVector) : PostgreSQL은 전통적인 관계형 데이터베이스 관리 시스템입니다. PGVector 확장을 추가함으로써 PostgreSQL은 벡터 데이터의 저장 및 유사도 검색 기능을 제공할 수 있습니다.
- 그 외 (milvus, usearch, pinecone, Qdrant, Chroma, Weaviate 등)
- 정의 : Vector Database는 벡터 형태로 저장된 데이터를 효과적으로 관리하고 검색할 수 있는 데이터베이스입니다. 생성된 벡터들을 효율적으로 저장하고, 유사 벡터 검색을 위한 색인 기능을 제공합니다. 이는 유사도 기반 검색을 가능하게 하여 RAG 시스템의 성능을 극대화하기 때문에 검색 모듈에 중요한 역할을 합니다.
- LangChain이란?
: LangChain은 오픈 소스 프레임워크로 대규모 언어 모델을 활용하여 다양한 AI 기반 애플리케이션을 개발할 수 있도록 지원합니다. 이를 통해 개발자들은 검색 증강 생성(RAG)과 같은 복잡한 기능을 쉽게 구현할 수 있으며 데이터 소스의 통합 및 프롬프트 세분화를 추상화하여 AI 개발을 간소화합니다. 또 LangChain은 챗봇, 질의 응답 시스템, 콘텐츠 생성, 요약 등 다양한 용도로 활용 가능합니다.
Chunking의 중요성
네이버 클라우드에서는 Vector Database를 생성한다면 Server를 생성하고 다양한 Vector DB를 구성하거나 관리형 서비스로 Cloud DB for PostgreSQL과 Search Engine Service를 사용할 수 있습니다. 참고로 Cloud DB for MongoDB의 경우 Atlas와 연동이 불가하기 떄문에 Atlas Vector Search를 지원하지 않습니다.
우선 ‘AI 막차 탑승: HyperCLOVA X 프로젝트 챌린지’를 통해 저는 설치형 Milvus 및 네이버 클라우드의 Search Engine Service(ElasticSearch)를 이용하여 RAG Pipeline을 구현해보았는데요.
RAG(Retrieval-Augmented Generation)를 구축해보면서 RAG에 대해 많은 연구를 하면서 RAG 시스템의 사용이 모든 시나리오에 적합한 것은 아니라는 것을 깨달았습니다.
RAG를 도입하여 Hallucination을 줄이고 답변의 정확도를 높이려 했으나 데이터의 잘못된 처리가 답변의 품질을 저하시킬 수 있다는 것을 알게 됐는데요.
특히 URL이나 코드 스니펫 등의 경우 RAG와 같은 시스템이 이를 올바르게 처리하지 못하여 문자 단위로 쪼개거나 잘못된 형태로 인식할 수 있었고 이는 오히려 Hallucination을 만들어내는 결과를 초래했습니다. 자연어 처리 시스템에서는 데이터를 문단, 문장, 문자 단위로 분할하여 사용하는데 정밀한 처리를 하고자 문자 단위로 분할을 했더니 완전 엉뚱한 URL을 제공받았습니다.
문단 단위는 주제가 명확하고 넓은 문맥이 필요한 정보 처리에 적합하고 문자 단위는 텍스트의 구조적 특성을 더욱 세밀하게 분석할 필요가 있을 때 혹은 언어적 세부사항이 중요할 때 선택적으로 사용될 필요가 있어보였습다.
따라서 RAG 시스템의 경우 문서의 질이 보장되는 것도 중요하지만 이 문서를 어떻게 Chunking 할 지에 대한 고민도 매우 중요한 포인트였는데요.
문서의 Chunking 단위를 조절하여 검색 엔진의 정확도를 높이고 불필요한 정보를 배제함으로써 어떻게 처리 성능을 향상시킬지에 대한 연구를 추가로 해봐야겠다고 생각했습니다. Chunking 단위가 너무 크면 관련 없는 정보가 포함될 수 있고 너무 작으면 문맥이 누락될 수 있으므로 적절한 균형을 찾는 것이 중요할 것입니다.
또한 Fine-Tuning은 RAG 시스템의 성능을 개선하는데 큰 도움이 될 수 있기 때문에 Tuning과 RAG Pipeline을 적절히 섞어 사용하여 어떤 결과의 차이가 있는지 추가 학습이 필요할 것입니다.
네이버 클라우드 서비스를 활용한 AI 서비스 아키텍처 연구
본격적으로 네이버 클라우드 서비스를 활용하여 AI 서비스 아키텍처를 구현한다면 어떤 서비스들을 사용할 수 있을지 아래 예시와 Flow 및 각 사용된 서비스별 역할을 설명해보도록 하겠습니다.
- 예시 – 의학, 법률, 금융 등 특정 전문 분야에 대해 PDF 파일을 기반으로 분석 및 답변을 제공해주는 서비스
- 서버 관리가 필요하지 않은 Serverless Architecture
- 질문 및 답변 데이터를 재가공하여 Fine Tuning하거나 추가적인 목적에 활용
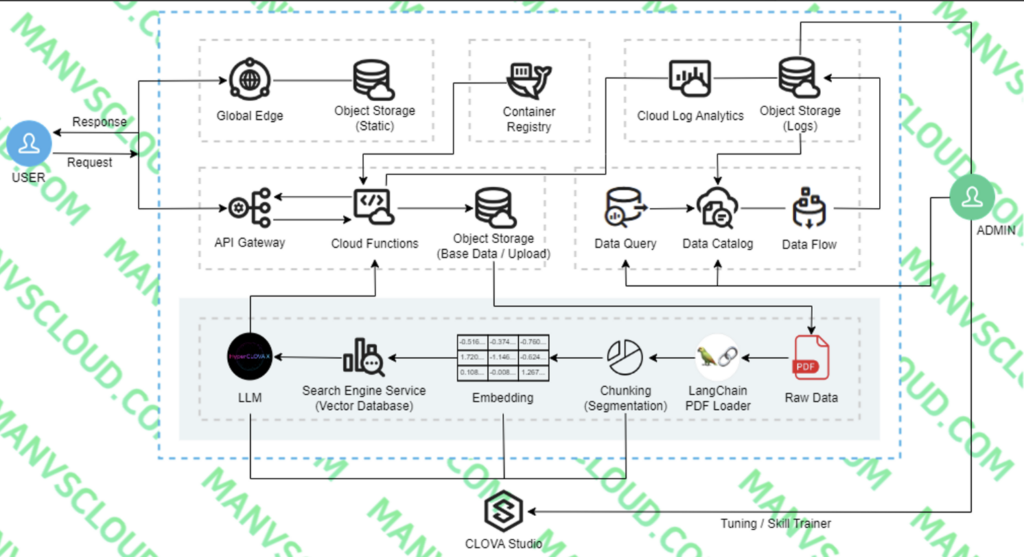
- Flow 설명
- Cloud Functions Action으로 RAG Pipeline을 동작시켜 기본 Raw Data를 Chunking, Embedding하여 Vector Database에 저장시킴.
- Client는 웹(서비스)에 접속 (Object Storage에 저장된 정적 페이지는 Global Edge에 캐싱되어 보다 빠르게 화면이 보여짐)
- PDF 파일 업로드 및 질문 시 API Gateway에 연결된 Cloud Functions Action에 요청되고 PDF 파일이 Object Storage에 업로드되고, 사용자 질문 + PDF(Summarization(요약)) 내용이 질문됨.
- 사용자의 질문을 먼저 Vector로 변환하고 질문 Vector를 사용하여 Vector Database에서 가장 유사한 문서를 Top K개만큼 검색함. 그 이후 검색된 각 문서는 검색 점수(_score)를 기반으로 그 관련성을 평가함. 마지막으로 LLM을 통해 이 정보를 바탕으로 사용자의 질문에 대한 답변 생성하여 제공
- 질문 및 답변 내용은 Cloud Log Analytics에 저장되고 저장된 로그는 Object Storage로 Export됨.
- Data Flow를 통해 데이터를 가공하고 재사용.
- 서비스별 역할
- Global Edge : 정적 파일에 대해 캐싱 목적으로 사용할 CDN 서비스다.
- Ojbect Storage(Static) : vue.js 등을 이용해서 html, css, javascript로 이루어진 정적 파일들을 Obejct Storage에 업로드하고 정적 호스팅을 활용할 수 있다. (이 부분은 Source Commit, Source Build 등 네이버 클라우드의 CI/CD 서비스를 활용하여 편하게 관리할 수도 있다.)
- API Gateway : Cloud Functions의 Action와 연동해서 외부에서 호출 가능하도록 할 것이다.
- Cloud Functions : 실제 Backend 역할을 하는 부분이다. RAG Pipeline이 동작하려면 다소 시간이 소요되고 Action 하나에 용량 제한이 있기때문에 Action은 여러개로 나눈다.
- RAG Pipeline Action → Client가 질문할 때마다 매번 기존 Raw Data까지 읽고 Chunking, Embedding, Vector Database에 저장하는 과정까지 거칠 필요는 없다. 따로 분리해서 Base Data가 추가될 때 별도로 동작시켜 Vector Database를 업데이트 하자.(사용자 질문에 대한 RAG Pipeline은 Response Action에서 진행)
- PDF File Upload Action → 이 Action은 있어도 되고, 없어도 된다. 위 아키텍처에서는 PDF를 Object Storage에 저장하는 용도이며, PDF 파일의 내용을 사용자 Query에 포함 시킬 수 있을 것이다. PDF 파일 내용이 길 수 있으니 사용자 Query에 포함 시키기 전에 CLOVA Studio의 Summarization(요약) API를 활용하는 방법을 활용할 수 있다.
- Response Action → 실제 Client가 웹에서 “CLOVA Studio에서 튜닝을 하는 방법을 알려줘”라고 질문을 한다면 이미 RAG Pipeline을 통해 저장했던 Vector Database의 값을 조회하고 LLM을 거쳐 답을 제공한다.
- Container Registry : Cloud Functions은 모든 패키지를 제공하지 않기 때문에 필요한 패키지가 있을 경우 .zip로 압축해서 업로드 하거나 Container Registry 이미지(Docker)를 이용할 필요가 있다. Container Registry 서비스를 이용하여 쉽게 Docker Image를 Push, Pull하고 쉽게 관리할 수 있다.
- Ojbect Storage(Base Data / Upload) : RAG Pipeline에 필요한 기본 Raw Data가 있는 Obejct Storage와 사용자가 질문 시 파일을 Upload 할 Obejct Storage
- CLOVA Studio : Chunking(Segmentation), Embedding, Summarization, Tuning, HyperCLOVA X LLM 등 활용
- Search Engine Service : Vector Database용도 (Cloud DB for PostgreSQL(pgvector)로 대체 가능)
- Cloud Log Analytics : Cloud Functions의 Action 로그 및 관리, Object Storage로 Export 할 수 있다. 즉, 질문과 답변을 관리하고 Object Storage로 Export할 목적이다.
- Object Storage(Logs) : 질문과 답변 저장 및 재가공된 데이터가 저장되는 Obejct Storage, 재가공된 데이터로 Tuning을 진행하거나 다른 곳에 활용 가능
- Data Query : 대규모 정형/비정형 데이터를 쉽게 분석하기 위한 대화형 쿼리 서비스
- Data Catalog : 데이터 저장소로 사용되며, Data Flow 사용을 위해 필수
- Data Flow : 대규모 데이터 추출, 변환, 적재 용도, 변환된 데이터는 Object Storage(Logs)에 저장
참고로 Search Engine Service의 Elasticsearch 빌드는 OSS (Open Source Software) 버전입니다. OSS 버전은 일부 고급 기능이 제거된 상태로 제공되므로 X-Pack 플러그인이 제거되어 있다는 점을 참고할 필요가 있습니다. (보안, 모니터링, 머신러닝 및 벡터 검색을 위한 “dense_vector” 데이터 타입 등의 기능 없음)
Personal Comments
본 글에서는 네이버 클라우드를 활용한 AI 서비스 아키텍처의 설계 및 구현 과정을 살펴보았습니다. 이러한 기술이 어떻게 실제 업무에 적용될 수 있는지 그리고 AI를 통해 어떤 효율성과 혁신을 이룰 수 있는지 고민을 하고 구현을 해봐야겠습니다.
‘AI 막차 탑승: HyperCLOVA X 프로젝트 챌린지’가 7월 초에 마무리되는데 해당 챌린지가 끝난 후 추가로 공유드릴 수 있는 부분이 있다면 블로그로 포스팅하거나 Meetup 자리에서 공유드릴 수 있도록 하겠습니다.
긴 글 읽어주셔서 감사합니다.