
안녕하세요. MANVSCLOUD 김수현입니다.
지난 포스트 “[NCLOUD] 네이버 클라우드에서 비용 이상 탐지를 추구하면 안 되는 걸까 #1″에서는 네이버 클라우드 환경에서 비용 이상 탐지 시스템을 구축하는 방법에 대해 살펴보았습니다. 이번 글에서는 지난 과정에서 수집한 데이터와 생성된 예측 데이터를 조금 더 응용하여 비용 관리의 핵심인 가시성과 분석에 초점을 맞추고자 합니다.
FinOps의 핵심 원칙 중 두 가지가 오늘 우리의 주제와 특히 밀접한 관련이 있습니다.
- “FinOps data should be accessible and timely”
- “Take advantage of the variable cost model of the cloud”
이 두 원칙은 우리가 왜 지속적이고 효과적인 비용 관리 시스템을 구축해야 하는지를 잘 설명해줍니다.
먼저 “접근 가능하고 시기적절한 데이터”는 비용 관리의 기본입니다. 클라우드 지출 및 예측에 대한 통찰력을 제공하기 위해서는 일상적이고 간결한 보고서가 필요합니다. 이는 단순히 데이터를 수집하는 것을 넘어 그 데이터를 조직의 모든 레벨에서 쉽게 이해하고 활용할 수 있도록 만드는 것을 의미합니다. 실시간 가시성은 클라우드 활용도를 자연스럽게 향상시키며 빠른 피드백 루프는 더 효율적인 의사결정으로 이어집니다.
그리고 “클라우드의 가변 비용 모델 활용”은 클라우드의 특성을 이해하고 이를 이점으로 활용하는 것입니다. 클라우드 지출은 본질적으로 가변적이므로 변동성있는 비용을 관리하고 모니터링할 수 있는 프로세스가 필요합니다. 적시에 예측, 계획 및 정적인 장기 계획보다는 민첩하고 반복적인 계획을 선호해야 합니다.
제 블로그에서는 네이버 클라우드 서비스에 대한 기술도 다루지만 비용 관리에 대한 부분도 많이 다루고 있습니다. 비용 API와 Cloud Insight를 활용하여 비용 모니터링과 알림을 받는 방법부터 예측 모델을 활용하여 비용 이상 탐지 그리고 오늘의 주제는 아래와 같습니다.
- Grafana를 활용한 비용 모니터링 대시보드 구현
- 생성형 AI를 활용한 자동화된 비용 보고서 생성
- 대시보드 및 보고서 Slack 전달 자동화
비용 모니터링과 분석을 소홀히 하다 보면 정말로 예상치 못한 큰 비용이 발생하여 파산핑을 피할 수 없을 것입니다. 오늘 포스팅에서는 단순한 비용 추적을 넘어 데이터를 기반으로 한 인사이트를 얻고 더 나은 의사결정을 내릴 수 있는 방법을 탐구할 것이며 수집된 데이터가 제한적이라 과거 7일간의 실제 데이터와 향후 7일간의 예측 데이터를 활용하여 위 시스템을 구현한 경험을 말하고자 합니다.
Grafana를 활용한 비용 모니터링 대시보드 구현 및 지표 Slack 전달
“지난 포스팅과 마찬가지로 이번에도 전체적인 내용이 방대하여 전체 코드를 공유하지 않습니다. 따라서 이 글에서 제시하는 아이디어와 프로세스를 이해하신 후 이를 응용하여 직접 구현해보시는 것을 권장드립니다.”
먼저 왜 Grafana를 선택했는지에 대해 설명드리겠습니다. InfluxDB도 자체적으로 대시보드를 생성하고 볼 수 있는 기능을 제공합니다. 하지만 우리의 목적인 실제 데이터와 예측 데이터를 함께 표시하는 데 있어서는 한계가 있었습니다. 특히 두 데이터 세트가 겹칠 경우 InfluxDB의 대시보드에서는 이를 명확히 구분하여 보기 어려운 점이 있었습니다. 이러한 이유로 우리는 더 유연하고 커스터마이징이 용이한 Grafana를 선택하게 되었습니다.
이제 Grafana를 활용하여 직관적이고 실시간으로 업데이트되는 비용 모니터링 대시보드를 구현하는 과정을 살펴보겠습니다.
- Grafana 대시보드 구현
먼저 Grafana는 아래와 같이 간단하게 설치 및 실행할 수 있습니다.
apt install -y apt-transport-https software-properties-common wget mkdir -p /etc/apt/keyrings/ wget -q -O - https://apt.grafana.com/gpg.key | gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list apt update apt install grafana grafana-server -v systemctl enable grafana-server systemctl start grafana-server
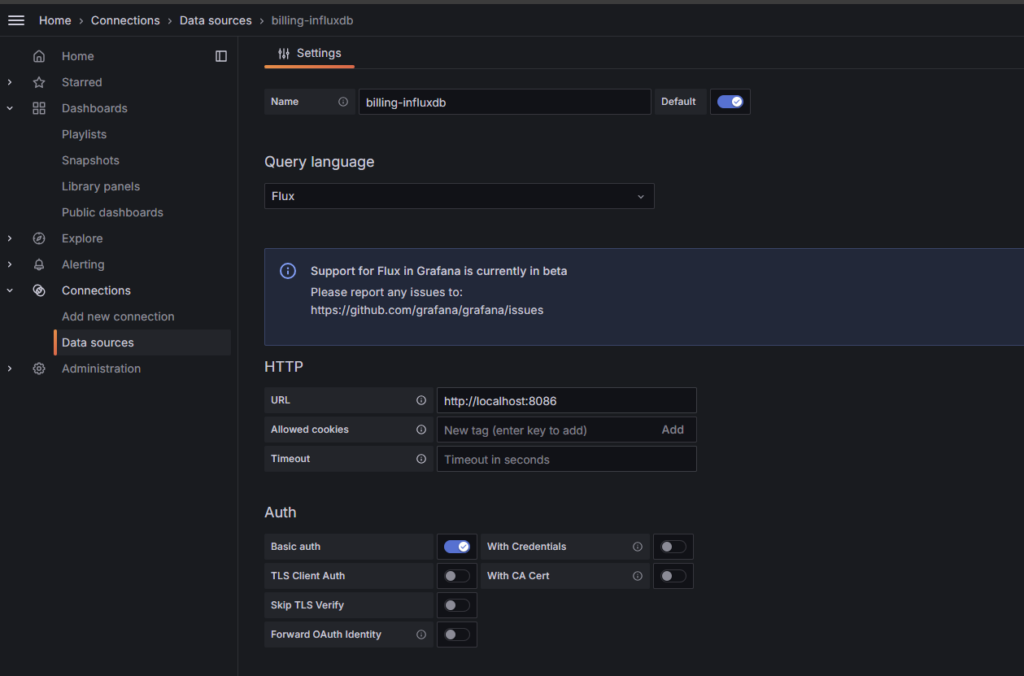
Grafana에서 InfluxDB를 데이터 소스로 추가해야합니다.
이전 포스트에서 구축한 InfluxDB에는 네이버 클라우드의 비용 데이터가 저장되어 있습니다.
- 웹 브라우저에서 설치한 Grafana를 켠 뒤 로그인합니다.
- Grafana 설정에서 ‘Data Sources’로 이동하여 InfluxDB를 추가합니다.
- InfluxDB의 URL, 데이터베이스 이름, 사용자 이름, 비밀번호 등을 입력합니다.
다음으로 새로운 대시보드를 생성하고 패널을 추가합니다.
- ‘New Dashboard’를 클릭하고 ‘Add visualization’을 선택합니다.
- 데이터 소스로 위에서 추가했던 InfluxDB를 선택합니다.
- InfluxDB 쿼리를 작성하여 원하는 비용 데이터를 가져옵니다.
from(bucket:"manvscloud")
|> range(start: -7d, stop: 7d)
|> filter(fn: (r) => r._measurement == "ncloud_billing" or r._measurement == "ncloud_billing_forecast")
|> filter(fn: (r) => r.service == "${service}")
|> filter(fn: (r) => r._field == "use_amount" or r._field == "predicted_amount")
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> yield(name: "result")
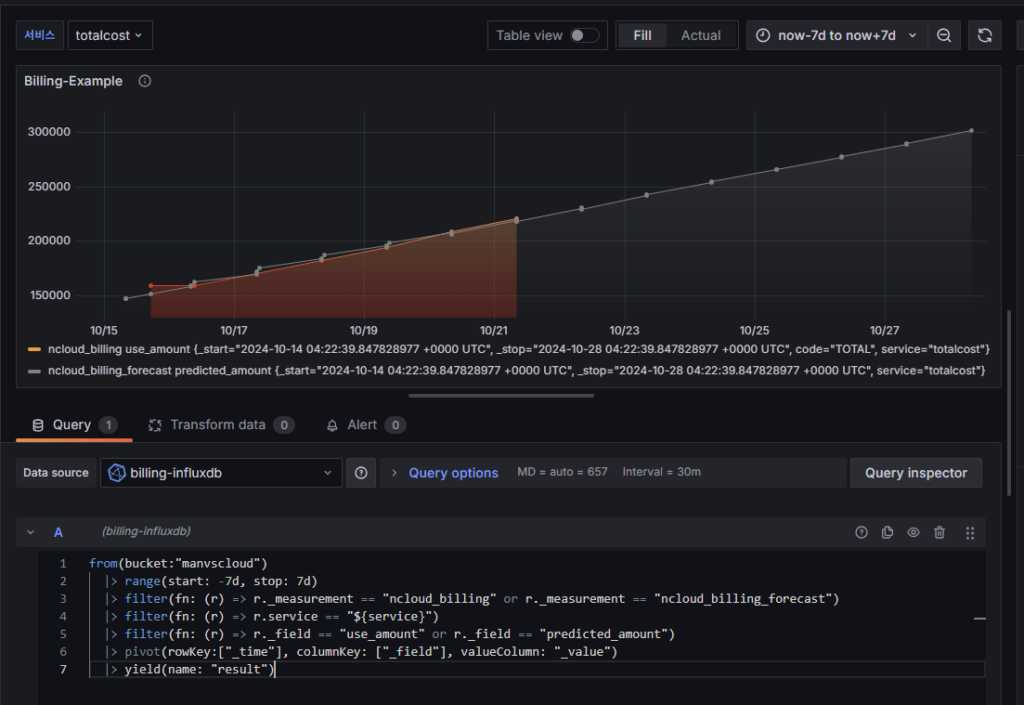
기간은 now-7d to now+7d로 설정했습니다. 만약 데이터가 부족하거나 많다면 원하는 기간으로 수정해주면 되겠습니다.
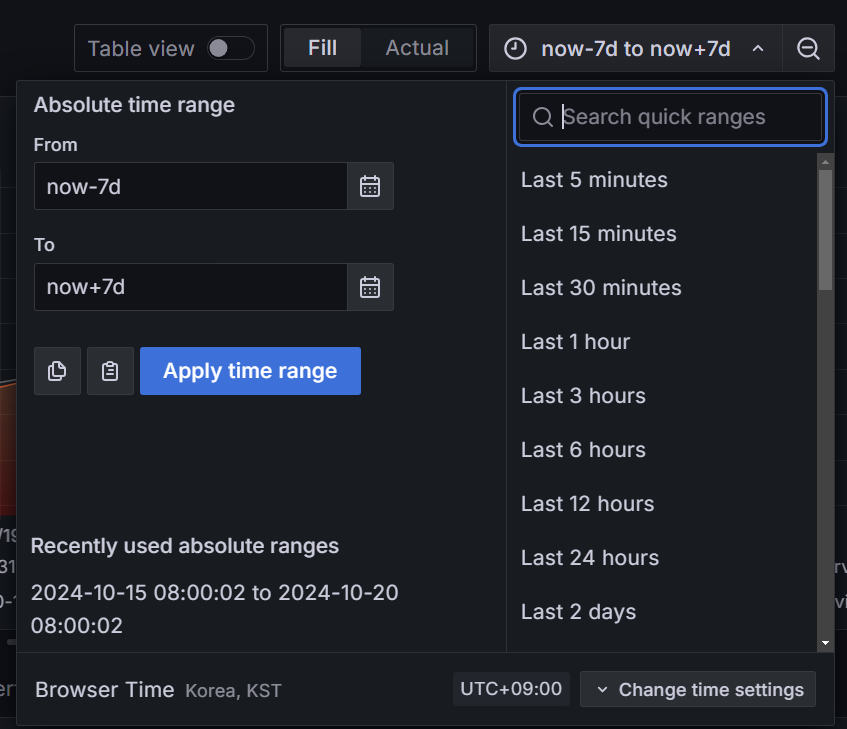
또한 조금 더 실제 비용과 예측 비용을 보기 쉽도록 구분해주기 위해서는 아래와 같이 필드에 따라 색상이나 스타일 등을 조정해줄 필요가 있습니다.
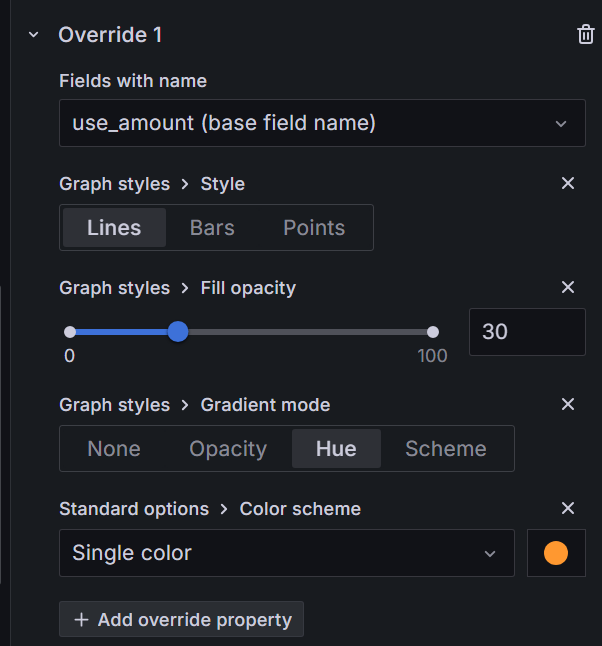
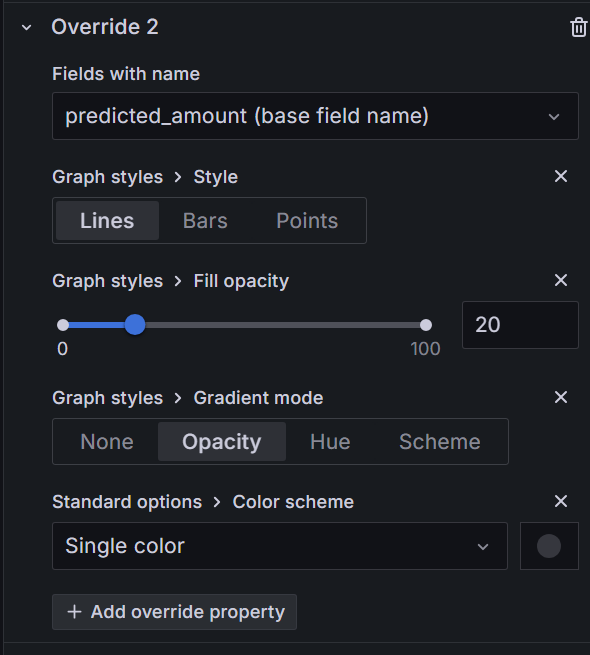
위 과정과 같이 InfluxDB에서 데이터를 쿼리하여 다양한 형태의 그래프와 차트를 생성할 수 있습니다. 주요 패널로는 다음과 같은 것들을 추가할 수 있습니다.
– 일별 총 비용 추이 그래프 (실제 데이터와 예측 데이터 비교)
– 서비스별 비용 분포 파이 차트
– 주요 비용 발생 서비스 Top 5 테이블
– 전월 대비 비용 증감 게이지
예시 #1) Grafana 서비스별 비용 대시보드(Server(VPC))
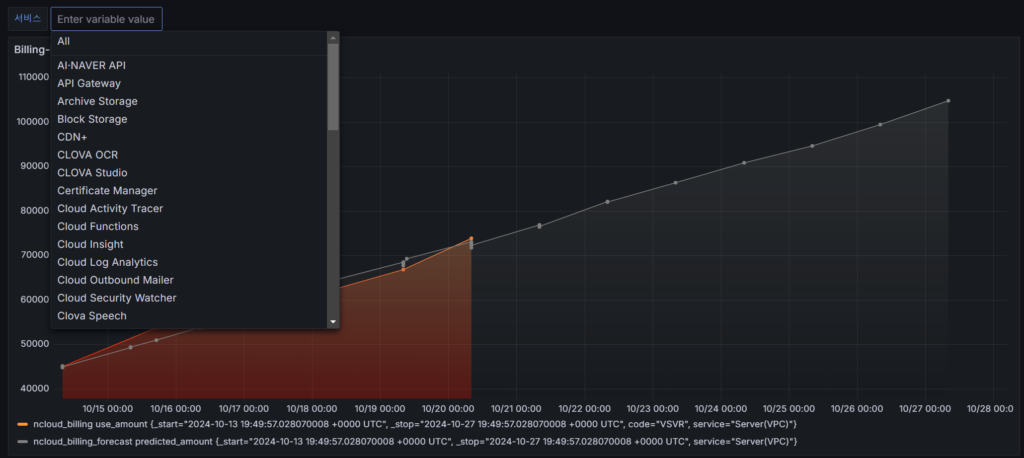
예시 #2) 현재 서비스별 사용한 비용
from(bucket:"manvscloud") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "ncloud_billing") |> filter(fn: (r) => r._field == "use_amount") |> filter(fn: (r) => r.service != "totalcost") |> last() |> group() |> group(columns: ["service"]) |> filter(fn: (r) => r._value > 0) // _value가 0보다 큰 경우만 포함 |> limit(n: 50) |> sort(columns: ["_value"], desc: true) |> yield(name: "result")
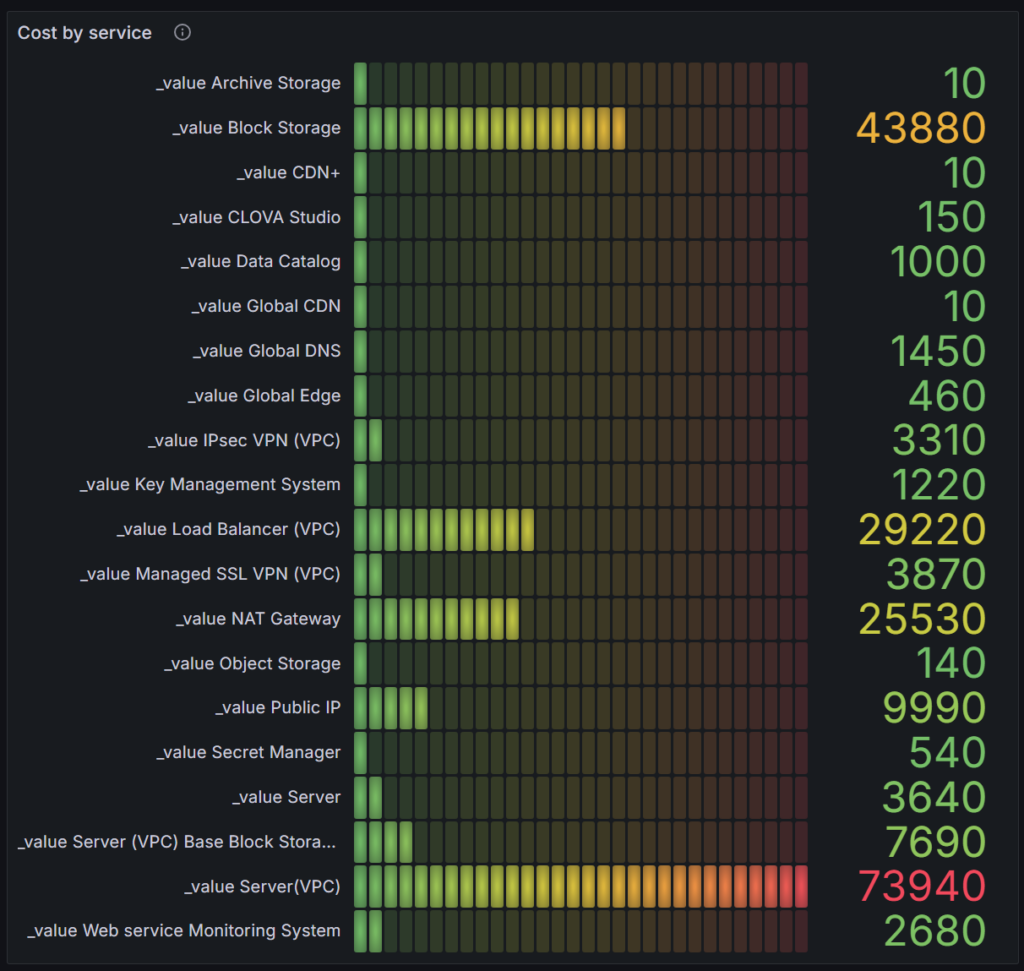
위 예시들과 같이 대시보드로 서비스별 비용을 확인하고자 한다면 아래와 같이 Dashboard의 Settings에서 Variables를 설정해주시기 바랍니다.
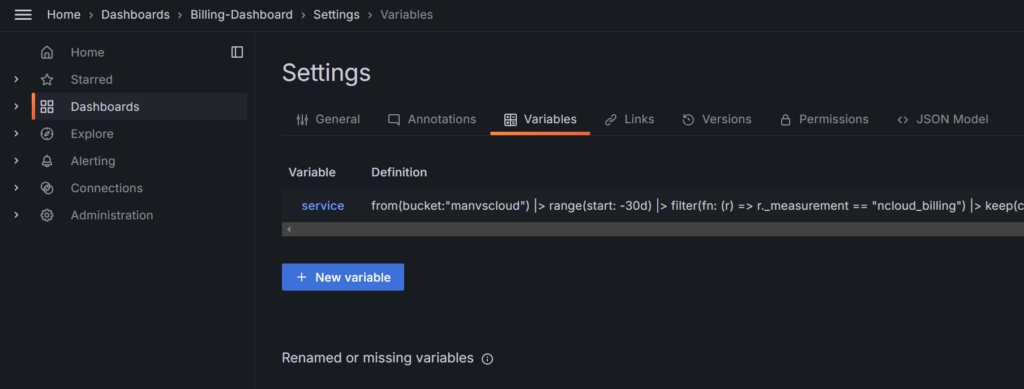
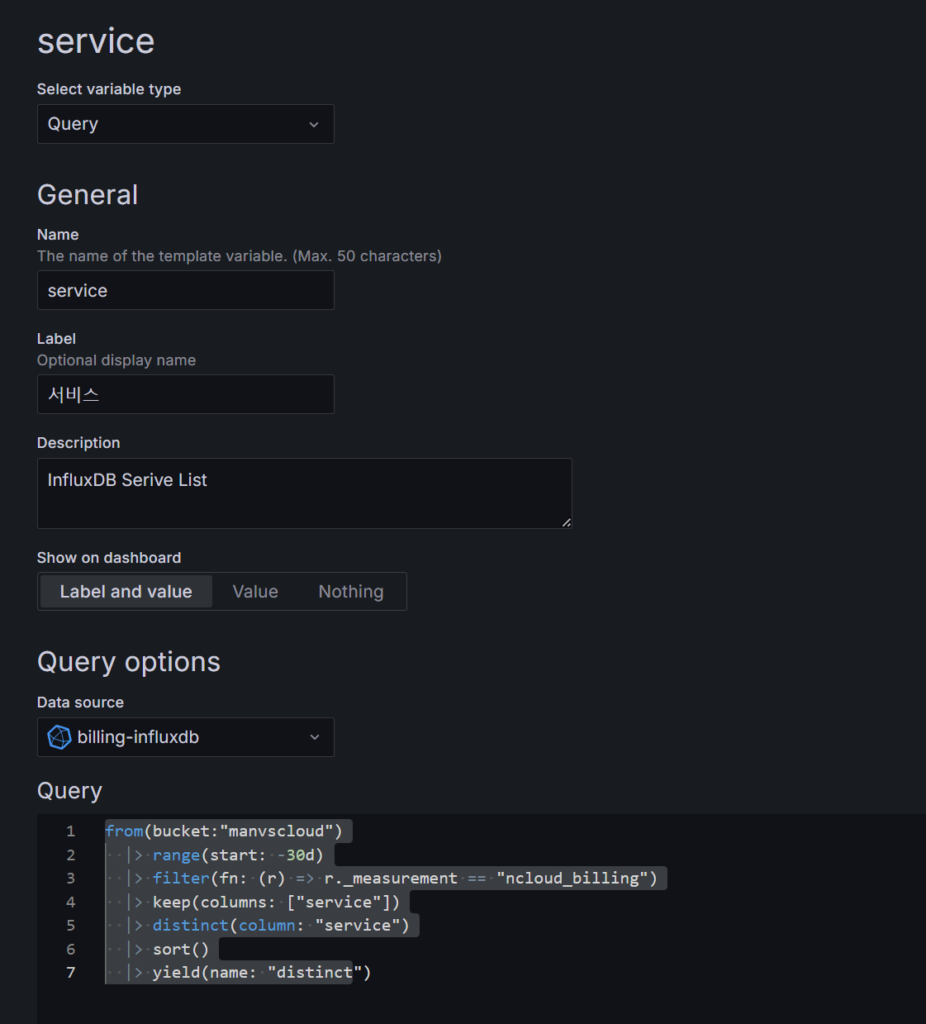
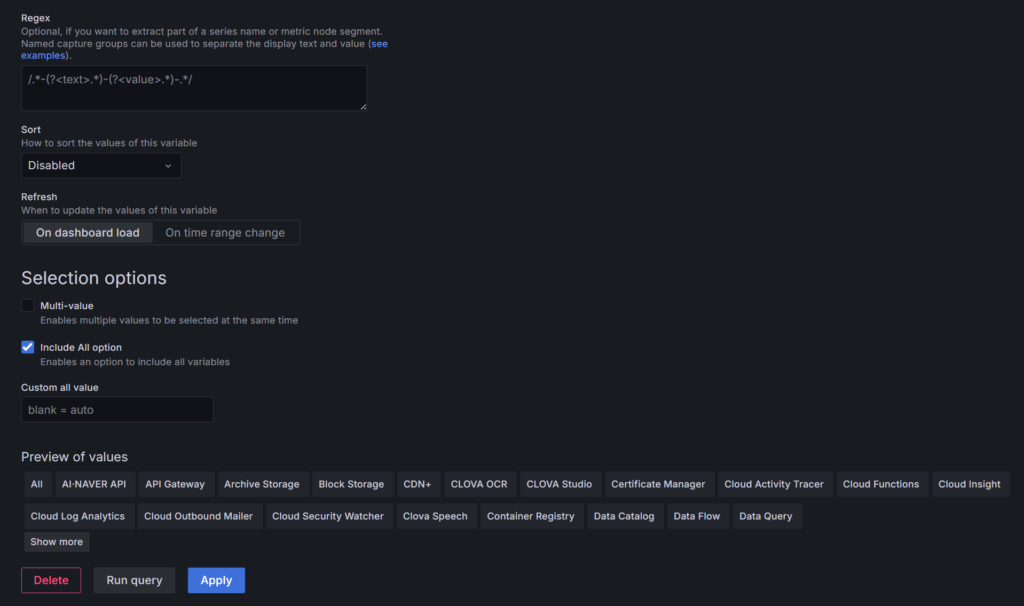
또한 각 패널은 사용자의 필요에 따라 커스터마이징이 가능하며 시간 범위도 자유롭게 조정할 수 있습니다. Grafana의 강점은 바로 이러한 유연성에 있습니다. 실제 데이터와 예측 데이터를 명확히 구분하여 표시할 수 있어 비용 트렌드를 한눈에 파악할 수 있습니다.
- 대시보드 지표의 Slack 전달 자동화
구현된 대시보드의 주요 지표를 매일 자동으로 Slack에 전달하기 위해 우리는 grafana-image-renderer와 쉘 스크립트를 활용하는 방식을 선택했습니다. 이 방식은 단순히 텍스트 데이터만을 전송하는 것이 아니라 시각화된 대시보드 이미지를 직접 Slack으로 전송할 수 있어 더욱 직관적이고 효과적입니다.
먼저 grafana-image-renderer를 설치하고 실행합니다.
이는 Grafana 대시보드를 이미지로 렌더링하는 역할을 합니다.
docker run -d --name=grafana-image-renderer -p 8081:8081 grafana/grafana-image-renderer
- /etc/grafana/grafana.ini
[rendering] server_url = http://localhost:8081/render callback_url = http://10.0.14.6:3000/
/etc/grafana/grafana.ini 파일의 rendering 부분에 위와 같이 server_url과 callback_url을 추가해줘야합니다. callback_url의 10.0.14.6 부분은 본인의 서버 IP로 변경해주시기 바랍니다.
다음으로 대시보드 이미지를 다운로드하고 Slack으로 전송하는 쉘 스크립트를 작성합니다.
아래는 그 예시입니다.
#!/bin/bash
# 날짜 가져오기 (YYYY-MM-DD 형식)
current_date=$(date +"%Y-%m-%d")
# Image Download
curl -H "Authorization: Bearer YOUR_GRAFANA_API_KEY" -o dashboard.png "http://localhost:3000/render/d/YOUR_DASHBOARD_ID/billing-dashboard?orgId=1&viewPanel=1&&kiosk&width=1000&height=500"
# Slack으로 이미지 파일 업로드
curl -F file=@dashboard.png \
-F "initial_comment=[$current_date] 네이버 클라우드 비용 대시보드 보고서" \
-F channels=YOUR_SLACK_CHANNEL_ID \
-H "Authorization: Bearer YOUR_SLACK_BOT_TOKEN" \
https://slack.com/api/files.upload
- Bearer YOUR_GRAFANA_API_KEY 부분은 Administration – Users and access – Service account에서 서비스 계정을 생성하고 Tokens을 발행하여 사용합니다.
- YOUR_DASHBOARD_ID 및 orgId, viewPanel는 전송하고자 하는 Grafana의 대시보드에 접속해보면 웹 브라우저 URL에서 확인하실 수 있습니다.
- YOUR_SLACK_CHANNEL_ID는 Slack의 채널 ID를 입력해주세요.
- Bearer YOUR_SLACK_BOT_TOKEN는 Slack App의 Bot Token을 입력해주어야 합니다.
이 스크립트는 다음과 같은 작업을 수행할 수 있습니다.
30 8 * * * /path/to/your/script.sh
이 방식의 장점은 다음과 같습니다:
- 시각화된 정보 전달: 텍스트만으로는 전달하기 어려운 복잡한 비용 정보를 한눈에 볼 수 있는 이미지로 제공합니다.
- 커스터마이징 용이성: Grafana 대시보드를 원하는 대로 구성하고 그 전체 모습을 그대로 Slack으로 전송할 수 있습니다.
- 높은 유연성: 스크립트를 수정하여 여러 대시보드 패널을 순차적으로 전송하거나 특정 조건에 따라 다른 대시보드를 전송하는 등의 고급 기능을 구현할 수 있습니다.
이러한 자동화된 보고 시스템을 통해 팀은 매일 아침 시각화된 비용 현황을 Slack에서 직접 확인할 수 있으며 이상 징후가 발견될 경우 신속하게 대응할 수 있습니다. 또한 이미지 형태로 전달되는 보고서는 팀 내 공유와 논의를 촉진하여 더욱 효과적인 비용 관리를 가능하게 합니다.
Grafana 대시보드와 이 자동화된 이미지 전송 시스템을 결합함으로써 우리는 “접근 가능하고 시기적절한 데이터”를 완벽히 실현할 수 있게 되었습니다. 이는 단순한 비용 모니터링을 넘어 데이터 기반의 의사결정과 지속적인 최적화를 가능케 하는 강력한 도구가 될 것입니다.
생성형 AI를 활용한 자동화된 비용 보고서 생성 및 Slack Webhook 전달
이번 섹션에서는 네이버 클라우드의 HCX003 생성형 AI 모델을 활용하여 자동화된 비용 보고서를 생성하고 이를 Slack으로 전달하는 과정을 살펴보겠습니다. 이 시스템은 일일 비용 데이터를 분석하고 인사이트를 제공하며 이를 팀원들과 쉽게 공유할 수 있게 해줍니다.
- 데이터 수집 및 전처리
먼저 InfluxDB에서 비용 데이터를 가져오는 함수를 구현합니다. 이 함수는 최근 7일간의 실제 비용 데이터와 향후 7일간의 예측 비용 데이터를 쿼리합니다.
def get_cost_data_from_influxdb():
client = InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG)
query_api = client.query_api()
# 실제 비용 데이터 쿼리
actual_cost_query = f'''
from(bucket:"{INFLUX_BUCKET}")
|> range(start: -7d, stop: now())
|> filter(fn: (r) => r._measurement == "ncloud_billing" and r.service == "totalcost")
|> filter(fn: (r) => r._field == "use_amount")
|> sort(columns: ["_time"])
'''
# 예측 비용 데이터 쿼리
forecast_query = f'''
from(bucket:"{INFLUX_BUCKET}")
|> range(start: now(), stop: 7d)
|> filter(fn: (r) => r._measurement == "ncloud_billing_forecast" and r.service == "totalcost")
|> filter(fn: (r) => r._field == "predicted_amount")
|> sort(columns: ["_time"])
'''
actual_result = query_api.query(query=actual_cost_query)
forecast_result = query_api.query(query=forecast_query)
# 쿼리 결과를 처리하여 cost_data 리스트 생성
cost_data = []
for table in actual_result:
for record in table.records:
cost_data.append({
"time": record.values.get("_time").strftime("%Y-%m-%d"),
"cost": record.values.get("_value"),
"type": "actual"
})
for table in forecast_result:
for record in table.records:
cost_data.append({
"time": record.values.get("_time").strftime("%Y-%m-%d"),
"cost": record.values.get("_value"),
"type": "forecast"
})
cost_data.sort(key=lambda x: x["time"])
client.close()
return cost_data
또한 각 서비스별 비용 데이터를 가져오는 함수도 구현합니다.
def get_all_services_data():
client = InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG)
query_api = client.query_api()
query = f'''
from(bucket:"{INFLUX_BUCKET}")
|> range(start: -7d, stop: now())
|> filter(fn: (r) => r._measurement == "ncloud_billing")
|> filter(fn: (r) => r._field == "use_amount")
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> sort(columns: ["_time"])
'''
result = query_api.query(query=query)
services_data = {}
for table in result:
for record in table.records:
service = record.values.get("service")
time = record.values.get("_time").strftime("%Y-%m-%d")
cost = record.values.get("use_amount")
if service not in services_data:
services_data[service] = []
services_data[service].append({"time": time, "cost": cost})
client.close()
return services_data
- 데이터 분석
수집된 데이터를 기반으로 기본적인 분석을 수행합니다.
def analyze_cost_data(cost_data, services_data):
# 가장 최신 totalcost 값 가져오기
total_cost = next((item["cost"] for item in reversed(cost_data) if item["type"] == "actual"), 0)
#print(total_cost)
# 가장 비용이 높은 서비스 찾기 (totalcost 제외)
highest_cost_service = max(
((service, data[-1]["cost"]) for service, data in services_data.items() if service != "totalcost" and data),
key=lambda x: x[1]
)
#print(highest_cost_service)
# 비용 상승률이 가장 높은 서비스 찾기 (totalcost 제외)
highest_increase_service = None
highest_increase_rate = 0
for service, data in services_data.items():
if service != "totalcost" and len(data) > 1:
start_cost = data[0]["cost"]
end_cost = data[-1]["cost"]
if start_cost > 0:
increase_rate = (end_cost - start_cost) / start_cost
if increase_rate > highest_increase_rate:
highest_increase_rate = increase_rate
highest_increase_service = (service, increase_rate * 100, start_cost, end_cost)
print(cost_data)
return {
"total_cost": total_cost,
"highest_cost_service": highest_cost_service,
"highest_increase_service": highest_increase_service,
"cost_data": cost_data
}
- HCX003 모델을 활용한 보고서 생성
최근 생성형 AI의 결과물에 대한 신뢰도를 높이기 위해 파인튜닝(Fine-tuning)이나 RAG(Retrieval-Augmented Generation) 등의 기술이 많이 사용되고 있습니다. 그러나 이 과정에서는 이러한 기술들을 의도적으로 사용하지 않았습니다.
1) 데이터의 명확성: InfluxDB에서 가져오는 비용 데이터는 명확하고 구조화되어 있습니다. 우리는 필요한 정확한 데이터를 얻기 위해 미리 정의된 쿼리를 사용합니다.
2) 직접적인 데이터 제공: 생성형 AI에게 실제 데이터를 직접 제공함으로써 모델이 정확한 정보를 바탕으로 보고서를 작성할 수 있게 합니다.
3) 불필요한 복잡성 회피: RAG를 구현하려면 VectorDB, 청크 분할, 임베딩 등 추가적인 작업과 리소스가 필요합니다. 해당 사용 사례에서는 불필요한 복잡성을 더할 뿐입니다.
4) 정확성 유지: 유사도 기반의 데이터 검색(RAG에서 주로 사용)은 때때로 실제 데이터와 무관한 정보를 가져올 risk가 있습니다. 반면 이 과정에서는 항상 정확한 최신 데이터를 사용합니다.
5) 효율성: 파인튜닝이나 RAG 파이프라인 구축 대신 명확한 프롬프트 엔지니어링을 통해 원하는 결과를 얻을 수 있습니다.
따라서 위에서 InfluxDB 쿼리로 조회한 데이터와 HCX003 모델을 활용하여 비용 데이터에 대한 상세한 분석을 프롬프트 엔지니링만으로 생성할 수 있도록 아래와 같이 진행했습니다.
class HCX003Wrapper(LLM):
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
request_data = {
'messages': [
{"role":"system","content": system_template},
{"role":"user","content": prompt}
],
# ... (모델 파라미터 설정)
}
return execute_hcx003(completion_executor, request_data, 'request_id')
def analyze_cost_trend(analyzed_data):
llm = HCX003Wrapper()
query_prompt = f"""
- 참고 : 총 비용 (가장 최근 totalcost): {analyzed_data["total_cost"]:.2f}원
- 참고 : 가장 비용이 많이 나온 서비스: {analyzed_data["highest_cost_service"][0]} (최신 비용: {analyzed_data["highest_cost_service"][1]:.2f}원)
- 참고 : 비용 상승률이 가장 높은 서비스: {analyzed_data["highest_increase_service"][0]} (상승률: {analyzed_data["highest_increase_service"][1]:.2f}%)
비용 데이터: {json.dumps(analyzed_data["cost_data"], indent=2)}
"""
return llm(query_prompt)
추가로 시스템 프롬프트에 아래와 같이 페르소나 및 예시를 요청하였습니다.
(내가 원하는 형태로 보고서를 받고 싶은 경우 작성 예시를 명확하게 제공해주는 것이 좋습니다.)
system_template = """ 귀하는 클라우드 비용 관리를 전문으로 하는 재무 분석가입니다. 지난 한달간의 클라우드 비용 데이터와 이번 달 그리고 향후 7일간의 예상 비용을 분석하세요: - 사용중인 퍼블릭 클라우드 : 네이버 클라우드 플랫폼 - 비용은 매일 오전 7시경 업데이트 됩니다. - 비용 추세에 대한 자세한 분석을 제공해 주시기 바랍니다: 1. 전반적인 추세(증가, 감소 또는 안정적) 2. 일상적인 변화와 그 중요성 3. 실제 과거 비용과 예상 미래 비용 간의 비교 4. 주목할 만한 패턴 또는 이상 징후 5. 해당되는 경우 비용 최적화를 위한 권장 사항 6. 가장 비용이 많이 나온 서비스의 발생 비용을 알려주세요. 7. 비용 상승률이 가장 높은 서비스의 최근 7일 간 비용 상승률을 알려주세요. 비즈니스 보고서에 적합한 명확하고 간결한 방식으로 분석 형식을 지정합니다. ### 작성 예시(가장 높은 비용 서비스: Server(VPC), 비용 상승률 최고 서비스: Data Catalog라고 가정) 네이버 클라우드 플랫폼 비용 분석 보고서 1. 전반적인 추세: 비용이 지속적으로 증가하는 추세를 보이고 있습니다. - 실제 비용: 실제 비용은 7일 동안 135,800원에서 208,740원으로 53.7% 증가했습니다. - 예상 비용: 예측 비용은 향후 7일 동안 218,443원에서 289,120원으로 32.4% 추가 증가할 것으로 예상됩니다. 2. 일상적인 변화: - 일일 평균 증가율: 일일 비용 증가율은 평균 7.5%로, 상당히 높은 수준입니다. - 중요성: 지속적인 증가 추세로 주의 필요 3. 실제 비용 vs 예상 비용: - 최근 실제 비용(208,740원) 대비 7일 후 예상 비용(289,120원) - 38.5% 증가 예상되어 빠른 대응 필요 4. 주목할 만한 패턴: - 10월 16일 급격한 비용 증가 (158,750원 → 170,460원, 7.4% 상승) - 예상 비용에서 일일 변동폭 증가 (약 1만원 → 2만원) 5. 비용 최적화 권장 사항: - Server(VPC) 사용량 최적화 검토 - Data Catalog 사용 패턴 분석 및 효율화 - 전반적인 리소스 사용량 모니터링 강화 6. 가장 높은 비용 서비스: Server(VPC), 73,940원 7. 비용 상승률 최고 서비스: Data Catalog - 최근 7일 상승률: 63.93% (110원 → 130원) 결론: 전반적인 비용 증가 추세가 뚜렷하며, 특히 Server(VPC)와 Data Catalog 서비스에 주목할 필요가 있습니다. 향후 7일간 약 32.4%의 추가 비용 증가가 예상되며, 전반적인 리소스 관리 개선이 필요 한지 검토 후 비용 최적화 프로세스를 수립하고 반영이 되었는지 확인해야합니다. """
이 부분에서 HCX003 모델은 주어진 비용 데이터를 바탕으로 상세한 분석 보고서를 생성합니다. 시스템 프롬프트에는 클라우드 비용 관리 전문가로서의 역할과 분석해야 할 주요 포인트들이 정의되어 있습니다.
- Slack으로 보고서 전송
생성된 보고서를 Slack으로 전송하는 함수를 구현합니다
def send_slack_report(analysis):
payload = {"text": analysis}
response = requests.post(SLACK_WEBHOOK_URL, json=payload)
response.raise_for_status()
- 전체 프로세스 통합
def main():
cost_data = get_cost_data_from_influxdb()
services_data = get_all_services_data()
analyzed_data = analyze_cost_data(cost_data, services_data)
analysis = analyze_cost_trend(analyzed_data)
send_slack_report(analysis)
이 시스템의 주요 장점은 다음과 같습니다.
- 자동화: 매일 정해진 시간에 자동으로 보고서를 생성하고 전송합니다.
- 심층 분석: HCX003 모델을 활용하여 단순한 수치 나열을 넘어선 인사이트를 제공합니다.
(HCX-DASH-001과도 비교해봤는데 보고서 생성 속도는 HCX-DASH-001이 더 빠르지만 데이터 분석 및 상세한 보고서 작성 부분은 HCX-003이 더 좋은 결과물을 만들었습니다.) - 실시간 대응: Slack을 통해 즉시 팀원들과 정보를 공유할 수 있어 비용 이상 징후에 빠르게 대응할 수 있습니다.
- 맞춤형 분석: 시스템 프롬프트를 수정하여 원하는 형태의 분석 결과를 얻을 수 있습니다.
위 과정을 통해 원하는 시간이나 트리거를 통해 AI 기반의 상세 분석 보고서는 비용 관리에 대한 팀의 이해도를 높이고 보다 전략적인 의사결정을 가능하게 할 것입니다.
Result
- Grafana Dashboard(TotalCost) to Slack
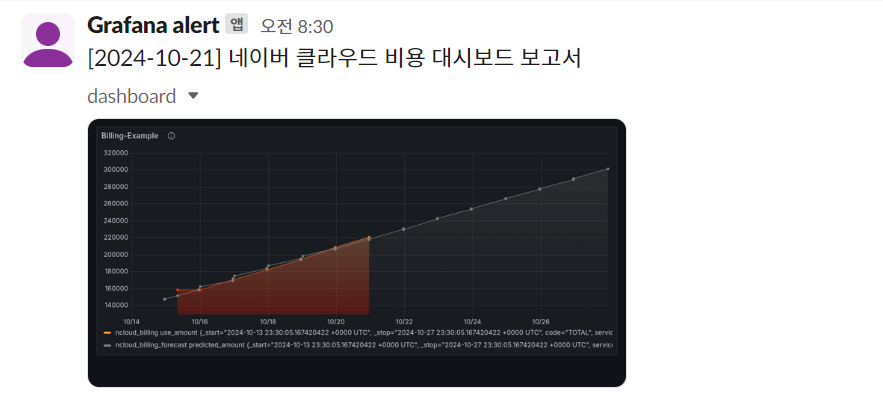
- Billing Report(Made in HCX) to Slack
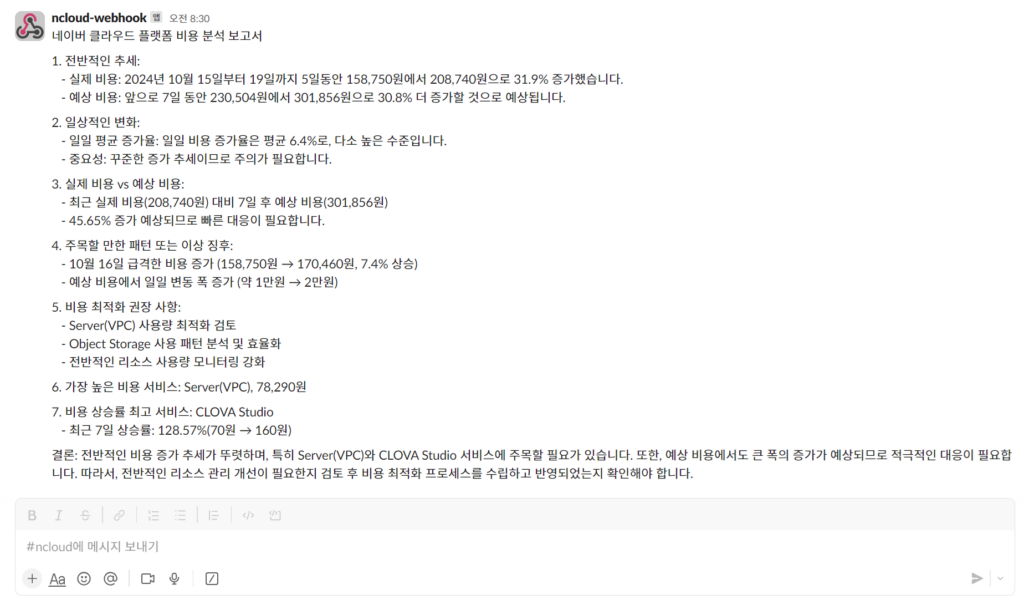
개인적인 사용 경험을 공유하자면 이 시스템을 실제로 구현하여 사용해 본 결과 클라우드 비용 관리가 훨씬 더 효율적이고 예측 가능해졌습니다. 이제 매일 아침 8시 30분 출근길에 Slack으로 전달되는 비용 대시보드와 AI 분석 보고서를 확인할 수 있습니다.
이를 통해 최신 비용 현황과 예측 비용을 한눈에 파악할 수 있게 되었고 특히 AI가 분석해준 보고서는 비용 흐름을 이해하는 데 큰 도움이 됩니다. 급격한 비용 상승이 발생한 서비스가 있다면 즉시 확인하고 대응할 수 있어 예상치 못한 비용 폭증을 방지할 수 있게 되었습니다.
가장 큰 장점은 매번 Grafana나 네이버 클라우드 콘솔에 직접 접속하지 않아도 된다는 점입니다. 비용 데이터가 자동으로 업데이트되고 이를 바탕으로 한 모니터링 결과와 분석 보고서가 Slack으로 전달되니 정말 편리했습니다. 이런 일상적이고 간결한 보고 체계 덕분에 클라우드 지출에 대한 통찰력이 크게 향상되었고 가변적인 클라우드 비용을 더욱 안정적으로 관리할 수 있게 되었습니다.
결론적으로 이 시스템은 네이버 클라우드 환경을 운영함에 있어 단순한 도구를 넘어 클라우드 비용 관리의 새로운 패러다임을 제시했다고 생각합니다. 여러분도 이런 시스템을 구축해 보시면 클라우드 비용 관리에 대한 새로운 시각을 가질 수 있을 것입니다.
Personal Comments
이번 포스트에서 우리는 네이버 클라우드 환경에서 효과적인 비용 관리를 위한 두 가지 핵심 시스템을 살펴보았습니다.
- Grafana를 활용한 비용 모니터링 대시보드 구현 및 Slack 전달
- 생성형 AI (HCX003)를 활용한 자동화된 비용 보고서 생성 및 Slack Webhook 전달
이 두 시스템은 상호 보완적으로 작동하며 “접근 가능하고 시기적절한 데이터”와 “클라우드의 가변 비용 모델 활용”을 효과적으로 실현합니다.
Grafana 대시보드를 통해 우리는 실시간으로 비용 현황을 시각적으로 파악할 수 있게 되었습니다. 이는 비용 트렌드를 즉각적으로 인식하고 대응할 수 있게 해주는 강력한 도구가 되었습니다.
이러한 시스템의 구현은 단순히 비용 절감을 넘어 클라우드 리소스의 효율적 활용과 비즈니스 가치 최적화라는 FinOps의 궁극적 목표에 한 걸음 더 다가가게 해줍니다. 실시간 모니터링, AI 기반 분석, 그리고 자동화된 보고 체계는 클라우드 환경의 복잡성과 가변성에 효과적으로 대응할 수 있는 기반을 마련해줄 것입니다.
물론 이 시스템들은 시작점일 뿐입니다. 현재까지 제가 공유드렸던 비용 관련 포스팅들을 응용하여 조금 더 강력한 비용 관리 시스템을 만들 수도 있습니다.
끝으로 효과적인 클라우드 비용 관리는 단순히 도구나 시스템의 문제가 아니라 조직 문화의 문제임을 강조하고 싶습니다. 이러한 시스템을 통해 얻은 인사이트를 팀 전체가 공유하고 지속적인 개선을 위해 노력하는 문화를 만들어 나가는 것이 진정한 FinOps의 실현이 될 것입니다.
긴 글 읽어주셔서 감사합니다.