
안녕하세요 MANVSCLOUD 김수현입니다.
오늘은 올해 AI를 처음 접해보며 Neo4j를 사용하여 GraphRAG를 구현하고 사용하고 HyperCLOVA X를 이용한 Text2SQL 처리를 경험해본 내용을 공유드리고자 합니다.
1. 서론
- 연구 배경 및 동기
현대의 IT 산업은 생성형 AI의 급속한 성장과 함께 빠르게 변화하고 있습니다.
클라우드 엔지니어로서 주로 IT 인프라에 집중해 왔던 저는 이러한 변화 속에서 AI 프로젝트와 서비스가 늘어남에 따라 비용과 성능이 최적화된 인프라 아키텍처에 대한 요구가 높아지고 있음을 느꼈습니다.
이에 따라 RAG(Retrieval-Augmented Generation), 청킹(chunking) 전략, 임베딩 모델에 따른 답변 Score 차이 등 AI의 전반적인 흐름을 이해하고 이를 바탕으로 요구 사항에 맞는 인프라를 고민할 필요성을 느꼈습니다. 테스트 용도로 가볍게 만들어볼 수 있는 Serverless AI Architecture부터 CLOVA Studio에서 제공하는 Segmentation API의 Chunking 방식과 응용 등을 연구해봤지만 진행하며 가장 재밌었던 것을 공유 해보고자 합니다.
따라서 이번에 공유할 연구 주제는 ‘Neo4j 기반 GraphRAG 구현과 CLOVA Studio를 통한 Text2SQL 변환’입니다. 요즘 다양한 OTT 플랫폼의 등장으로 원하는 콘텐츠를 쉽게 접할 수 있는 시대입니다. 하지만 특정 장르나 내용을 포함한 영상을 찾는 데에는 여전히 많은 시간이 소요됩니다.
이전에 시청했던 드라마나 영화의 내용은 기억나지만 제목이 떠오르지 않거나 해당 콘텐츠를 어떤 플랫폼에서 볼 수 있는지 혼란스러울 때도 많았습니다.
이러한 불편함을 해소하고자 신뢰도 높은 답변을 제공할 수 있는 방법을 모색하게 되었고 그 결과 생성형 AI와 RAG 기술에 주목하게 되었습니다.
일반적인 접근 방법으로 생성형 AI인 HyperCLOVA, ChatGPT, Claude 등을 활용해 “내가 보고 싶은 영상의 내용은 이렇고 이런 내용이 포함된 것 같은데 제목이 무엇이고 어느 OTT 플랫폼에서 볼 수 있나요?”라고 질문할 수 있습니다. 그러나 이러한 방법은 원하는 영상의 정확한 정보와 해당 OTT 플랫폼에서의 제공 여부에 대한 신뢰도 높은 답변을 얻기 어렵습니다.
최신 영화나 드라마의 경우 생성형 AI가 아직 해당 정보를 학습하지 않았을 수 있고 학습된 데이터라 하더라도 판권 계약의 만료로 인해 실제 OTT 플랫폼에서는 더 이상 해당 영상이 존재하지 않을 수 있습니다.
따라서 신뢰도 높은 답변을 제공하기 위해서는 최신화된 데이터를 활용하는 방법이 필요하며 이 과정에서 최신 데이터가 포함된 RAG 기술을 사용해볼 수 있습니다. RAG를 구현한다고 했을 때 Vector Database를 활용할 수도 있고 Graph Database를 선택할 수도 있습니다.
다만 VectorRAG는 구조화되지 않은 데이터를 처리할 때 이상적이며 GraphRAG는 데이터와 그 관계가 명확하고 구조화된 시나리오에서 탁월한 성능을 발휘합니다.
OTT 플랫폼의 경우 사용자 정보와 영상 정보 간의 관계가 명확하게 정의되어 있으므로 데이터 무결성과 일관성이 보장되는 GraphRAG를 선택하는 것이 적합하다고 판단했습니다.물론 관계와 거리가 먼 질문을 할 수도 있지만 Graph Database로 사용할 Neo4j는 VectorStore를 지원했기 때문에 이 부분도 고려했습니다.
예를 들어 사용자의 나이, 성별, 선호 장르, 시청 기록 등의 정보와 영상의 장르, 연령 제한, 줄거리 등이 있습니다.
사용자가 “내가 최근에 본 드라마와 비슷한 드라마를 추천해줘”라고 질문할 때 특정 사용자와 영상 간의 관계 그리고 영상의 속성 정보(드라마, 영화, 장르 등)가 명확하기 때문에 굳이 VectorRAG를 통해 유사도를 계산할 필요 없이 GraphRAG를 활용하여 정확한 답변을 도출할 수 있습니다.
또한 사용자는 다양한 질문을 할 수 있습니다. 예를 들어 “30대 남성이 가장 많이 본 영상을 알려줘”, “귀신에 대한 내용이 포함된 영상을 추천해줘”, “내가 봤던 영상 목록 좀 알려줘”, “내가 주로 보던 장르 위주로 최신 영상을 추천해줘” 등
이에 대응하기 위해서는 자연어로 된 질의를 데이터베이스 질의어(SQL)로 변환하는 Text2SQL 기술을 적용해보기로 했습니다.
본 연구의 목적은 결국 OTT 플랫폼에서의 사용자 경험 향상을 목표로 했을 때 Neo4j를 기반으로 한 GraphRAG 구현과 CLOVA Studio를 활용한 Text2SQL 변환에 대한 경험은 어땠는지 공유하는 것입니다.
2. Text2SQL이란?
- 정의 및 개념 설명
Text2SQL은 자연어를 SQL(Structured Query Language)로 변환하는 자연어 처리 기술입니다. (NL2SQL이라고도 쓰임) 사용자가 자연어로 데이터베이스에 질의하면 Text2SQL 모델이 이를 이해하고 분석하여 해당하는 SQL 쿼리문을 자동으로 생성합니다. Text2SQL 모델은 사용자의 자연어 질의문을 입력으로 받아 데이터베이스의 스키마와 내용을 분석한 뒤 이에 맞는 SQL 문을 출력합니다. 이를 위해 모델은 자연어 질의에서 언급된 테이블과 컬럼을 파악하고 조건이나 조인 등의 SQL 문법 요소를 추출하여 최종 SQL 쿼리를 구성합니다.
- 중요성 및 적용 분야
- 데이터베이스 접근성 향상
Text2SQL 기술을 통해 일반 사용자도 복잡한 SQL 문법을 배우지 않고도 자연어로 데이터베이스를 쉽게 검색하고 정보를 얻을 수 있습니다. (데이터 분석과 활용의 진입 장벽을 크게 낮춰줌) - 업무 효율성 증대
기업에서 데이터 분석 업무를 수행할 때 Text2SQL을 활용하면 분석 속도와 효율이 크게 향상됩니다. (복잡한 SQL 쿼리문을 일일이 작성하는 수고를 줄일 수 있음) - 활용 범위의 확대
Text2SQL 기술은 챗봇, 음성 비서, BI 툴 등 다양한 분야에 적용 가능합니다. 사용자 인터페이스를 통해 자연어로 데이터베이스를 검색하는 기능을 구현할 수 있어 서비스의 사용성을 높이는 데 기여합니다. - 실시간 데이터 접근
Text2SQL을 통해 사용자는 실시간으로 데이터베이스에 접근하여 최신 정보를 확인할 수 있습니다.
- 데이터베이스 접근성 향상
3. Vector Database 대신 Neo4j(Graph Database)로 RAG를 구현한 이유
- RAG(Retrieval-Augmented Generation)의 개념
RAG는 신뢰할 수 있는 외부 데이터 세트 또는 지식 기반 데이터베이스를 참조하는 프로세스로 기존 대규모 언어 모델(LLM)을 수정하지 않고 결합하여 정확하고 관련성 높은 정보를 기반으로 텍스트를 생성하기 위해 검색 기능을 이용하는 기술입니다. 대규모 외부 지식을 활용하여 언어 모델의 생성 능력을 향상시킬 수 있습니다. 이를 통해 언어 모델은 자신의 학습 데이터 외에도 방대한 외부 지식을 활용할 수 있게 됩니다. 따라서 이 방식을 잘 활용한다면 관련 정보를 실시간으로 검색하고 이를 기반으로 응답을 생성하여 정보의 최신성과 관련성을 보장할 수 있게 되기에 실시간 정보 반영이 중요한 챗봇, 질의응답 시스템 등에서 유용하게 사용할 수 있습니다.
- RAG를 위한 구성 요소
– Data Preprocessing (Extract/Parse, Chunk)
→ 문맥을 이해한 문단 분리: 문서에서 의미 있는 단위로 내용을 분할합니다.
→ Document Loading: 데이터베이스에서 문서를 로드합니다.
→ Text Segmentation, Summarization: 텍스트를 세분화하고 요약하여 중요 정보를 추출합니다.
– Embedding
→ 유사성을 가지고 있는 Vector 제공: 문서 내용을 벡터 형태로 표현하여 유사 문서 검색을 용이하게 합니다.
→ 고차원의 벡터를 통해 세밀한 데이터 제공: 복잡한 데이터 특성을 정교하게 매핑합니다.
→ LLM을 이용한 데이터 재생성: 언어 모델을 사용해 데이터를 다시 해석하고 생성 과정에 통합합니다.
– Vector Database (Index)
→ Vector 기반 데이터 저장: 생성된 벡터들을 데이터베이스에 저장합니다.
→ 유사성 검색: 저장된 벡터들 중 유사한 항목을 빠르게 검색합니다.
→ 대규모 데이터 처리: 방대한 양의 데이터를 효율적으로 관리하고 검색할 수 있습니다.
RAG의 구현에 대한 자료는 일반적으로 Vector Database를 사용한 케이스가 많았는데 이번 연구에서는 Neo4j라는 Graph Database를 활용하여 RAG를 구현했습니다.
- Graph Database의 이점
Graph Database는 데이터를 Node와 Edge로 표현하여 데이터 간의 관계를 효과적으로 저장하고 탐색할 수 있는 데이터베이스입니다. 이는 데이터와 관계가 명확하고 구조화된 시나리오에 특히 적합합니다. Graph Database를 활용함으로써 다음과 같은 이점을 얻을 수 있었습니다:
- 데이터 무결성과 일관성 보장 : Graph Database에 저장된 데이터는 미리 정의된 스키마와 관계를 따르기 때문에 데이터의 무결성과 일관성이 보장됩니다..
- 복잡한 관계 쿼리의 효율적 처리 : Graph Database는 노드 간의 관계를 빠르게 탐색할 수 있도록 최적화되어 있습니다. 즉, 여러 개체 간의 복잡한 관계를 효율적으로 처리할 수 있습니다.
- 유연한 데이터 모델링 : Graph Database는 유연한 데이터 모델을 제공하여 도메인 변화에 빠르게 대응할 수 있습니다. 새로운 개체나 관계를 쉽게 추가하고 수정할 수 있어 확장성이 뛰어납니다.
- Neo4j를 활용한 구현 방법
Neo4j 설치는 간단하며, 이 연구 과정에서는 Ubuntu 22.04에서 진행되었고 Neo4j 5.22.0 버전이 사용되었습니다. - Neo4j Install
curl -fsSL https://debian.neo4j.com/neotechnology.gpg.key |sudo gpg --dearmor -o /usr/share/keyrings/neo4j.gpg echo "deb [signed-by=/usr/share/keyrings/neo4j.gpg] https://debian.neo4j.com stable 4.1" | sudo tee -a /etc/apt/sources.list.d/neo4j.list sudo apt update sudo apt install neo4j sudo systemctl enable neo4j.service sudo systemctl start neo4j.service
- /etc/neo4j/neo4j.conf 설정
: 아래 두 라이브러리를 사용할 수 있도록 .conf 파일에 추가하였습니다.
– APOC(Awesome Procedures On Cypher) : 데이터 가져오기/내보내기, 그래프 알고리즘, 변환, 메타데이터 관리 등 다양한 유틸리티 기능 제공 (Vector Store 기능을 사용하기 위해 필요한 주요 라이브러리)
– GDS(Graph Data Science) : 중심성 측정, 커뮤니티 감지, 경로 찾기 등의 고급 그래프 알고리즘 사용 가능
dbms.security.procedures.unrestricted=apoc.*,gds.* dbms.security.procedures.allowlist=apoc.*,gds.*
sudo systemctl restart neo4j.service
- Python 코드에서 사용 시 사용 모듈 및 Neo4j 데이터베이스 연결 코드
# Neo4j 연결
from langchain_community.graphs import Neo4jGraph
from langchain.chains import GraphCypherQAChain
# Neo4j 데이터베이스 연결(Neo4j 서버가 Local서버일 경우(전통적인 연결 방식))
graph = Neo4jGraph(
url="bolt://localhost:7687",
username="neo4j",
password="패스워드"
)
# Neo4j 데이터베이스 연결(Neo4j 서버가 Local서버가 아닐 경우(클러스터, 부하 분산 등 최신 방식))
graph = Neo4jGraph(
url="neo4j://IP:7687",
username="neo4j",
password="패스워드"
)
연구 방식은 서론에서 말했던 서비스를 만든다고 가정하여 테스트를 진행했습니다. ’내가 보고싶은 영상을 어느 OTT에서 볼 수 있는지, 최근 가장 인기 있는 영화는 무엇인지, 스릴러 장르의 영화들은 어떤 것들이 있는지 등 영상을 추천해주는 서비스’를 만든다면 사용자들은 어떤 질문들을 할 수 있을지 먼저 생각해보았고 아래와 같이 사용자 질문 예시가 나왔습니다.
| 사용자 질문 예시
요즘 사람들이 가장 많이 보는 영상이 뭐야? 최근에 사람들이 가장 많이 보는 영상이 뭐야? 요즘 가장 인기 많은 영상이 뭐야? 요즘 가장 인기있는 영상이 뭐야? 최근들어 가장 인기있는 영상이 뭐야? 최근들어 가장 인기 많은 영상이 뭐야? TVING에서 추천하는 신규 드라마가 뭐가 있어? NETFLIX에서 볼 수 있는 최신 판타지 영화 추천해줘 LAFTEL에서 인기 있는 애니메이션을 추천해줘 DISNEY+에서 가족과 함께 볼 수 있는 예능을 추천해줘 TVING에서 피라미드 게임과 비슷한 드라마를 알려줘 NETFLIX에서 이번 주에 가장 인기가 많았던 드라마를 알려줘 LAFTEL에서 성인을 위한 애니메이션 추천해줘 DISNEY+에서 판타지 장르의 최신 시리즈 알려줘 TVING에서 15세 이상 추천 영상 있어? NETFLIX의 이번 달에 사람들이 가장 많이 본 애니메이션은 뭐야? LAFTEL에서 볼 수 있는 19세 이상의 콘텐츠 추천해줘 DISNEY+의 인기 어린이 프로그램 보여줘 TVING에서 장르별 인기 콘텐츠를 알려줘 NETFLIX에서 추천하는 스릴러 영화를 추천해줘 LAFTEL에서 최근 인기있는 콘텐츠 리스트 보여줘 DISNEY+에서 새로 나온 애니메이션이 있을까? TVING에서 성인 대상의 신규 콘텐츠 알려줘 NETFLIX에서 볼 수 있는 콘텐츠 좀 추천해줘 LAFTEL에서 평점 높은 애니메이션 보여줘 DISNEY+에서 현재 가장 인기 있는 드라마가 뭐야? TVING에서 최근에 본 드라마 장르와 비슷한 작품 추천해줘 NETFLIX에서 사람들이 지금 가장 많이 보는 콘텐츠는? LAFTEL의 이번 달 인기 애니메이션 순위를 알려줘 DISNEY+에서 어린이를 위한 교육 콘텐츠 추천해줘 TVING에서 마지막으로 본 장르와 같은 작품 리스트를 보여줘 NETFLIX에서 높은 평점을 받은 다큐멘터리 알려줘 LAFTEL에서 완결된 인기 애니메이션 시리즈 추천해줘 DISNEY+의 마블 시리즈 중 평점이 높은 작품은 뭐가 있어? TVING에서 로맨스 장르의 인기 드라마 top 3 알려줘 NETFLIX에서 한국 오리지널 드라마 추천해줘 LAFTEL에서 일본 애니메이션 중 인기 있는 작품 알려줘 DISNEY+에서 최근에 개봉한 영화 리스트 보여줘 TVING에서 내가 좋아할 만한 예능 프로그램 추천해줘 NETFLIX에서 평점이 높은 로맨틱 코미디 영화 알려줘 LAFTEL에서 SF 장르의 애니메이션을 찾고 있어 DISNEY+에서 픽사 애니메이션 중 가장 인기 있는 작품은? TVING에서 액션 장르의 드라마 추천해줘 NETFLIX에서 최근 개봉한 한국 영화 중 평점이 높은 작품 알려줘 LAFTEL에서 스포츠 애니메이션 있어? DISNEY+에서 디즈니 프린세스 애니메이션 리스트 보여줘 TVING에서 시청자가 뽑은 역대 최고의 드라마 top 5는? NETFLIX에서 추천하는 범죄 스릴러 영화 있어? LAFTEL에서 음식 관련 애니메이션 추천해줘 DISNEY+에서 내가 좋아하는 배우가 나오는 작품 찾아줘 TVING에서 최근 완결된 드라마 중 인기 있는 작품 알려줘 NETFLIX에서 가장 많은 상을 받은 오리지널 시리즈는 뭐야? LAFTEL에서 로맨스 장르의 애니메이션 추천해줘 DISNEY+에서 국내에서 제작된 콘텐츠 있어? TVING에서 시청 연령별 인기 예능 프로그램 알려줘 NETFLIX에서 추천하는 코미디 영화 top 10 리스트 보여줘 LAFTEL에서 청불 애니메이션 리스트 알려줘 DISNEY+에서 최근에 시즌이 추가된 드라마 있어? TVING에서 높은 시청률을 기록한 드라마 top 3 알려줘 NETFLIX에서 가장 오래된 오리지널 시리즈는 뭐야? LAFTEL에서 판타지 장르의 애니메이션 추천해줘 DISNEY+에서 어린이용으로 더빙된 애니메이션 있어? TVING에서 추천하는 시대극 드라마 있어? NETFLIX에서 한국에서 가장 인기 있는 해외 드라마는 뭐야? LAFTEL에서 가장 인기있는 애니메이션을 추천해줘 DISNEY+에서 최근에 리메이크된 애니메이션 있어? TVING에서 내가 좋아하는 장르의 예능 프로그램 찾아줘 NETFLIX에서 추천하는 한국 다큐멘터리 있어? LAFTEL에서 마법소녀 장르의 애니메이션 리스트 보여줘 DISNEY+에서 새로 나온 오리지널 시리즈 중 평점이 높은 작품은? TVING에서 가장 오래 방영된 예능 프로그램은 뭐야? NETFLIX에서 공포 영화 top 5 알려줘 LAFTEL에서 이세계 전생 애니메이션 추천해줘 DISNEY+에서 클래식 애니메이션 리스트 보여줘 TVING에서 요즘 핫한 드라마 뭐 있어? NETFLIX에서 높은 평점을 받은 스탠드업 코미디 추천해줘 LAFTEL에서 음악 관련 애니메이션 있어? DISNEY+에서 가장 인기 있는 오리지널 영화는 뭐야? TVING에서 추천하는 미스터리 드라마 있어? NETFLIX에서 한국에서 제작된 영화 중 해외에서도 인기 있는 작품 알려줘 LAFTEL에서 학원 배경의 애니메이션 추천해줘 DISNEY+에서 최근에 개봉한 실사 영화 리스트 보여줘 TVING에서 인기 있는 웹드라마 top 3 알려줘 NETFLIX에서 추천하는 액션 영화 있어? LAFTEL에서 로봇 애니메이션 리스트 보여줘 DISNEY+에서 가장 많은 사람들이 좋아하는 캐릭터는 누구야? TVING에서 최근에 종영한 드라마 중 평점이 높은 작품 알려줘 NETFLIX에서 가장 많이 시청된 오리지널 영화는 뭐야? LAFTEL에서 사무라이 애니메이션 추천해줘 DISNEY+에서 어른들이 좋아할 만한 애니메이션 있어? TVING에서 시청자가 뽑은 역대 최고의 커플은 누구야? NETFLIX에서 높은 평점을 받은 로맨스 드라마 top 5 알려줘 LAFTEL에서 좀비 애니메이션 리스트 보여줘 DISNEY+에서 최근에 리뉴얼된 애니메이션 시리즈 있어? TVING에서 추천하는 음식 예능 프로그램 있어? NETFLIX에서 한국에서 제작된 시리즈 중 해외에서 인기 있는 작품 알려줘 LAFTEL에서 스포츠 만화를 원작으로 한 애니메이션 추천해줘 DISNEY+에서 새로 나온 다큐멘터리 시리즈 있어? TVING에서 요즘 인기 있는 버라이어티 프로그램 top 3 알려줘 NETFLIX에서 추천하는 한국 호러 영화 있어? LAFTEL에서 이세계에 관련된 내용이 포함된 애니메이션 리스트 보여줘 DISNEY+에서 가장 긴 런닝타임을 가진 애니메이션 영화는 뭐야? TVING에서 역대 시청률 top 10 드라마 리스트 보여줘 NETFLIX에서 가장 많은 에피소드를 가진 오리지널 시리즈는 뭐야? LAFTEL에서 닌자에 대한 내용이 포함된 애니메이션 추천해줘 DISNEY+에서 최근에 오픈한 마블 시리즈가 있어? 내가 주로 보던 장르 위주로 최신 영상을 추천해줘 아이들과 함께 볼 수 있는 예능이 있을까? 전체 연령 감상이 가능한 영상을 알려줘 나와 같은 연령대가 가장 많이 보는 영상을 알려줘 10대가 많이 보는 영상을 알려줘 20대가 많이 보는 영상을 알려줘 30대가 많이 보는 영상을 알려줘 40대가 많이 보는 영상을 알려줘 50대가 많이 보는 영상을 알려줘 60대가 많이 보는 영상을 알려줘 70대가 많이 보는 영상을 알려줘 80대가 많이 보는 영상을 알려줘 여자들이 가장 많이 보는 영상을 알려줘 남자들이 가장 많이 보는 영상을 알려줘 여성들이 가장 많이 보는 영상을 알려줘 남성들이 가장 많이 보는 영상을 알려줘 10대 남성이 가장 선호하는 장르를 알려줘 20대 남성이 가장 선호하는 장르를 알려줘 30대 남성이 가장 선호하는 장르를 알려줘 40대 남성이 가장 선호하는 장르를 알려줘 50대 남성이 가장 선호하는 장르를 알려줘 10대 여성이 가장 선호하는 장르를 알려줘 20대 여성이 가장 선호하는 장르를 알려줘 30대 여성이 가장 선호하는 장르를 알려줘 40대 여성이 가장 선호하는 장르를 알려줘 50대 여성이 가장 선호하는 장르를 알려줘 10대 남성이 가장 많이 본 영상을 알려줘 20대 남성이 가장 많이 본 영상을 알려줘 30대 남성이 가장 많이 본 영상을 알려줘 40대 남성이 가장 많이 본 영상을 알려줘 50대 남성이 가장 많이 본 영상을 알려줘 10대 여성이 가장 많이 본 영상을 알려줘 20대 여성이 가장 많이 본 영상을 알려줘 30대 여성이 가장 많이 본 영상을 알려줘 40대 여성이 가장 많이 본 영상을 알려줘 50대 여성이 가장 많이 본 영상을 알려줘 10대 남자가 가장 선호하는 장르를 알려줘 20대 남자가 가장 선호하는 장르를 알려줘 30대 남자가 가장 선호하는 장르를 알려줘 40대 남자가 가장 선호하는 장르를 알려줘 50대 남자가 가장 선호하는 장르를 알려줘 10대 여자가 가장 선호하는 장르를 알려줘 20대 여자가 가장 선호하는 장르를 알려줘 30대 여자가 가장 선호하는 장르를 알려줘 40대 여자가 가장 선호하는 장르를 알려줘 50대 여자가 가장 선호하는 장르를 알려줘 10대 남자가 가장 많이 본 영상을 알려줘 20대 남자가 가장 많이 본 영상을 알려줘 30대 남자가 가장 많이 본 영상을 알려줘 40대 남자가 가장 많이 본 영상을 알려줘 50대 남자가 가장 많이 본 영상을 알려줘 10대 여자가 가장 많이 본 영상을 알려줘 20대 여자가 가장 많이 본 영상을 알려줘 30대 여자가 가장 많이 본 영상을 알려줘 40대 여자가 가장 많이 본 영상을 알려줘 50대 여자가 가장 많이 본 영상을 알려줘 서바이벌과 관련된 영상을 추천해줘 무당에 대한 내용이 포함된 영상을 추천해줘 권력에 대한 내용이 포함된 영상을 추천해줘 연금술에 관련된 내용이 포함된 영상을 추천해줘 농구에 관련된 내용이 포함된 영상을 추천해줘 여행에 관련된 내용이 포함된 영상을 추천해줘 야구에 대한 내용이 포함된 영상을 추천해줘 먹거리에 대한 내용이 포함된 영상을 추천해줘 음식과 관련이 높은 영상을 추천해줘 음악에 대한 내용이 포함된 영상을 추천해줘 구미호에 대한 내용이 포함된 영상을 추천해줘 샤머니즘에 대한 내용이 포함된 영상을 추천해줘 왕따에 대한 내용이 포함된 영상을 추천해줘 교통에 대한 내용이 포함된 영상을 추천해줘 귀신에 대한 내용이 포함된 영상을 추천해줘 요리에 대한 내용이 포함된 영상을 추천해줘 역사에 대한 내용이 포함된 영상을 추천해줘 내가 좋아요를 누른 영상들 좀 알려줘 내가 좋아요를 누른 것 중 아직 본 적 없는 영상들을 알려줘 내가 봤던 영상 목록 좀 알려줘 내가 가장 최근에 본 영상이 뭐야? 최근 1주일 간 봤던 영상 목록 좀 알려줘 (생략)
다양한 질문들이 존재할 수 있겠지만 결국 내가 원하는 영상을 어느 OTT에서 볼 수 있냐?, ○○와 관련된 영상은 어떤 것들이 있냐?, 최근 가장 인기 있는 영상이 뭐야?, ○○ 장르 영상을 추천해줘의 질문을 할 수 있을 것인데 영상 추천 서비스라는 범위가 정해져있기에 질문도 어느 정도 정해진 범위가 있을 것이라 판단했습니다. 이렇게 질문이 고정적인 범위가 있다고 판단될 경우 HCX-003 또는 HCX-DASH-001을 튜닝하여 사용하고 관련없는 질문은 고정적인 답변을 하도록 처리하여 비용 효율적이고 신뢰도 높은 답변을 제공할 수 있도록 구현이 가능할 것입니다. 또한 추천받은 영상을 기준으로 내가 봤던 영상, 안봤던 영상을 구분할 수 있을 것이고 좋아요가 많은 순위별로 보거나 장르별 필터링을 서비스 단에서 추가로 구현해준다면 멋진 서비스가 될 수 있을 것입니다.
먼저 사용된 데이터 일부는 다음과 같습니다.
(실제로 존재하지 않는 임의로 생성한 데이터입니다.)
| contents.csv
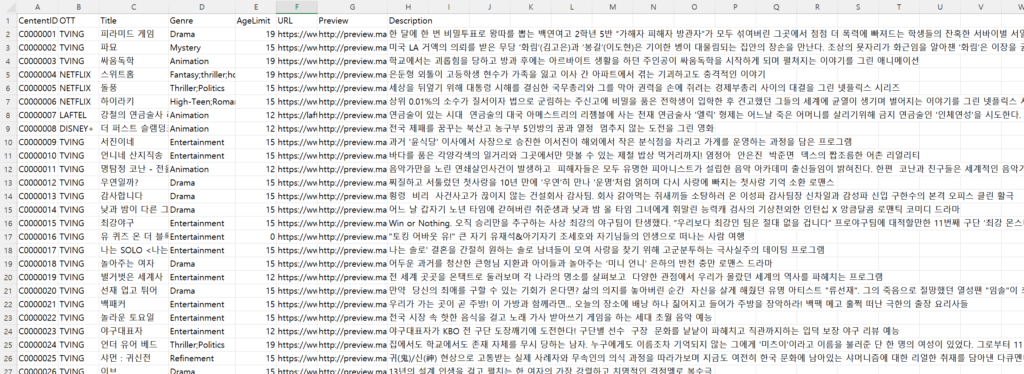
| users.csv
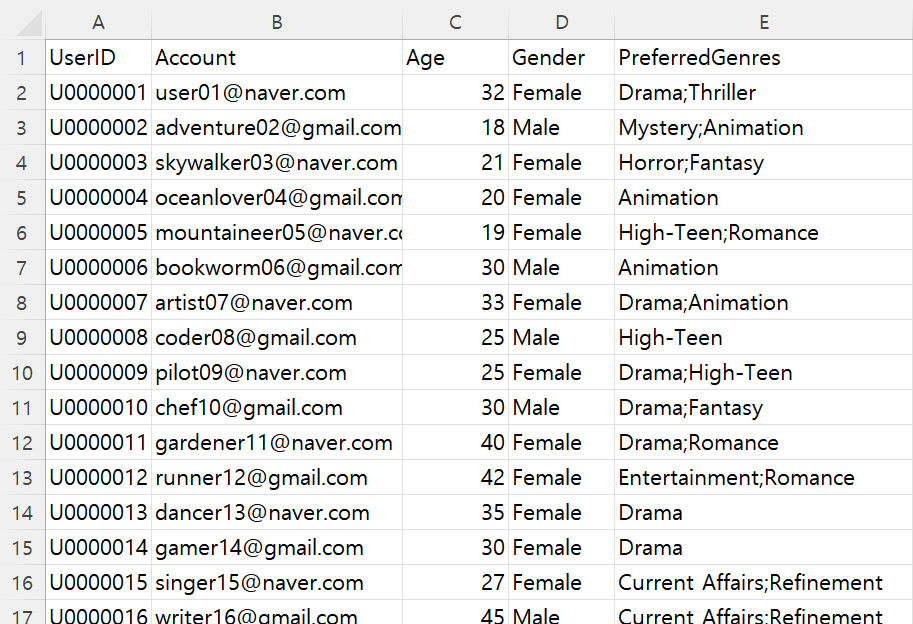
| watches_likes.csv
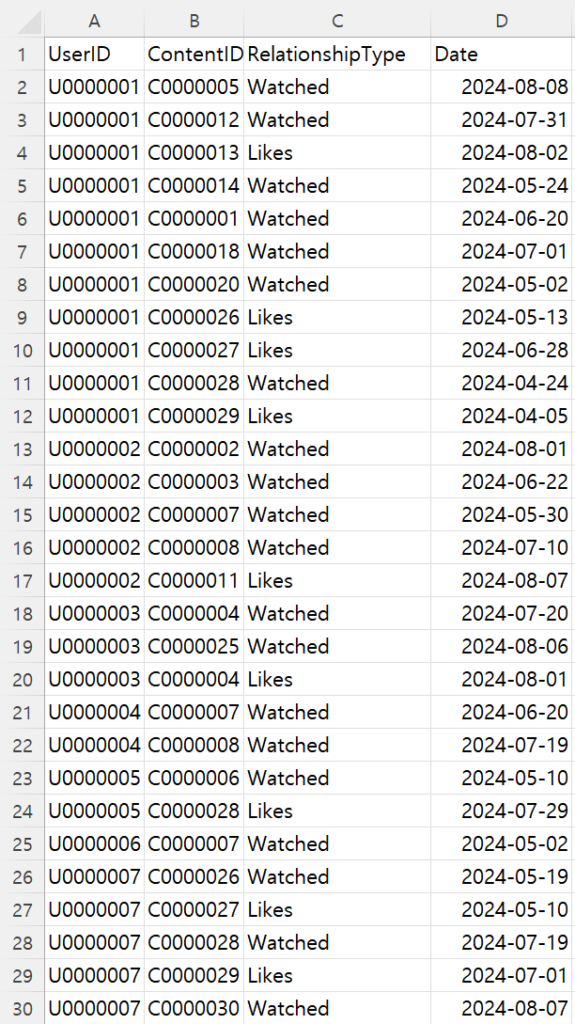
- Neo4j에 추가될 데이터 파일 체크
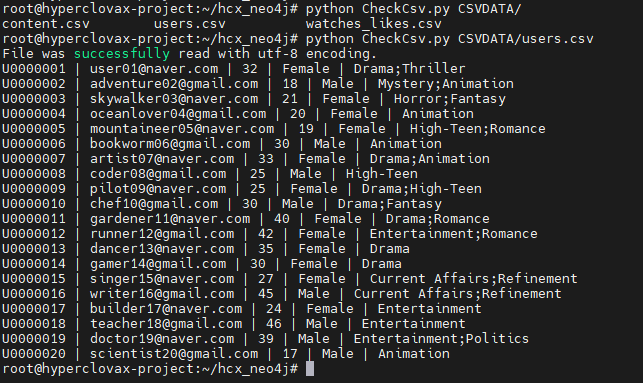
이 연구에서는 위 데이터들과 Neo4j를 활용하여 GraphRAG를 구현했습니다. 이를 위해 다음과 같은 방법을 사용했습니다:
- 데이터 모델링: 사용자 정보와 OTT별 영상 정보 노드를 생성하고 이들 간의 관계를 다음과 같이 정의했습니다. 예를 들어, (사용자 A)-[Likes]->(영상 C), (사용자 E)-[Watched]->(영상 A)와 같은 관계를 설정했습니다.
- 데이터 로딩: OTT 플랫폼으로부터 수집한 각 데이터를 Neo4j에 로드했습니다. 이 때, 노드의 속성과 관계의 유형을 미리 정의된 스키마에 맞게 설정했습니다.

- Text2SQL 적용: 사용자의 자연어 질의를 SQL 쿼리로 변환하는 Text2SQL 기술을 활용했습니다. 이를 통해 “30대 남자가 가장 많이 본 영상을 알려줘”, “내가 봤던 영상 목록 좀 알려줘”와 같은 다양한 질문을 Neo4j에 대한 Cypher 쿼리로 변환할 수 있었습니다.
- 검색 및 답변 생성: Text2SQL을 통해 생성된 Cypher 쿼리를 Neo4j에서 실행하여 관련 정보를 검색했습니다. 검색된 정보를 언어 모델에 제공하여 사용자의 질문에 대한 최종 답변을 생성했습니다.
Neo4j와 Text2SQL을 활용한 GraphRAG 구현은 구조화되고 관계가 명확한 데이터를 효과적으로 활용하여 신뢰도 높은 답변을 생성할 수 있는 방법임을 확인했습니다. 이는 OTT 플랫폼의 개인화 추천과 같이 사용자, 콘텐츠, 메타데이터 간의 복잡한 관계를 다루는 시나리오에 특히 적합할 것으로 기대됩니다.
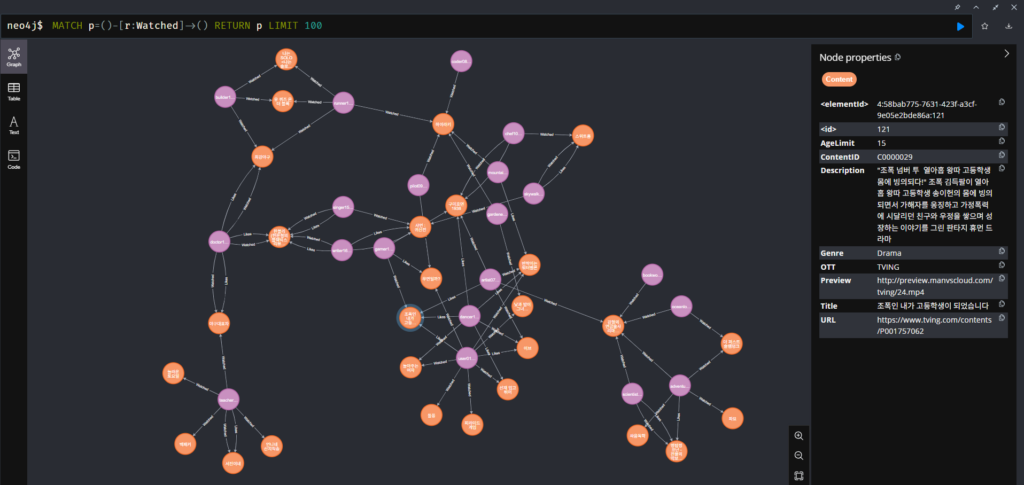
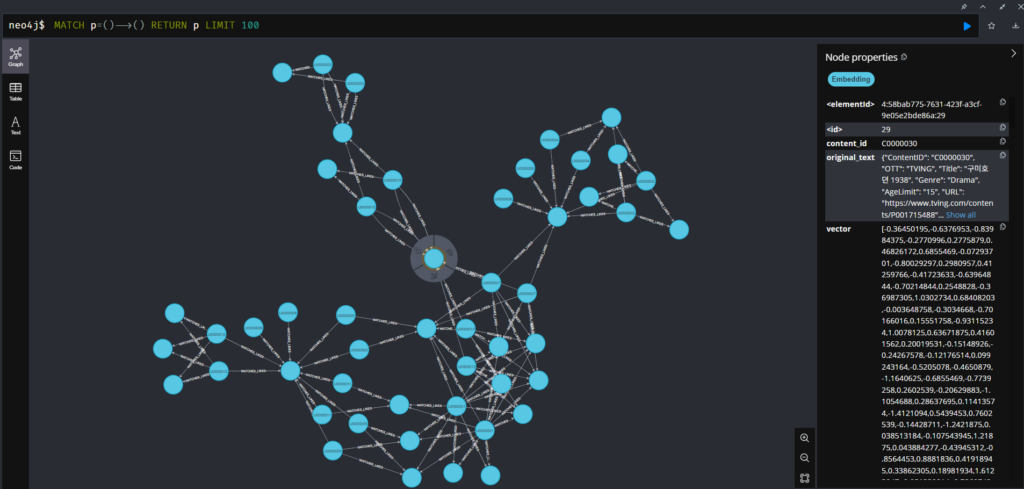
| Neo4j UI에서 데이터가 추가되고 노드 간 관계가 맺어진 화면
| Text2SQL with CLOVA Studio
from dotenv import load_dotenv
from langchain_teddynote import logging
# .env
load_dotenv()
# LangSmith 프로젝트명 설정 및 추적 여부
logging.langsmith("{LANGSMITH_PROJECT_NAME}", set_enable=False)
from langchain_teddynote.messages import stream_response # 스트리밍 출력
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from HCX.CompletionExecutor import CompletionExecutor, execute_hcx003, execute_hcxdash001
from langchain_community.graphs import Neo4jGraph
from langchain.chains import GraphCypherQAChain
from langchain.llms.base import LLM
from typing import List, Optional
# HCX_CHAT
completion_executor = CompletionExecutor(
host='https://clovastudio.stream.ntruss.com',
api_key='{PLAYGROUND_API_KEY}',
api_key_primary_val='{PLAYGROUND_API_KEY_PRIMARY_VAL}'
)
# 시스템 설정
system_template = """
#당신은 사용자 질문을 Cypher Query로 만들어주는 AI 어시스턴트입니다.
#다른 내용 없이 Cypher Query만 답변주셔야합니다.
# 드라마 = Drama
# 예능 = Entertainment
# 애니, 애니메이션, 만화 = Animation
# 호러, 공포 = Horror
# 미스테리, 미스터리 = Mystery
# 스릴러 = Thriller
# 판타지 = Fantasy
# 하이틴 = Fantasy
# 로맨스 = Fantasy
# 시사 = Current Affairs
# 교양 = Refinement
# 정치 = Politics
#아래는 TVING에서 최근에 본 드라마처럼 재밌는 드라마를 추천해줘.라는 질문에 대한 Cypher Query 예시(답변)입니다.
MATCH (u:User {UserID: '{user_id}'})-[r:Watched]->(c:Content)
WHERE c.OTT = "TVING" AND c.Genre CONTAINS "Drama"
WITH c
MATCH (c)<-[:Watched]-(o:User)-[:Watched]->(rec:Content)
WHERE rec.OTT = "TVING" AND rec.Genre CONTAINS "Drama" AND rec <> c
RETURN DISTINCT rec.Title AS Title, rec.URL AS URL, rec.Preview AS Preview, rec.Description AS Description
LIMIT 3
"""
# HCX 상세 설정
class HCXDASH001Wrapper(LLM):
@property
def _llm_type(self) -> str:
return "custom"
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
request_data = {
'messages': [
{"role":"system","content": system_template},
{"role":"user","content": prompt}
],
'topP': 0.8,
'topK': 0,
'maxTokens': 256,
'temperature': 0.5,
'repeatPenalty': 5.0,
'stopBefore': [],
'includeAiFilters': True,
'seed': 0
}
return execute_hcxdash001(completion_executor, request_data, 'ad38c0d6-89e3-4b06-85a5-3ee1ae6a8b61')
# Neo4j 데이터베이스 연결
graph = Neo4jGraph(
url="bolt://localhost:7687",
username="neo4j",
password="패스워드"
)
# LLM 인스턴스 생성
llm = HCXDASH001Wrapper()
# 사용자 질문
user_id = "U0000001"
question = "TVING에서 피라미드 게임과 비슷한 드라마를 알려줘"
# 질문을 바탕으로 Cypher 쿼리 생성
query_prompt = f"""
사용자 ID: {user_id}
사용자 질문: {question}
위 정보를 바탕으로 사용자의 질문에 적합한 Cypher 쿼리를 생성해주세요.
"""
generated_query = llm(query_prompt)
# 생성된 쿼리 실행
graph_result = graph.query(generated_query)
# 답변 생성 및 출력
print(f"Generated Cypher:\n{generated_query}")
print(f"Full Context:\n{graph_result}")
| 실행 결과
LangSmith 추적을 하지 않습니다.
/usr/local/lib/python3.10/dist-packages/langchain_core/_api/deprecation.py:141: LangChainDeprecationWarning: The method `BaseLLM.__call__` was deprecated in langchain-core 0.1.7 and will be removed in 1.0. Use invoke instead.
warn_deprecated(
Generated Cypher:
MATCH (u:User {UserID: 'U0000001'})-[r:Watched]->(c:Content)
WHERE c.OTT = "TVING" AND c.Title =~ "피라미드 게임"
WITH c
MATCH (c)<-[:Watched]-(o:User)-[:Watched]->(rec:Content)
WHERE rec.OTT = "TVING" AND rec.Genre CONTAINS "Drama" AND rec <> c
RETURN DISTINCT rec.Title AS Title, rec.URL AS URL, rec.Preview AS Preview, rec.Description AS Description
LIMIT 3
Full Context:
[{'Title': '반짝이는 워터멜론', 'URL': 'https://www.tving.com/contents/P001743591', 'Preview': 'http://preview.manvscloud.com/tving/23.mp4', 'Description': '음악에 천부적인 재능을 타고난 코다(CODA) 소년 은결(려운)이 1995년으로 타임슬립해 어린 시절의 아빠(최현욱)와 함께 밴드를 하며 펼쳐지는 판타지 청춘 드라마'}, {'Title': '선재 업고 튀어', 'URL': 'https://www.tving.com/contents/P001754312', 'Preview': 'http://preview.manvscloud.com/tving/15.mp4', 'Description': '만약 당신의 최애를 구할 수 있는 기회가 온다면? 삶의 의지를 놓아버린 순간 자신을 살게 해줬던 유명 아티스트 "류선재". 그의 죽음으로 절망했던 열성팬 "임솔"이 최애를 살리기 위해 시간을 거슬러 2008년으로 돌아간다! 다시 살게 된 열아홉 목표는 최애 류선재를 지키는 것!'}, {'Title': '놀아주는 여자', 'URL': 'https://www.tving.com/contents/P001756817', 'Preview': 'http://preview.manvscloud.com/tving/13.mp4', 'Description': '어두운 과거를 청산한 큰형님 지환과 아이들과 놀아주는 ‘미니 언니’ 은하의 반전 충만 로맨스 드라마'}]
| Flow
- UserID가 U0000001인 사용자가 “TVING에서 피라미드 게임과 비슷한 드라마를 알려줘”라는 질문을 합니다.
- HCX-DASH-001이 아래와 같이 Cypher Query를 생성합니다.
MATCH (u:User {UserID: 'U0000001'})-[r:Watched]->(c:Content)
WHERE c.OTT = "TVING" AND c.Title =~ "피라미드 게임"
WITH c
MATCH (c)<-[:Watched]-(o:User)-[:Watched]->(rec:Content)
WHERE rec.OTT = "TVING" AND rec.Genre CONTAINS "Drama" AND rec <> c
RETURN DISTINCT rec.Title AS Title, rec.URL AS URL, rec.Preview AS Preview, rec.Description AS Description
LIMIT 3
3. Cypher Query 실행 결과는 아래와 같습니다.
[
{
"Title": "반짝이는 워터멜론",
"URL": "https://www.tving.com/contents/P001743591",
"Preview": "http://preview.manvscloud.com/tving/23.mp4",
"Description": "음악에 천부적인 재능을 타고난 코다(CODA) 소년 은결(려운)이 1995년으로 타임슬립해 어린 시절의 아빠(최현욱)와 함께 밴드를 하며 펼쳐지는 판타지 청춘 드라마"
},
{
"Title": "선재 업고 튀어",
"URL": "https://www.tving.com/contents/P001754312",
"Preview": "http://preview.manvscloud.com/tving/15.mp4",
"Description": "만약 당신의 최애를 구할 수 있는 기회가 온다면? 삶의 의지를 놓아버린 순간 자신을 살게 해줬던 유명 아티스트 \"류선재\". 그의 죽음으로 절망했던 열성팬 \"임솔\"이 최애를 살리기 위해 시간을 거슬러 2008년으로 돌아간다! 다시 살게 된 열아홉 목표는 최애 류선재를 지키는 것!"
},
{
"Title": "놀아주는 여자",
"URL": "https://www.tving.com/contents/P001756817",
"Preview": "http://preview.manvscloud.com/tving/13.mp4",
"Description": "어두운 과거를 청산한 큰형님 지환과 아이들과 놀아주는 '미니 언니' 은하의 반전 충만 로맨스 드라마"
}
]
4. 화면 단에서 질문을 받고 위와 같이 나온 Json 데이터 결과를 화면에 뿌려주기만 간단하게 원하는 서비스를 만들 수 있을 것입니다.
4. CLOVA Studio를 통한 Text2SQL 진행 시 발생한 이슈
- 기술적 문제 및 도전 과제
Neo4j는 일반적으로 사용되는 관계형 데이터베이스인 MySQL이나 MSSQL과는 달리 Cypher Query Language를 사용합니다. 이로 인해 HyperCLOVA X를 활용하여 Cypher 쿼리를 생성할 때 할루시네이션(Hallucination)이 빈번하게 발생하는 문제가 나타났습니다. 즉, 모델이 존재하지 않거나 부정확한 쿼리를 생성하여 원하는 결과를 얻지 못하는 경우가 많았습니다.
한편 Claude 3.5 Sonnet을 활용하면 비교적 정확하게 Cypher 쿼리를 생성할 수 있었지만 비용이 매우 높다는 단점이 있었습니다. 또한 Claude 3.5 Sonnet조차도 항상 정확한 Cypher 쿼리를 생성하는 것은 아니어서 완벽한 해결책이 되지 못했습니다.

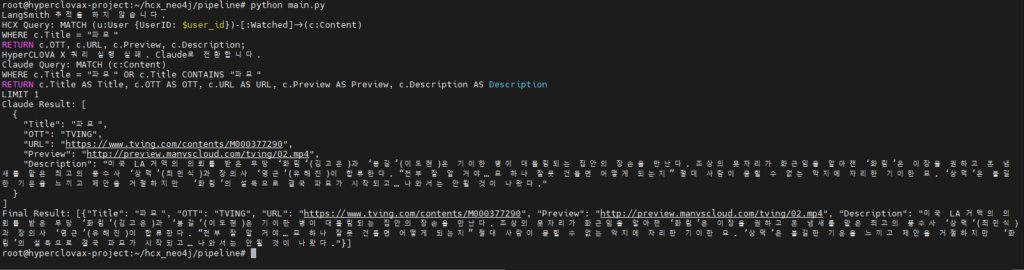
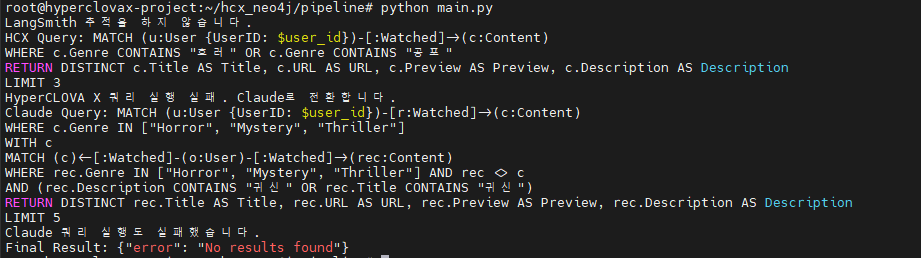
“파묘는 어디에서 볼 수 있어?”라고 질문 시 아래와 같이 HyperCLOVA X가 생성할 쿼리가 실패하여 Claude로 전환하는 사진을 볼 수 있습니다.
- 해결 방법 및 대안
- 모델 튜닝 및 멀티 LLM 도입: 초기에는 Claude를 사용하여 성공적으로 생성된 Cypher 쿼리를 수집하고 이를 기반으로 HyperCLOVA X를 튜닝(tuning)하여 Cypher 쿼리 생성 정확도를 높이고 추후에는 멀티 LLM(Multi-LLM) 방식을 도입하여 HyperCLOVA X가 먼저 쿼리를 생성하고 실패 시 Claude를 사용하도록 하여 비용 효율성을 높이는 방법 도입
(Claude는 Cypher Query 생성 확률이 높지만 토큰 비용이 비싸므로 비용 최적화 방안을 고려할 필요가 있음)
- 모델 튜닝 및 멀티 LLM 도입: 초기에는 Claude를 사용하여 성공적으로 생성된 Cypher 쿼리를 수집하고 이를 기반으로 HyperCLOVA X를 튜닝(tuning)하여 Cypher 쿼리 생성 정확도를 높이고 추후에는 멀티 LLM(Multi-LLM) 방식을 도입하여 HyperCLOVA X가 먼저 쿼리를 생성하고 실패 시 Claude를 사용하도록 하여 비용 효율성을 높이는 방법 도입
| LLM별 토큰 당 비용 | 토큰 당 비용(원) * 1$ = 1,333.33원 |
|---|---|
| HCX-DASH-001 (INPUT) | 0.001 |
| HCX-DASH-001 (OUTPUT) | 0.001 |
| Claude-3.5-Sonnet (INPUT) | 0.004 |
| Claude-3.5-Sonnet (OUTPUT) | 0.02 |
| HCX-DASH-001 (Tunning) | 0.003 |
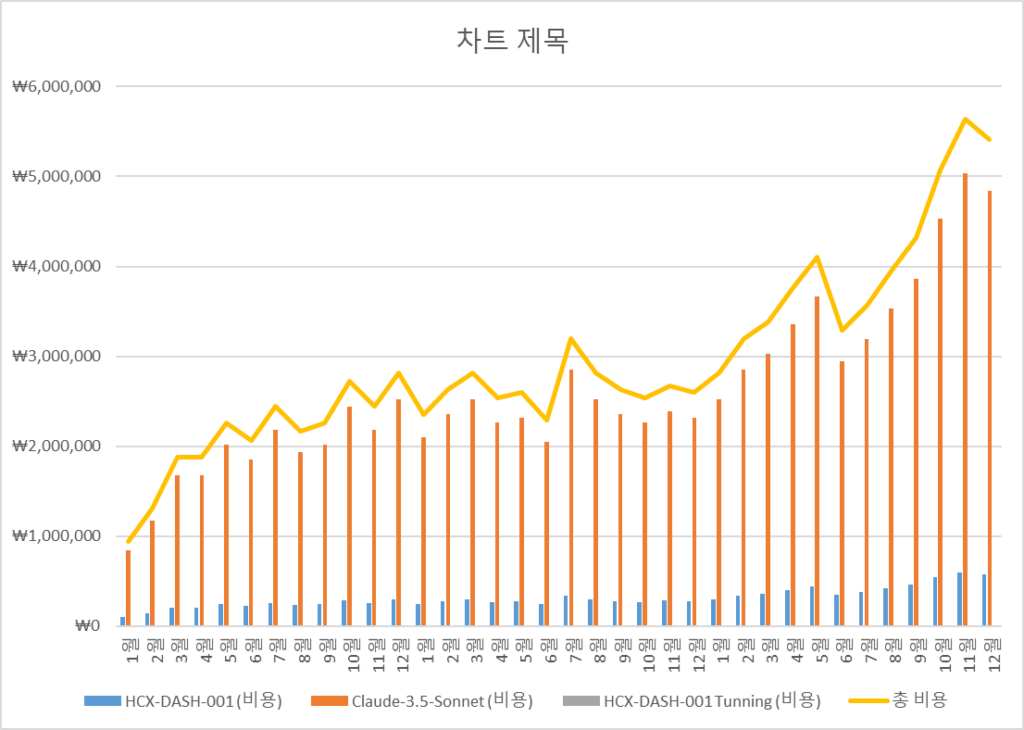
- 서비스 사용량이 랜덤하게 확대됨에 따라 3년간 지속적으로 사용량만큼 토큰 비용이 증가한다고 가정했을 때 기준으로 비교 (아래 모든 가정은 모든 INPUT/OUTPUT의 값이 같다는 가정하에 진행된 점 참고 부탁드립니다.)
- HCX-DASH-001 Tunning없이 HCX-DASH-001이 답변을 못했을 때 Claude-3.5-Sonnet가 답변 시 기준
| 3년간 총비용 | HCX-DASH-001 (비용) | Claude-3.5-Sonnet (비용) | HCX-DASH-001 Tunning (비용) | 총 비용 |
|---|---|---|---|---|
| 합계 | ₩11,212,000 | ₩94,180,800 | ₩0 | ₩105,392,800 |
- HCX-DASH-001이 답변을 못했을 때 Claude-3.5-Sonnet가 답변하되 1년간 매월 HCX-DASH-001 Tunning을 진행하고 이후부터는 격달로 Tunning을 진행 시 기준 (처음에는 70%정도를 Claude가 처리하고 매월 Tunning할 때마다 5%씩 Claude가 답변할 확률이 줄어든다고 가정(단 5% 미만으로 떨어지지 않음))
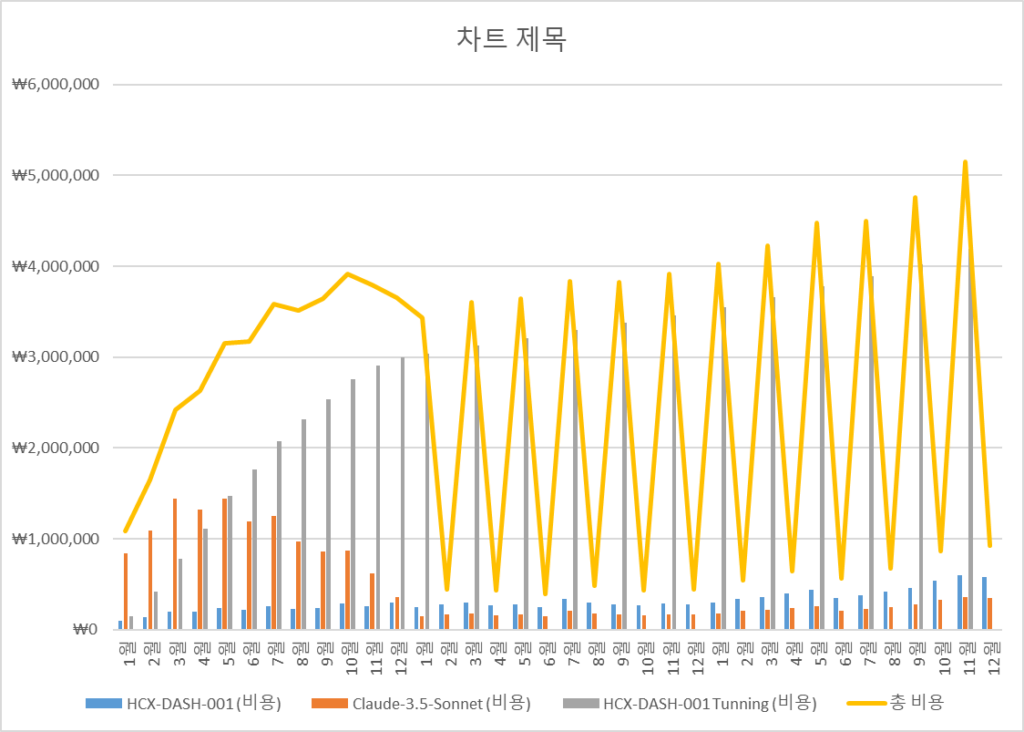
| 3년간 총비용 | HCX-DASH-001 (비용) | Claude-3.5-Sonnet (비용) | HCX-DASH-001 Tunning (비용) | 총 비용 |
|---|---|---|---|---|
| 합계 | ₩11,212,000 | ₩17,371,200 | ₩63,894,600 | ₩92,477,800 |
- 처음 1년간 Claude-3.5-Sonnet가 답변하고 이후 해당 데이터를 기반으로 2년차부터 HCX-DASH-001 Tunning을 격달로 진행 시 기준 (Tunning 후 Claude가 답변할 확률이 5%로 줄어든다고 가정(단 5% 미만으로 떨어지지 않음))
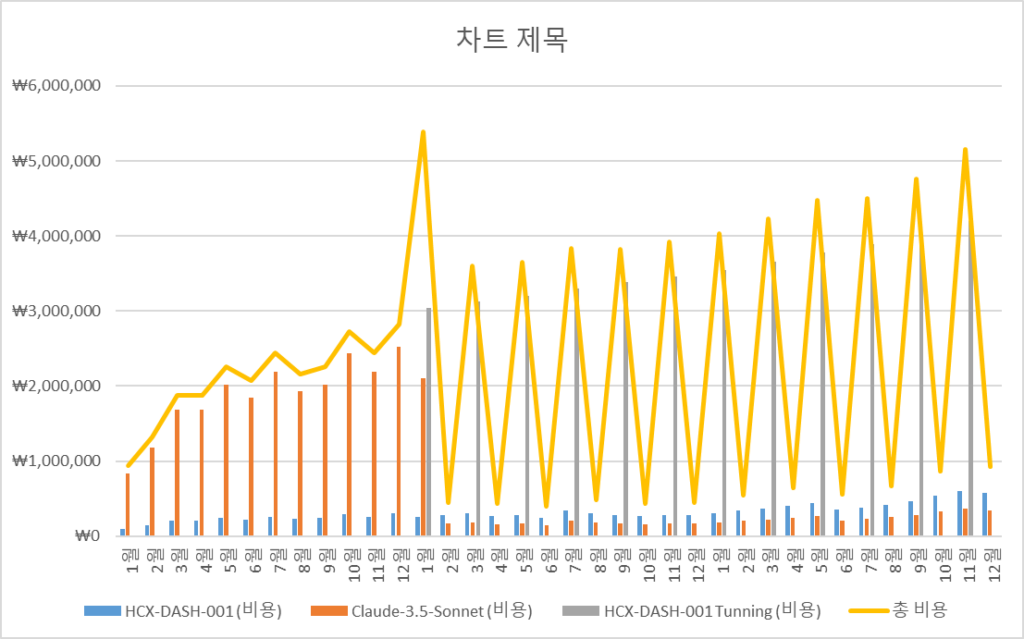
| 3년간 총비용 | HCX-DASH-001 (비용) | Claude-3.5-Sonnet (비용) | HCX-DASH-001 Tunning (비용) | 총 비용 |
|---|---|---|---|---|
| 합계 | ₩11,212,000 | ₩29,581,200 | ₩42,600,600 | ₩83,393,800 |
- Neo4j의 Text2Cypher 확장 기능 활용 : 사전에 Neo4j에서 제공하는 Text2Cypher – Natural Language Queries 확장 기능을 활용하여 사용자가 자연어로 입력한 질의를 Cypher 쿼리로 자동 변환해주는 기능으로 많이 사용될 수 있는 질문에 대한 Cypher Query를 사전에 추출 후 학습을 시키는 방법
- 유사도 기반 답변 제공: Claude 3.5 Sonnet조차 쿼리 생성에 실패하는 경우를 대비하여 Neo4j의 VectorStore를 활용하여 유사도 기반 답변을 생성하는 방법

- 키워드 추출 및 오타 보정: 유사도 기반 답변의 정확도를 높이기 위해 키워드 추출 방식 도입 및 사용자의 오타를 고려하여 HyperCLOVA X를 활용(HyperCLOVA X는 한국어 처리에 강점이 있어 한국어로 된 사용자 질문에서 키워드를 정확하게 추출하고 오타를 교정하는 데 유리함)
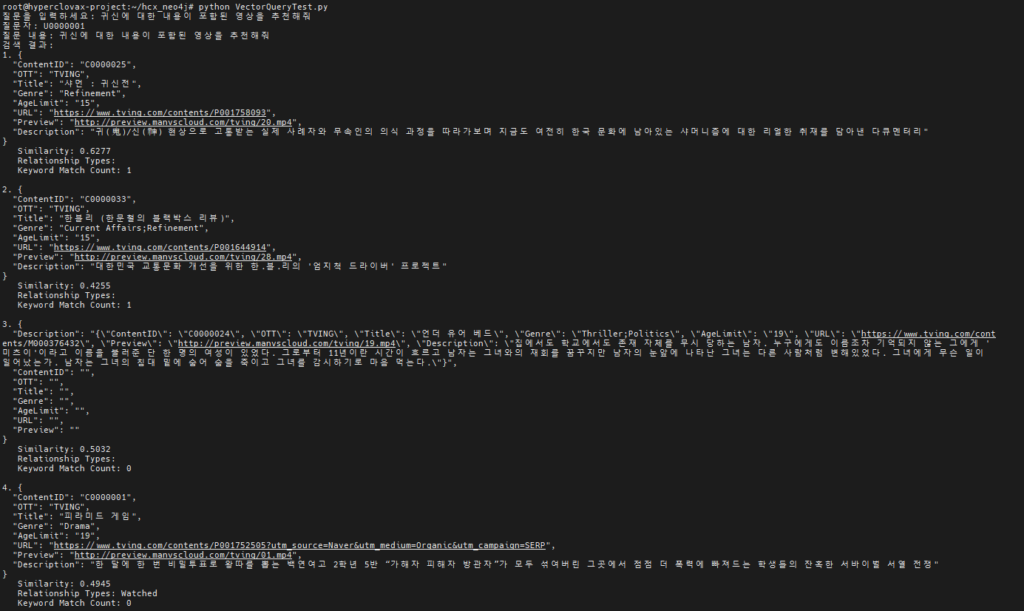
- 성능 분석
Neo4j를 이용하여 GraphRAG와 VectorRAG를 모두 구현하여 비교한 결과 작성된 코드에 따라 차이가 있을 수 있겠지만 GraphRAG가 더 빠르고 정확한 답변을 제공하는 것으로 나타났습니다. (드라마틱하게 차이가 나진 않았음 동일한 질문으로 여러번 실행하여 시간 측정 결과 Graph 방식은 평균 약 4.13초, Vector 방식은 4.48초의 시간이 소요됨) 이 연구에서 두 방식의 속도의 차이는 확신할 수 없으나 GraphRAG가 데이터의 관계를 명확하게 이해하고 활용하기 때문에 정확도는 확실히 높은 것으로 확인되었습니다.
반면 VectorRAG는 비구조화된 데이터를 처리하는 데 적합하지만 구조화된 데이터 시나리오에서는 유사도 기반으로 답변을 생성하여 제공하므로 정확도가 저하될 수 있습니다. 이 연구에서는 그렇게 대량의 데이터를 이용하여 연구된 것이 아니므로 두 방식의 속도 차이는 크게 느낄 수 없었기에 대규모 데이터 기준에서 속도 테스트는 추가적으로 필요할 것으로 보입니다.
Neo4j를 사용해보며 느꼈던 GraphRAG의 장점은 다음과 같습니다:
- 데이터 무결성과 일관성 보장: 명확한 데이터 구조와 관계를 통해 정확한 정보 제공.
- 빠른 질의 처리 속도: 복잡한 유사도 계산 없이도 신속한 답변 생성 가능.
- 높은 신뢰도: 데이터베이스의 최신 정보를 활용하여 최신화된 답변 제공.
이를 통해 신뢰도 높은 답변과 향상된 사용자 경험을 얻을 수 있었습니다.
5. 이 연구를 기반으로 활용할 수 있는 부분
- 실용적인 응용 분야 본 연구에서 구현한 Neo4j 기반 GraphRAG와 CLOVA Studio를 활용한 Text2SQL 변환 기술은 다양한 분야에서 실용적으로 활용될 수 있을 것이라 봅니다. 특히, 사용자와 데이터 간의 명확한 관계를 필요로 하는 시나리오에서 큰 가치를 발휘할 것입니다.
- OTT 플랫폼의 콘텐츠 추천 시스템: 사용자 시청 기록, 선호 장르, 나이, 성별 등의 정보를 활용하여 개인화된 콘텐츠 추천이 가능합니다. 이를 통해 사용자 만족도를 향상시키고 플랫폼의 이용률을 높일 수 있습니다.
- 전자상거래 분야의 제품 추천: 고객의 구매 이력, 관심 상품, 선호 브랜드 등의 데이터를 기반으로 맞춤형 제품을 추천하여 매출 증대에 기여할 수 있습니다.
- 소셜 네트워킹 서비스: 사용자 간의 관계, 관심사, 활동 내역 등을 분석하여 친구 추천, 맞춤형 콘텐츠 제공 등이 가능하며, 사용자 참여도를 높일 수 있습니다.
- 의료 정보 시스템: 환자의 진료 기록, 약물 복용 내역, 알레르기 정보 등을 관리하여 정확한 의료 서비스를 제공하고, 의료 사고를 예방할 수 있습니다.
- 교육 플랫폼의 학습자 맞춤형 콘텐츠 제공: 학습자의 학습 이력, 선호 과목, 성취도 등을 분석하여 개인화된 학습 경로와 자료를 제공함으로써 학습 효과를 높일 수 있습니다.
- 향후 발전 방향
- 모델의 정확도 및 효율성 향상: HyperCLOVA X의 지속적인 튜닝과 멀티 LLM 방식을 고도화하여 Cypher 쿼리 생성의 정확도와 효율성을 더욱 향상시킬 수 있습니다.
- 다국어 지원 및 글로벌 적용: 현재 한국어에 특화된 모델을 다른 언어로 확장하여 글로벌 시장에서의 적용 가능성을 높일 수 있습니다.
- 사용자 인터페이스 개선: 자연어 질의와 결과를 시각화하는 인터페이스를 개선하여 비전문가도 쉽게 시스템을 활용할 수 있도록 사용자 경험을 향상시킬 수 있습니다.
- 데이터 보안 및 프라이버시 강화: 개인정보 보호와 데이터 윤리에 대한 고려를 바탕으로 안전한 시스템을 구축하여 사용자 신뢰도를 높일 수 있습니다.
- 인공지능과의 융합 강화: 강화학습이나 딥러닝 등의 AI 기술을 접목하여 추천 시스템의 지능화 수준을 높이고, 보다 정교한 개인화 서비스를 제공할 수 있습니다.
- 실시간 데이터 처리 및 응답 속도 개선: 스트리밍 데이터 처리를 도입하여 실시간으로 변화하는 데이터에 빠르게 대응하고, 사용자에게 즉각적인 피드백을 제공할 수 있습니다.
- 오픈소스 커뮤니티와의 협업: Neo4j와 같은 오픈소스 프로젝트와의 협업을 통해 기술 발전에 기여하고, 다양한 사례를 공유함으로써 생태계를 활성화할 수 있습니다.
- 비즈니스 모델 확장: 연구 결과를 바탕으로 신규 서비스 개발이나 기존 서비스 개선을 통해 비즈니스 기회를 창출할 수 있습니다.
6. CLOVA Studio를 활용했을 때 한국어 기반 AI에 대한 전망
- 한국어 AI 기술의 현재와 미래
최근 인공지능 분야에서는 GPT-4, Llama 등 다양한 대형 언어 모델들이 등장하면서 한국어 처리 능력이 전반적으로 향상되고 있습니다. 그러나 이러한 모델들은 주로 영어 기반으로 개발되었기 때문에 한국어의 복잡한 문법 구조, 어휘적 미묘함, 문화적 맥락 등을 완벽하게 이해하는 데에는 한계가 있습니다.
한국어는 어순이 자유롭고 높임말, 반말, 사투리 등 다양한 표현 방식이 존재하여 자연어 처리가 더욱 복잡합니다. 또한 한국의 역사, 문화, 법률, 지리 등 세부적인 지식에 대한 이해가 부족하면 사용자에게 정확하고 신뢰성 있는 정보를 제공하기 어렵습니다.
미래의 한국어 AI 기술은 이러한 한계를 극복하고 보다 자연스럽고 문화적으로 적합한 언어 이해 및 생성 능력을 갖추는 방향으로 발전할 것으로 예상됩니다. 이를 위해서는 한국어에 특화된 대규모 언어 모델의 개발과 지속적인 데이터 축적이 필요합니다.
- CLOVA Studio의 역할
CLOVA Studio는 네이버에서 개발한 대규모 언어 모델인 HyperCLOVA X(HCX)를 기반으로 합니다.
HCX의 강점은 다음과 같습니다:
– 한국어의 미묘한 표현 이해: 예를 들어, 제주도 사투리와 같은 지역 방언도 정확하게 해석하고 번역할 수 있습니다. 실제로 “과랑 과랑혼 벳디 일 호젠 호난 속았수다”라는 제주도 사투리를 HCX-DASH-001 모델을 통해 정확하게 해석할 수 있었습니다.
→ ChatGPT 4o의 “과랑 과랑혼 벳디 일 호젠 호난 속았수다” 해석 : “사람이 많은 곳에서 일하느라 정신이 없었어요.” (X)
→ Claude 3.5 Sonnet의 “과랑 과랑혼 벳디 일 호젠 호난 속았수다” 해석 : “과랑과랑한 벳길에 일하자고 하더니 속았습니다” (X)
→ HCX-DASH-001의 “과랑 과랑혼 벳디 일 호젠 호난 속았수다” 해석 : “쨍쨍한 햇볕에 일하려고 하니 수고하셨습니다” (O)
– 한국 문화와 지식에 대한 이해: 한국의 역사, 문화, 법률, 지리 등에 대한 세부적인 지식을 바탕으로 보다 정확하고 신뢰성 있는 정보를 제공합니다.
– 한국어 사용자 경험 개선: 한국어로 된 질의에 대해 자연스럽고 유려한 답변을 생성하여 사용자 만족도를 높입니다.
HCX는 이러한 강점을 통해 Vector DB에서 얻은 데이터를 한국적인 느낌으로 전달하거나 한국어 특유의 표현을 정확하게 처리 또는 오탈자 이해 및 정확한 키워드 파악을하는 데 탁월한 성능을 보입니다. 이는 GPT-4나 Llama 등의 글로벌 모델들이 제공하지 못하는 부분으로 한국어 기반 서비스에서 HCX의 활용 가치가 높다는 것을 의미합니다.
- 기대 효과
- 한국어 기반 AI 서비스의 품질 향상: HCX를 활용하여 사용자에게 더 자연스럽고 정확한 답변을 제공함으로써 서비스의 전반적인 품질 향상
- 문화적 맥락을 고려한 응답 제공: 한국의 역사, 문화, 지역적 특성을 고려한 응답을 통해 사용자에게 문화적으로 적합한 정보 제공
- 다양한 분야에서의 AI 활용 확대: 의료, 법률, 교육, 엔터테인먼트 등 한국어를 사용하는 다양한 분야에서 HCX를 활용한 맞춤형 AI 서비스 개발 가능
- 사용자 경험 개선: 한국어에 특화된 자연어 처리 능력을 통해 사용자 만족도와 신뢰도 상승
- 한국어 컨텐츠의 글로벌화 기여: HCX를 활용하여 한국어 컨텐츠를 다른 언어로 정확하게 번역하거나, 반대로 외국어 컨텐츠를 한국어로 자연스럽게 번역함으로써 글로벌 시장에서의 경쟁력 상승
- AI 연구 및 산업 발전 촉진: 한국어에 특화된 AI 모델의 개발과 활용은 국내 AI 산업의 기술 수준 향상과 신규 비즈니스 기회 창출에 기여
7. 결론
- 연구 요약
본 연구에서는 Neo4j 기반의 GraphRAG 구현과 CLOVA Studio를 활용한 Text2SQL 변환을 통해 OTT 플랫폼에서의 사용자 경험을 향상시키는 방법을 확인해 보았습니다. 기존 생성형 AI 모델들이 한국어 처리와 최신 데이터 반영에 한계가 있다는 점을 인식하고, 신뢰도 높은 답변을 제공하기 위해 최신화된 데이터를 활용하는 방안을 모색하였습니다. 특히, 데이터와 그 관계가 명확하고 구조화된 시나리오에서 탁월한 성능을 보이는 GraphRAG를 선택하여 데이터 무결성과 일관성을 보장하였습니다. 또한, 한국어에 특화된 HyperCLOVA X를 활용하여 Text2SQL 변환의 정확도와 효율성을 향상시켰습니다.
- 주요 발견 및 기여
- GraphRAG의 효과적인 활용: GraphRAG를 통해 빠르고 정확한 질의 처리가 가능함을 확인하였습니다.
- CLOVA Studio의 Text2SQL 변환 성능 향상: HyperCLOVA X를 튜닝하고 멀티 LLM 방식을 도입하여 Cypher 쿼리 생성의 정확도를 높였습니다. 이를 통해 비용 효율성을 높이면서도 원하는 성능을 달성할 수 있었습니다.
- 한국어 기반 AI의 우수성 입증: HyperCLOVA X는 한국어의 미묘한 표현과 문화적 맥락을 정확하게 이해하며 오탈자로부터 핵심 키워드를 정확히 추출하는 한국어 처리에 강점이 있음을 입증하였습니다. 이는 사용자에게 자연스럽고 정확한 답변을 제공하는 데 기여하였습니다.
- 실용적인 응용 분야 제시: 본 연구 결과는 OTT 플랫폼뿐만 아니라 전자상거래, 의료, 교육 등 다양한 산업에서의 적용 가능성을 제시하여 산업 전반에 걸친 활용 방안을 모색하였습니다.
- 추가 연구 방향 제안: MultiSQL과 같은 데이터셋을 활용하여 다양한 SQL 연산을 포함하는 문맥 의존적 Text2SQL 모델의 개발 필요성을 제시하였습니다. 이는 실제 데이터베이스 상호작용의 복잡성과 역동성을 더욱 정확하게 반영할 수 있습니다.
- 최종 의견
본 연구를 통해 Neo4j 기반 GraphRAG와 CLOVA Studio를 활용한 Text2SQL 변환이 구조화된 데이터 시나리오에서 신뢰도 높은 정보 제공에 효과적임을 확인하였습니다. 특히, 한국어에 특화된 HyperCLOVA X의 활용은 한국어가 사용되는 AI 서비스의 품질 향상에 중요한 역할을 하였습니다.