
안녕하세요. MANVSCLOUD 김수현입니다.
오랜만에 Amazon Web Services(AWS) 포스팅을 작성하게 되었습니다.
현대 기업들은 대용량의 데이터를 다루기 위해 클라우드 기반의 저장소를 활용하고 있습니다.
이러한 환경에서 데이터의 중요성은 점점 커지고 있으며, 이를 효과적으로 관리하고 활용하는 것이 기업의 경쟁력을 높이는 핵심 요소가 되었습니다.
이번 포스트에서는 Amazon SES를 사용하여 이메일을 통해 받은 데이터 중 CSV 파일만을 추출하고, Amazon S3에 저장하는 방법을 소개하려고 합니다. 이렇게 저장된 CSV 파일은 데이터 분석, 리포팅, 머신러닝 등 다양한 목적으로 활용될 수 있어 기업의 업무 효율성을 크게 향상시킬 수 있습니다.
Lambda부터 S3, SES 서비스까지 설정을 차례대로 진행해보겠습니다.
Get CSV File
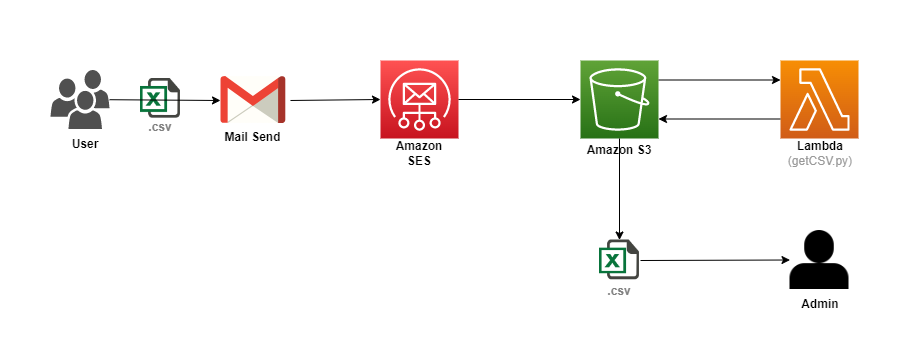
먼저 위 그림과 함께 Flow를 알아보자.
- Google, Naver 등 메일로 Amazon SES에 등록된 Email에게 CSV 파일을 첨부하여 보냅니다.
- Amazon SES(us-east-1)에서 메일을 수신합니다.
- 메일 수신 시 메일을 보관할 Mailbox가 필요한데 이를 Amazon S3로 지정합니다.
- Amazon S3에 메일이 보관되면 Lambda에서 보관된 파일에서 CSV 파일만 추출하여 다시 Amazon S3로 저장합니다.
- 관리자는 Amazon S3에 저장된 CSV 파일을 이용하여 다양하게 활용할 수 있습니다.
사용하여 메일을 수신하고, 이메일 데이터를 S3에 저장하는 방법을 설명합니다.
위 설정은 매우 간단합니다.
다만 수신된 이메일의 데이터는 그 자체로 많은 정보를 제공하기때문에 해당 포스팅을 통해 해당 파일에는 어떤 정보가 담겨있고 왜 내용이 인코딩되어 있는지, 메일이 어떻게 전송되는지 고민해보는 시간도 함께하길 바랍니다.
Lambda
먼저 Lambda 함수를 생성을 할텐데 미국 동부(버지니아 북부) us-east-1 리전에서 생성해줄 것입니다. 그 이유는 아래 Amazon SES 생성 시 알 수 있습니다.
런타임은 Python 3.9 버전으로 생성하며 IAM Role은 기본 Lambda 역할에 S3 읽기 및 쓰기 권한을 추가해주었습니다.
아래는 lambda_function.py 의 코드입니다.
import boto3
import base64
import csv
from datetime import datetime
from io import BytesIO
import pytz
def get_latest_s3_file(bucket_name, prefix, exclude_name):
s3 = boto3.client('s3')
objects = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix)['Contents']
# 필터링된 객체 목록 생성 (exclude_name 제외)
filtered_objects = [obj for obj in objects if exclude_name not in obj['Key']]
# 가장 최근의 수정된 파일 찾기
latest = max(filtered_objects, key=lambda x: x['LastModified'])
return latest['Key']
def get_lines_after_keyword(file_content, keyword, remove_words):
lines = file_content.split('\n')
result = ""
found_keyword = False
for line in lines:
if keyword in line:
found_keyword = True
if found_keyword:
# 모든 제거 대상 문자열이 없는지 확인
should_print = all(remove_word not in line for remove_word in remove_words)
# 줄의 앞뒤 공백을 제거한 후, 줄이 비어있지 않은지 확인
if should_print and line.strip():
result += line + '\n'
return result
def lambda_handler(event, context):
bucket_name = "버킷명"
prefix = "메일저장경로/"
exclude_name = "AMAZON_SES_SETUP_NOTIFICATION"
# 가장 최근 날짜의 파일 찾기
latest_file_key = get_latest_s3_file(bucket_name, prefix, exclude_name)
# S3에서 최신 파일 다운로드
s3 = boto3.client('s3')
s3_object = s3.get_object(Bucket=bucket_name, Key=latest_file_key)
file_content = s3_object['Body'].read().decode('utf-8')
keyword = "text/csv"
remove_words = ["Boundary-WM", "Content-Type", "Content-Disposition", "Content-Transfer-Encoding", "name=", "filename="]
encoded_data = get_lines_after_keyword(file_content, keyword, remove_words)
# base64 인코딩 해독 및 S3 업로드
if encoded_data:
decoded_data = base64.b64decode(encoded_data)
# 결과를 .csv 파일로 저장
current_time = datetime.now(pytz.timezone('Asia/Seoul'))
formatted_time = current_time.strftime('%Y%m%d%H%M%S')
output_filename = f"Data-{formatted_time}"
# 결과를 S3에 업로드
output_key = f"CSV저장경로/{output_filename}.csv"
s3.upload_fileobj(BytesIO(decoded_data), bucket_name, output_key)
return {
'statusCode': 200,
'body': f'Successfully processed and saved as {output_key}'
}
else:
return {
'statusCode': 200,
'body': f'Successfully processed but no "{keyword}" found in the file'
}
“위 코드에서 “버킷명”, “메일저장경로”, “CSV저장경로” 부분은 개인 환경에 맞게 수정하여 사용하자”
또한 Lambda에서는 pytz 모듈을 지원하지 않으므로 위 코드를 Lambda로 사용하기 위해서는 서버에서 pytz 모듈을 설치한 후 압축하여 .zip 파일을 Lambda 코드 소스에 업로드해주어야 합니다.
// 참고 pip install pytz -t . zip -r getCSV.zip .
메일 테스트 후 결과에서 알 수 있겠지만 Lambda 함수가 동작 시 S3에 저장될 추출된 CSV 파일은 S3에 Data-20230405093030.csv 와 같은 형태로 저장됩니다.
(Data-년월일시분초)
추가로 Lambda – 구성 – 일반 구성에서 제한 시간을 10초로 설정했습니다.
해당 코드 동작 시 6~7초의 소요 시간이 발생했기 때문에 6~7초보다 낮은 값일 경우 에러가 발생할 수 있습니다.
Amazon SES & S3
📌 S3 버킷 생성
먼저 S3 버킷을 생성해주고 SES가 S3에 Object를 Put할 수 있도록 생성된 S3버킷의 버킷 정책을 수정합니다.
방법은 아래 크게 두 가지 중에 하나를 선택하여 사용하면 됩니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowSESPuts",
"Effect": "Allow",
"Principal": {
"Service": "ses.amazonaws.com"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::버킷명/*",
"Condition": {
"StringEquals": {
"aws:Referer": "계정ID"
}
}
}
]
}
{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"AllowSESPuts",
"Effect":"Allow",
"Principal":{
"Service":"ses.amazonaws.com"
},
"Action":"s3:PutObject",
"Resource":"arn:aws:s3:::버킷명/*",
"Condition":{
"StringEquals":{
"AWS:SourceAccount":"계정ID",
"AWS:SourceArn": "arn:aws:ses:리전:계정ID:receipt-rule-set/규칙세트이름:receipt-rule/수신규칙이름"
}
}
}
]
}
추가로 S3 버킷 내에 폴더 두 개를 생성했습니다.
” 메일을 수신할 recv 이름을 가진 폴더 하나와 CSV파일을 저장할 csv 이름의 폴더 생성 “
📌 Amazon SES
Amazon SES는 수신이 가능한 리전에서 생성해주어야합니다.
발신의 경우 대부분의 리전에서 가능하지만 수신이 가능한 리전은 아래 세 가지로 한정되어있습니다.
- 미국 동부 (버지니아 북부) us-east-1
- 미국 서부 (오레곤) us-west-2
- 유럽 (아일랜드) eu-west-1
Amazon SES – 구성 – 이메일 수신에서 수신 규칙 세트를 설정해주어야합니다.
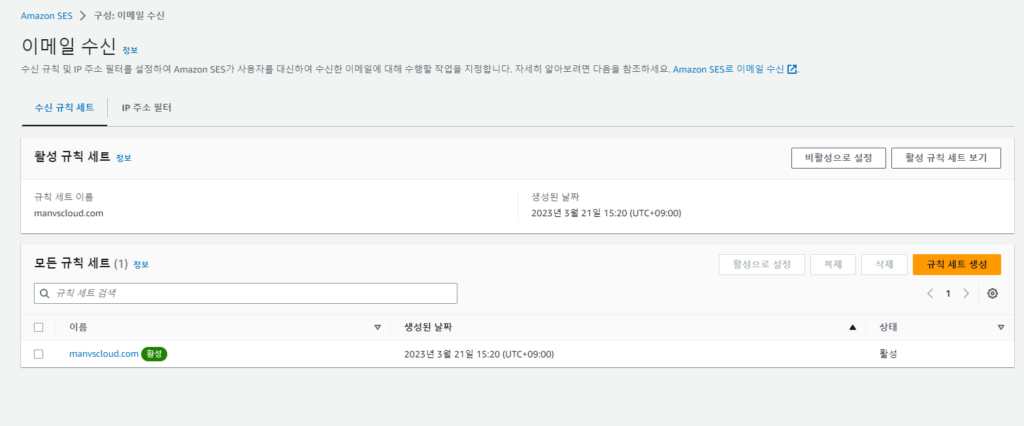
👇🏻 규칙 설정 예시
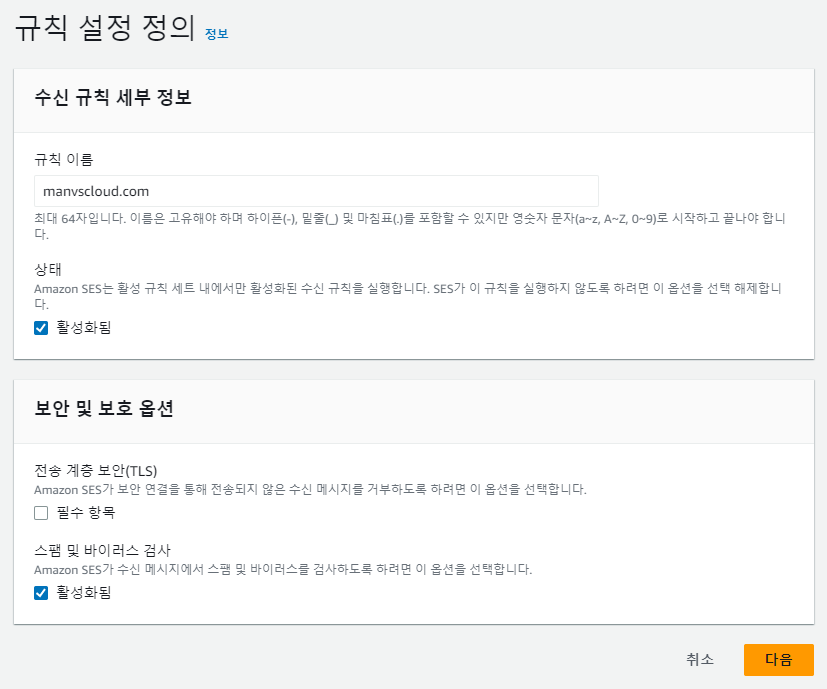
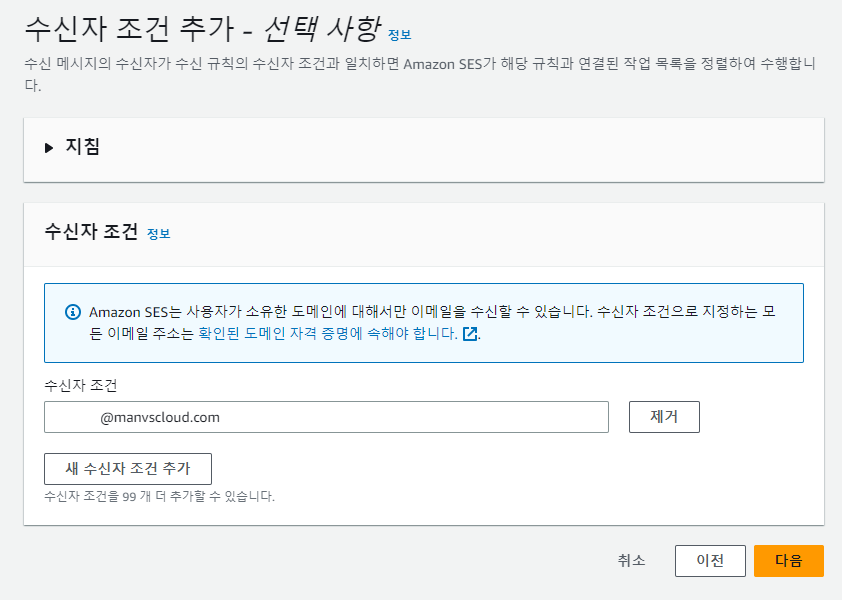
위 설정까지는 크게 어려운 부분은 없으나 아래 설정부터는 다양한 선택지가 생깁니다.
‘작업 추가’ 설정을 통해 Amazon SES가 수행하는 작업의 순서를 선택할 수 있는데 헤더를 추가하거나 Amazon Workmail과 연동하거나 Lambda 함수 호출 등 다양한 작업이 가능합니다.
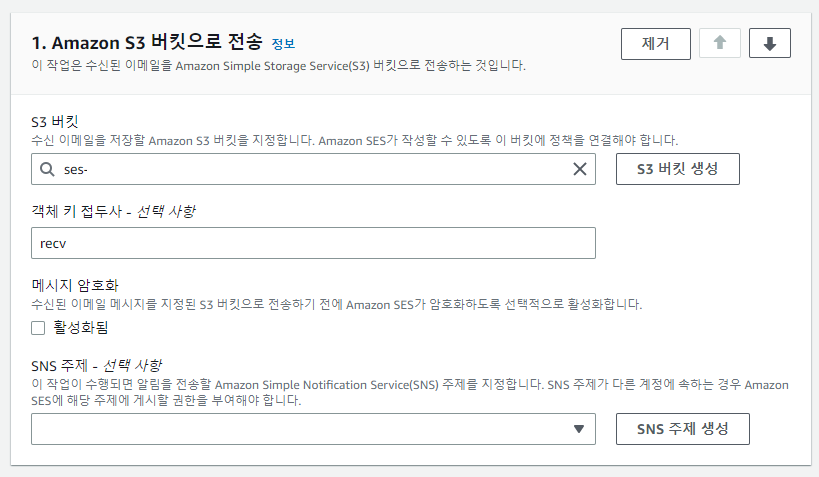
먼저 [Amazon S3 버킷으로 전송]을 첫번째 작업으로 선택해주고 위에서 생성한 S3 버킷 선택 및 객체 키 접두사에서는 이메일을 수신할 경로를 입력해줍니다.
해당 포스팅 과정에서 이 부분을 놓치는 경우 메일 테스트 시 “550 5.5.0 mailbox unavailable” 에러가 발생할 수 있습니다.
(수신 시 메일을 보관할 Mailbox를 지정해주지 않았기 때문)
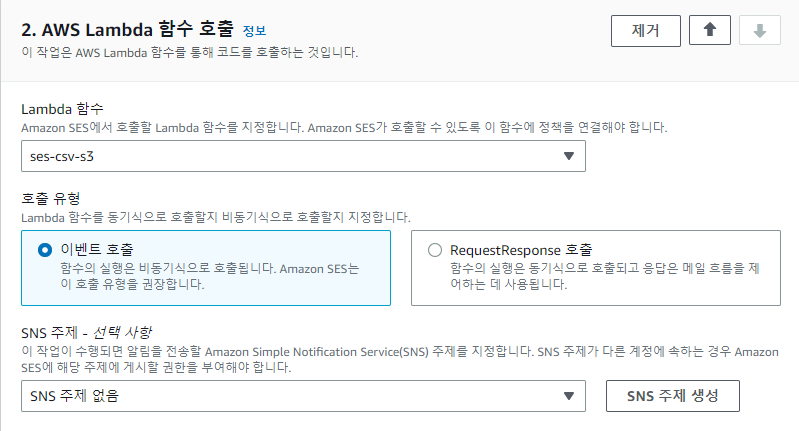
두번째 작업으로 [AWS Lambda 함수 호출]을 선택 후 위에서 생성해준 Lambda 함수가 호출되도록 설정해줍니다.
Amazon SES 설정이 완료되었다면 마지막으로 위 수신자 설정에 사용된 도메인의 네임서버에서 MX 레코드를 등록하여 메일 서버를 등록해주어야합니다.
10 inbound-smtp.REGION.amazonaws.com
Result
이제 메일 테스트를 진행할 것입니다.
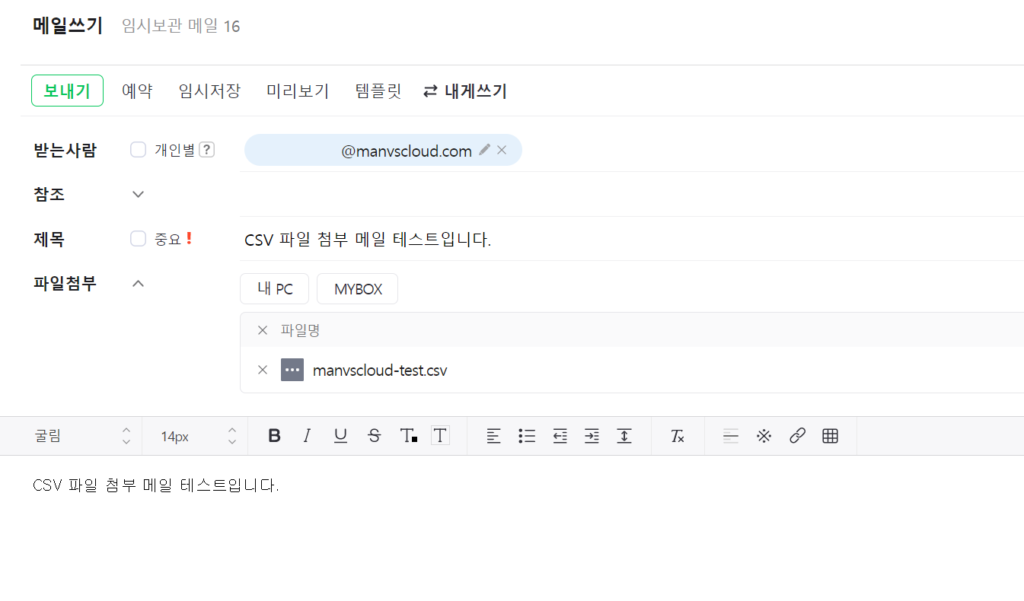
개인 메일에서 CSV 파일을 첨부하여 위 수신자로 등록한 이메일로 메일을 발송하고 정상적으로 발송이 되었다면 S3 버킷을 확인합니다.
<이메일이 저장되는 경로>
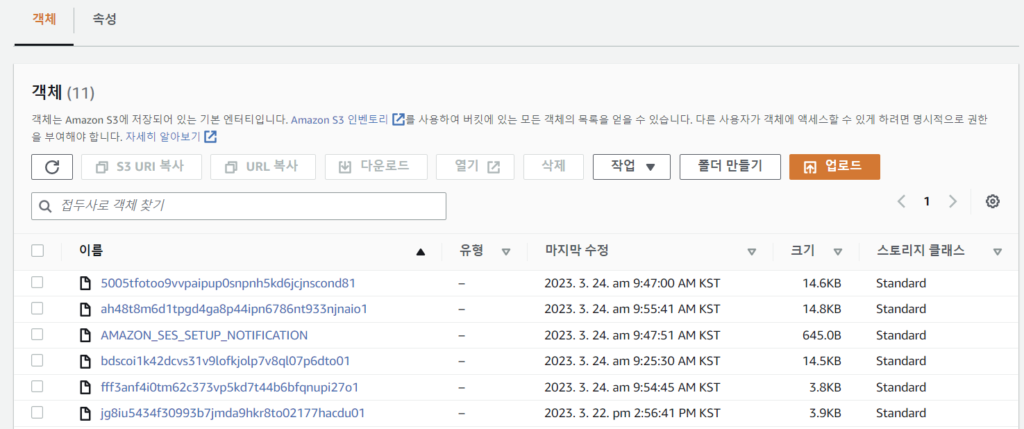
👇🏻 수신된 파일 내용 예시
Return-Path:
Received:
X-SES-Spam-Verdict:
X-SES-Virus-Verdict:
Received-SPF:
Authentication-Results:
X-SES-RECEIPT:
X-Originating-IP:
X-Works-Smtp-Source:
Received:
DKIM-Signature:
X-Session-ID:
Message-ID:
Date:
From:
Importance:
To:
Subject: 제목
X-Originating-IP:
X-Works-Send-Opt:
Content-Type: multipart/mixed;
boundary="-----Boundary-WM="
-------Boundary-WM=
Content-Type: multipart/alternative;
boundary="-----Boundary-WM="
-------Boundary-WM=
Content-Type: text/plain;
charset="utf-8"
-------Boundary-WM=
Content-Type: text/html;
charset="utf-8"
Content-Transfer-Encoding: base64
내용
-------Boundary-WM=
-------Boundary-WM=
Content-Type: text/csv;
name="=?utf-8?B?"
Content-Disposition: attachment;
filename="=?utf-8?B?"
Content-Transfer-Encoding: base64
첨부파일
-------Boundary-WM=
위 파일이 S3 버킷에 저장되면 Lambda는 해당 파일에서 Content-Type이 text/csv인 데이터만 추출하여 .csv 파일로 만들어 S3 버킷에 저장합니다.
<CSV 파일이 저장되는 경로>
해당 .csv 파일을 다운로드하여 파일을 열어보면 발신했던 .csv 파일과 동일한 것을 알 수 있습니다.
Personal Comments
해당 포스팅을 마무리 하기 전 위 과정을 따라온 독자들이 수신된 파일을 다운로드 받아 메일 내용을 확인했길 바라며 TMI를 더 끄적여보려고 합니다. 저장된 메일은 MIME 포맷 형식의 파일이며 해당 파일을 열어보면 메일의 내용이 무엇인지 첨부된 파일의 내용이 무엇인지 알 수 없었을 것입니다.
base64로 인코딩되었다는 사실은 Content-Transfer-Encoding: base64 을 보면 base 64로 인코딩되었다는 사실을 알 수 있는데 이메일 시스템에서 7비트 ASCII 문자열만을 지원하던 시절에 8비트 바이너리 데이터를 안전하게 전송할 필요성이 생겼고 이를 위해 Base64 인코딩이 도입되어 이메일에 첨부된 파일, 이미지, 문서 등의 바이너리 데이터를 안전하게 전송할 수 있게 되었습니다.
즉 base64 인코딩을 통해 바이너리 데이터를 6비트 단위로 나누고 각 6비트 블록에 대해 해당하는 ASCII 문자를 찾아 매핑하게 되는 것입니다.
마무리를 주제와 관련없는 TMI로 끝내게 되었는데 개인적으로 주니어 독자분들이 Python 코드만 복사하여 붙여넣지 않고 이러한 부분들도 놓치지 않길 바라며 작성하게 되었습니다.
긴 글 읽어주셔서 감사합니다.