
안녕하세요 MANVSCLOUD 김수현입니다.
데이터는 현대 비즈니스의 심장과도 같습니다. 기업들은 고객 정보, 거래 내역, 운영 데이터 등을 실시간으로 처리하고 이 데이터는 그들의 의사결정과 서비스 품질을 결정짓는 중요한 요소가 되고 있습니다. 그래서 데이터의 안전한 보관과 신속한 복구는 어느 때보다 중요한 과제가 되었습니다.
네이버 클라우드뿐만 아니라 AWS 등 관리형 데이터베이스 서비스 자체 기능에서는 기본적으로 하루 특정 시간에 1회 백업이 진행되도록 설정이 가능한데요.
요구 사항에 따라 하루에 한 번의 백업이 충분하지 않을 수 있습니다.
예를 들어 매우 빈번하게 데이터가 변경되거나 실시간 데이터 처리가 중요한 비즈니스에서는 더 자주 데이터를 백업할 필요가 있습니다.
오늘 포스팅은 네이버 클라우드의 Cloud DB For MSSQL 서비스에서 시간 단위로 데이터를 백업하는 방법을 소개하려고 합니다. 이는 장애 발생 시 데이터 복구 시점의 정확성을 높이고 데이터 손실의 위험을 최소화하는 데 도움이 되며 이러한 백업 전략은 비즈니스 연속성과 데이터 무결성을 보장하는 데 핵심적인 요소가 될 것입니다.
시작하기 전에…
- 이 포스팅에서는 VPC, Server, Cloud DB for MSSQL, Object Storage 생성에 관련해서는 설명하지 않습니다.
- 아래 URL(데이터 마이그레이션(백업 복구))를 먼저 확인할 경우 이해하기 쉽습니다.
Cloud DB for MSSQL 백업 서버 구성
위 데이터 마이그레이션(백업 복구) 가이드에서도 나와있듯이 백업용 서버가 따로 필요합니다.
→ Cloud DB For MSSQL에서는 일별 단위 백업만 가능하기 때문.
백업 서버를 따로 구성하는 것까지는 가이드와 동일하지만 비용 최적화를 위해 OS 및 저장 방식 등을 다양하게 고려하였습니다.
1) 서버 생성
OS : Ubuntu 20.04 (KVM)
스펙 : Micro (mi1-g3)
Windows 서버에 High-CPU 최소 스펙인 2vCPU, 4Memory 서버를 추가한다면 MSSQL 백업때문에 월 10만원의 비용이 추가로 발생하게 될 것입니다. 따라서 이를 최소화하기 위해 OS를 Ubuntu를 사용하기로 했고 Micro Type으로 생성하였습니다.
→ High-CPU 타입에 Windows로 생성한다면 월 약 10만원, Micro 타입에 Ubuntu로 생성 시 월 1만원대에서 해결 가능
→ 물론 아래 모든 백업 과정을 서버 시작 시에 동작하게하고 백업이 끝나면 서버를 종료되도록 하겠다라고 한다면 서버 스펙을 High-CPU로 변경하여 사용할 수 있습니다.
(Micro Type은 시간 요금제가 불가능하므로 High-CPU로 선택해야 시간 요금제 가능)
2) Samba 구축
- Samba 설치
apt update apt install samba
- Samba 설정
cp -avp /etc/samba/smb.conf /etc/samba/smb.conf_org vi /etc/samba/smb.conf
cmb.conf에 아래 내용 추가
[backup] path = /backup browsable = yes writable = yes guest ok = yes create mask = 0777 directory mask = 0777
- 공유할 디렉토리 생성 및 권한 추가
mkdir /backup chmod 777 /backup
- Samba 재시작
systemctl restart smbd
3) aws cli 사전 준비
- aws cli 설치
apt install pip pip install awscli==1.15.85
- 인증 정보 설정
aws configure AWS Access Key ID [None]: ACCESS_KEY_ID AWS Secret Access Key [None]: SECRET_KEY Default region name [None]: Default output format [None]:
4) sqlcmd 설치
wget -qO- https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add - add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2019.list)"
curl https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add - curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list | sudo tee /etc/apt/sources.list.d/msprod.list
apt install mssql-tools unixodbc-dev
5) ACG(Access Control Group) 설정
- Backup 서버 ACG 설정
아래와 같이 Cloud DB for MSSQL 서버에서 Backup 서버로 TCP 445 Inbound 통신이 가능하도록 추가해줍니다. (Backup 서버에 연결된 ACG에서 설정)
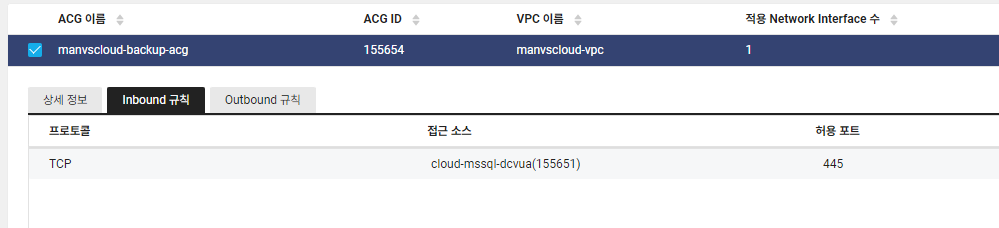
- Cloud DB for MSSQL ACG 설정
아래와 같이 Cloud DB for MSSQL 서버에서 Backup 서버로 TCP 445 Outbound 통신이 가능하도록 추가해줍니다. (Cloud DB for MSSQL 서버에 연결된 ACG에서 설정)
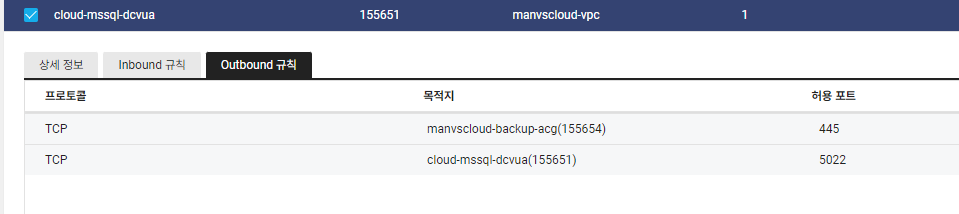
6) 스크립트 작성
- 쉘 스크립트 생성
vi ms_backup.sh
아래 샘플 스크립트를 참고하여 작성
#!/bin/bash
# Slack Webhook URL
SLACK_WEBHOOK_URL="WEBHOOK_URL"
# SQL Server 접속 정보
SERVER='MSSQL_PRIVATE_DOMAIN'
DATABASE='DATABASE_NAME'
USER='USERNAME'
PASSWORD='PASSWORD'
# 백업 파일 경로 설정
BACKUP_PATH='\\BACKUP_SERVER_IP\backup\'
BACKUP_FILE_NAME="manvscloud_$(date +%Y%m%d_%H%M%S).bak"
BACKUP_FILE_FULL_PATH="${BACKUP_PATH}${BACKUP_FILE_NAME}"
LOCAL_BACKUP_PATH='/backup/'
LOCAL_FILE_FULL_PATH="${LOCAL_BACKUP_PATH}${BACKUP_FILE_NAME}"
# Object Storage 경로
S3_PATH="s3://OBJECT_STORAGE_NAME/$(date +%Y)/${BACKUP_FILE_NAME}"
# SQL Server 백업 명령
SQLCMD="/opt/mssql-tools/bin/sqlcmd"
QUERY="BACKUP DATABASE [$DATABASE] TO DISK = N'$BACKUP_FILE_FULL_PATH'"
# 백업 실행
$SQLCMD -S $SERVER -U $USER -P $PASSWORD -Q "$QUERY"
# 백업 성공 확인 및 Object Storage로 이동
if [ $? -eq 0 ]; then
# AWS CLI를 사용하여 백업 파일을 Object Storage로 전송
aws --endpoint-url=https://kr.object.ncloudstorage.com s3 cp "$LOCAL_FILE_FULL_PATH" "$S3_PATH"
if [ $? -eq 0 ]; then
curl -X POST --data-urlencode "payload={\"text\": \"백업 및 파일 업로드가 정상적으로 완료되었습니다.\"}" $SLACK_WEBHOOK_URL
rm -f "$LOCAL_FILE_FULL_PATH"
else
curl -X POST --data-urlencode "payload={\"text\": \"백업에 성공했으나 Object Storage로 파일 업로드가 실패했습니다.\"}" $SLACK_WEBHOOK_URL
fi
else
curl -X POST --data-urlencode "payload={\"text\": \"백업에 실패했습니다.\"}" $SLACK_WEBHOOK_URL
fi
WEBHOOK_URL, MSSQL_PRIVATE_DOMAIN, DATABASE_NAME, USERNAME, PASSWORD, BACKUP_SERVER_IP, OBJECT_STORAGE_NAME 을 각자 환경에 맞게 입력해줘야합니다.
또한 S3_PATH 부분에서 $(date +%Y)는 제가 Object Storage에서 아래 이미지와 같이 연도별 폴더를 만들어뒀기때문입니다.
스크립트를 수정하여 연도별, 월별 등 세분화하고 폴더가 없을 경우 폴더를 생성하도록 할 수도 있습니다.
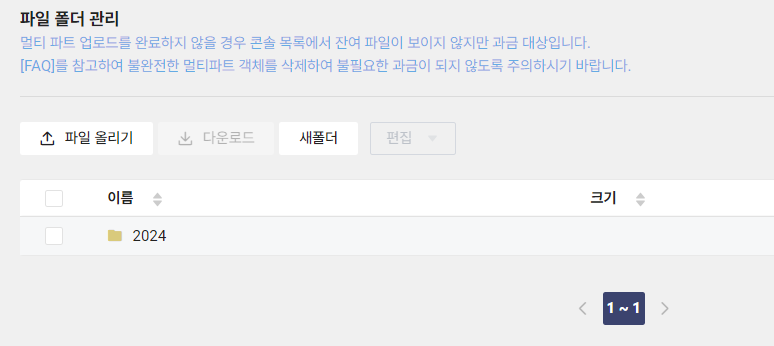
7) 스크립트 실행 및 확인
- 스크립트 실행
스크립트가 작성되었다면 스크립트를 실행합니다.
sh ms_backup.sh
스크립트 실행 시 백업 및 파일 업로드가 진행되며 성공/실패에 대해서 아래와 같이 Slack으로 알림도 받을 수 있습니다.
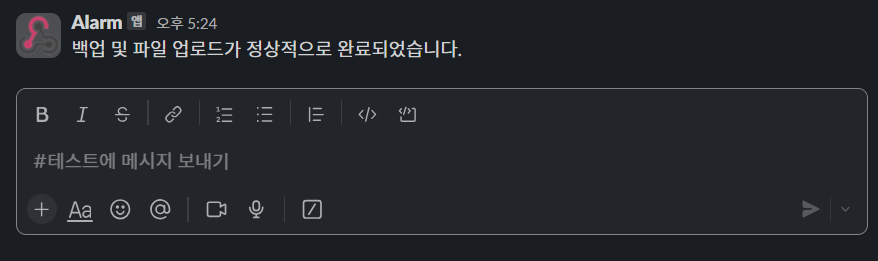
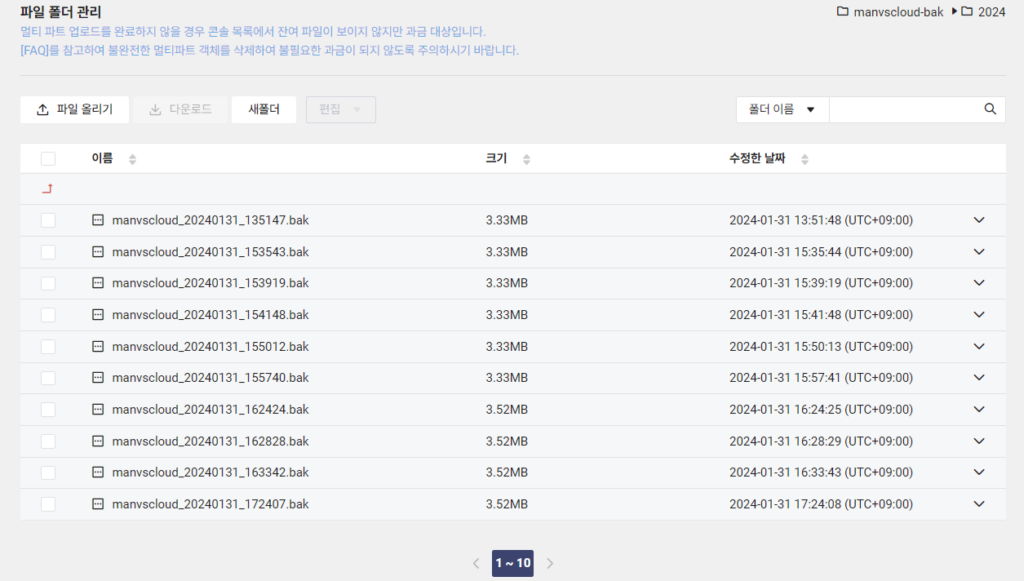
정말 백업이 되었는지, 파일 업로드가 되었는지도 Object Storage 버킷에서 확인해보면 아래와 같이 백업 파일이 업로드되어 있는 것을 확인할 수 있습니다.
이제 해당 스크립트를 crontab을 이용하여 원하는 시간대마다 실행되도록 설정해주면 시간별 백업이 가능합니다. 또한 Object Storage의 LifeCycle Management 기능을 이용하여 오래된 백업 파일은 삭제되도록 관리도 할 수 있습니다.
- crontab 예시
매일 3시간마다 /root/ms_backup.sh 스크립트 실행
0 */3 * * * root sh /root/ms_backup.sh
Block Storage에 비해 Object Storage가 데이터 저장 비용이 싸고 Block Storage의 경우 고정 최대 용량을 계속 유지하여 비용이 나가는 반면 Object Storage는 사용한 데이터 저장량만큼 비용이 발생하기때문에 비용을 더욱 최적화할 수 있습니다.
마지막으로 생성된 백업 파일을 이용하여 복구를 진행해보고 싶으시다면 데이터 마이그레이션(백업 복구) 가이드를 참고하여 진행해보시면 될 것같습니다.
(개인적으로 복구 테스트 시 정상 복구되었습니다.)
Personal Comments
데이터는 모든 비즈니스의 핵심이며 그 보호는 필수적입니다. 이 포스팅에서 말하고자하는 자동 백업 및 알림 시스템은 데이터를 안전하게 유지하는 데 중요한 역할을 할 것입니다. 이 글에 작성된 시간 단위 백업 방법이 정답은 아니지만 선택할 수 있는 하나의 방법이 되길 바랍니다.
긴 글 읽어주셔서 감사합니다.
