
안녕하세요 MANVSCLOUD 김수현입니다.
보안은 클라우드 환경에서 가장 중요한 요소 중 하나입니다. 특히 데이터베이스 암호와 같은 중요한 보안 정보를 안전하게 관리하는 것은 매우 중요합니다. 오늘은 네이버 클라우드의 Secret Manager를 활용하여 Cloud DB for PostgreSQL에서 사용되는 사용자 패스워드를 효과적으로 관리하는 방법을 소개해드리고자 합니다.
현재 네이버 클라우드 공식 가이드에서는 Secret Manager를 이용한 Cloud DB for MySQL 패스워드 관리 방법이 제공되고 있습니다. 이 포스팅에서는 Cloud DB for PostgreSQL에 초점을 맞추어 작성하여 약간의 코드 수정만으로 다양한 서비스에도 적용할 수 있다는 점을 공유드리고자 합니다.
왜 Secret Manager를 사용해야 할까?

네이버 클라우드에서 데이터베이스의 사용자 패스워드를 관리할 때 Secret Manager를 사용하면 좋은 점은 크게 세 가지로 요약할 수 있습니다.
- 보안 강화: 민감한 자격 증명이 소스 코드에 하드코딩되거나 환경 변수에 노출되는 위험을 제거합니다.
- 자동 교체 지원: Secret Manager에서 자동 교체 주기를 설정하면 데이터베이스 패스워드가 정기적으로 변경되어도 애플리케이션 코드를 수정할 필요 없이 항상 최신 자격 증명을 사용할 수 있습니다. 따라서 보안 정책 준수와 함께 운영 부담도 크게 줄여줍니다.
- 중앙화된 자격 증명 관리: 모든 비밀번호와 API 키를 한 곳에서 통합 관리함으로써 운영 효율성을 높이고 액세스 제어 및 감사를 더욱 수월하게 할 수 있습니다. 또한 여러 시스템과 애플리케이션에서 일관된 방식으로 보안 정보에 접근할 수 있습니다.
Secret Manager 설정하기
Secret Manager의 설정은 크게 어렵지 않습니다.
네이버 클라우드 콘솔에서 간단하게 생성할 수 있으며 생성 시 두 가지 설정만 잘 선택 및 입력해주도록 합시다.
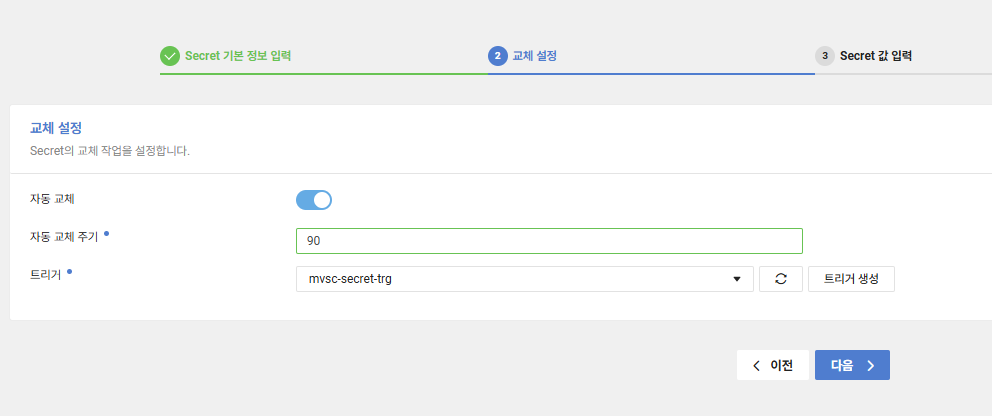
첫째로 “교체 설정” 부분입니다. 교체 설정에서는 Secret의 자동 교체 기능을 활성화하고 교체 주기를 정의할 수 있습니다.
- 교체 주기: 최소 1일부터 최대 730일(약 2년)까지 설정 가능합니다. 조직 내 보안 정책에 맞는 주기로 설정하면 됩니다.
- 트리거 추가: 교체 프로세스를 실행할 트리거를 반드시 추가해야 합니다. 이 트리거는 나중에 Cloud Functions에 연결되어 실제 패스워드 변경 작업을 수행할 때 사용합니다.
둘째는 “Secret 값 입력” 부분입니다.
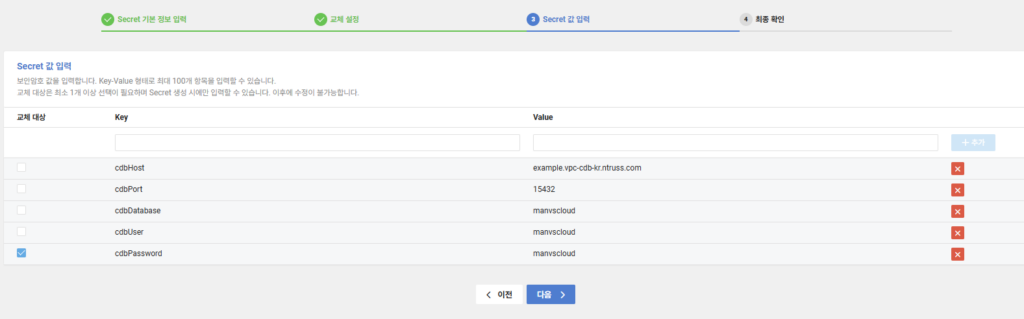
Secret 값 입력 부분에서는 다음과 같은 키-값(Key-Value) 쌍을 설정합니다.
- cdbHost: Cloud DB for PostgreSQL의 호스트 주소 (예:
example.vpc-cdb-kr.ntruss.com) - cdbPort: PostgreSQL 서버의 포트 번호 (기본값: 5432 또는 커스텀 포트)
- cdbDatabase: 연결할 데이터베이스 이름
- cdbUser: 데이터베이스 접속 사용자 이름
- cdbPassword: 데이터베이스 사용자의 현재 패스워드
여기서 중요한 점은 교체 대상 항목을 선택하는 것입니다. 위 예시에서는 cdbPassword 항목만 교체 대상으로 체크했습니다. 이렇게 설정하면 교체 주기에 따라 cdbPassword 값(Value)만 새 값(Value)으로 변경되며 Cloud Functions이 동작하면서 Cloud DB for PostgreSQL의 실제 사용자 패스워드도 함께 업데이트됩니다.
이렇게 설정함으로써 데이터베이스 패스워드를 수동으로 주기적으로 변경하고 추적하는 번거로움 없이 Secret Manager에서 자동으로 모든 것을 관리할 수 있게 됩니다.
이제 Secret Manager가 설정되었으니 실제로 Secret이 자동 교체될 때 Cloud DB for PostgreSQL의 사용자 패스워드도 함께 변경되도록 Cloud Functions을 구성해보겠습니다.
- Custom Image 준비하기
기본 Cloud Functions 환경에는 PostgreSQL 연결에 필요한 라이브러리가 포함되어 있지 않습니다. 따라서 필요한 라이브러리가 포함된 커스텀 이미지를 먼저 생성해야 합니다. 이를 위해 Container Registry를 활용하겠습니다.
(이 포스팅에서는 Container Registry 생성 가이드는 제공하지 않습니다.)
다음은 PostgreSQL 클라이언트 라이브러리가 포함된 Dockerfile 예시입니다.
FROM cloudfunctions.kr.ncr.ntruss.com/cloudfunctions-python-3.7:latest RUN dnf install -y python3.11 && dnf remove -y python37 RUN rm -f /usr/local/bin/python RUN ln -s /usr/bin/python3.11 /usr/local/bin/python RUN dnf install -y python3.11-pip RUN /usr/bin/pip3.11 install psycopg2-binary RUN /usr/bin/pip3.11 install requests WORKDIR / ENTRYPOINT ["/bin/proxy"]
네이버 클라우드에서 기본 이미지로 제공하는 Python 3.7 버전 기본 이미지를 먼저 가져와서 사용했습니다. Python 3.11 버전을 사용할 수 있도록 기존 Python 제거 및 3.11 버전으로 설치해주고 pip를 이용하여 필요한 라이브러리(psycopg2-binary)를 설치해줬습니다.
# 네이버 클라우드 Container Registry에 로그인 docker login 레지스트리_이름.kr.ncr.ntruss.com # 이미지 빌드 docker build -t 레지스트리_이름.kr.ncr.ntruss.com/secret-manager-psql:1.0 . # 이미지 푸시 docker push 레지스트리_이름.kr.ncr.ntruss.com/secret-manager-psql:1.0
Dockerfile이 생성되었다면 네이버 클라우드에 사전에 생성해둔 Container Registry에 로그인하고 이미지 Build 및 Push를 해줍니다.
- Cloud Functions Action 생성
이제 커스텀 이미지를 사용하는 Cloud Functions를 생성합니다.
Cloud Functions 생성 시 다음 사항을 설정해주세요.
1) 런타임 환경: 커스텀 이미지 선택 후 위에서 푸시한 이미지 지정
2) 트리거 연결: Secret Manager에서 설정한 트리거 선택
3) 기본 파라미터:
{
"secretId": "생성한 Secret Manager의 ID",
"accessKey": "Secret Manager 권한을 가진 액세스 키",
"secretKey": "Secret Manager 권한을 가진 시크릿 키"
}
- Cloud Functions Action Code
: 코드는 네이버 클라우드 가이드에서 제공하는 ‘MySQL 패스워드 ‘Cloud DB for MySQL에서 패스워드(cdbPassword)를 단일 교체 대상으로 설정한 상태에서 교체를 실행하는 파이썬 액션 예시 코드’를 Cloud DB for PostgreSQL로 변경한 코드입니다.
주석(#)처리 한 부분을 이해하고 PostgreSQL뿐만 아니라 코드를 수정하여 다른 데이터베이스에도 다양하게 활용하실 수 있습니다.
import hmac
import hashlib
import base64
import json
import requests
# MySQL 라이브러리에서 PostgreSQL 라이브러리로 변경
# import mysql.connector
# from mysql.connector import Error
import psycopg2
from psycopg2 import Error
import time
# Constants
ACCESS_KEY = None
SECRET_KEY = None
BASE_URL = None
JOB_TOKEN = None
def init_requests(secret_id, job_token, access_key, secret_key):
global BASE_URL, JOB_TOKEN, API_KEY, ACCESS_KEY, SECRET_KEY
BASE_URL = f"https://secretmanager.apigw.ntruss.com/action/v1/secrets/{secret_id}/jobs/{job_token}"
JOB_TOKEN = job_token
ACCESS_KEY = access_key
SECRET_KEY = secret_key
def make_signature(method, url, timestamp):
message = f"{method} {url}\n{timestamp}\n{ACCESS_KEY}"
signing_key = SECRET_KEY.encode('utf-8')
mac = hmac.new(signing_key, message.encode('utf-8'), hashlib.sha256)
return base64.b64encode(mac.digest()).decode('utf-8')
def main(args):
secret_id = args["secretId"]
job_token = args["jobToken"]
access_key = args["accessKey"]
secret_key = args["secretKey"]
result = {}
skip_update_pending = False
try:
init_requests(secret_id, job_token, access_key, secret_key)
print(f"[Secret Rotation Job (secret_id={secret_id})]")
secret_value_response = start_rotation()
print("[STEP1 COMPLETE] start rotation")
secret_value = secret_value_response["data"]
secret_chain = secret_value["decryptedSecretChain"]
rotation_targets = secret_value["rotationTargets"]
# Step 2: Generate secret value
if "pending" not in secret_chain or secret_chain["pending"] is None:
pending = {
"cdbHost": json.loads(secret_chain["active"])["cdbHost"],
"cdbPort": json.loads(secret_chain["active"])["cdbPort"],
"cdbUser": json.loads(secret_chain["active"])["cdbUser"],
"cdbDatabase": json.loads(secret_chain["active"])["cdbDatabase"],
"cdbPassword": set_secret_value()
}
secret_chain["pending"] = json.dumps(pending)
print("[STEP2 COMPLETE] update pending")
else:
skip_update_pending = True
print("[STEP2 SIKP] already exist pending")
change_password(secret_chain, rotation_targets)
print("[STEP3 COMPLETE] rotate secret")
test_password(secret_chain, rotation_targets)
print("[STEP4 COMPLETE] test secret")
# Step 5: Update Pending
if skip_update_pending:
print("[STEP5 SKIP] update pending")
else:
update_pending(secret_chain, rotation_targets)
print("[STEP5 COMPLETE] update pending")
complete_rotation()
print("[STEP6 COMPLETE] complete rotation")
result["done"] = True
result["pending"] = secret_chain["pending"]
except Exception as ex:
print(str(ex))
fail_rotation()
result["done"] = False
result["error_message"] = str(ex)
print(json.dumps(result, indent=4))
return result
def start_rotation():
return execute_request("/start", {}, "POST")
def set_secret_value():
req_body = {
"length": 16,
"excludeCharacters": "\"&'+/\\`",
"requireEachIncludedType": True
}
response = execute_request("/generate-random-secret", req_body, "POST")
print(json.dumps(response, indent=4))
return response.get("randomString")
def change_password(secret_chain, rotation_targets):
if not rotation_targets:
raise ValueError("rotationTargets is empty")
rotation_target = rotation_targets[0]
active_value = json.loads(secret_chain["active"])
cdb_host = active_value["cdbHost"]
cdb_database = active_value["cdbDatabase"]
cdb_user = active_value["cdbUser"]
cdb_port = int(active_value["cdbPort"])
print(f"cdbHost: {cdb_host}, cdbDatabase: {cdb_database}, cdbUser: {cdb_user}, cdbPort: {cdb_port}")
if "pending" not in secret_chain:
raise ValueError("error_message: pending is None")
update_password(cdb_host, cdb_port, cdb_user, cdb_database, rotation_target, secret_chain)
def update_password(cdb_host, cdb_port, cdb_user, cdb_database, rotation_target, secret_chain):
active = json.loads(secret_chain["active"])
previous = json.loads(secret_chain.get("previous", "{}"))
pending = json.loads(secret_chain["pending"])
pending_password = pending[rotation_target]
try:
conn = try_connection(cdb_host, cdb_port, cdb_user, pending_password, cdb_database, "pending")
if conn:
conn.close()
return
active_password = active[rotation_target]
conn = try_connection(cdb_host, cdb_port, cdb_user, active_password, cdb_database, "active")
if conn:
update_db_password(conn, cdb_user, pending_password)
return
if "previous" in secret_chain:
previous_password = previous.get(rotation_target)
conn = try_connection(cdb_host, cdb_port, cdb_user, previous_password, cdb_database, "previous")
if conn:
update_db_password(conn, cdb_user, pending_password)
else:
raise ValueError("All Secret Values are not valid")
except Error as ex:
print("[STEP3 ERROR]", ex)
raise
def try_connection(cdb_host, cdb_port, cdb_user, password, cdb_database, password_type):
print(f"Connecting using the {password_type} password")
return db_connect(cdb_host, cdb_port, cdb_user, password, cdb_database)
def update_db_password(conn, cdb_user, new_password):
# MySQL 쿼리를 PostgreSQL 쿼리로 변경
# query = f"ALTER USER '{cdb_user}'@'%' IDENTIFIED BY '{new_password}'"
query = f"ALTER USER {cdb_user} WITH PASSWORD '{new_password}'"
cursor = conn.cursor()
cursor.execute(query)
# PostgreSQL에서도 commit 필요
conn.commit()
cursor.close()
def test_password(secret_chain, rotation_targets):
rotation_target = rotation_targets[0]
pending_value = json.loads(secret_chain["pending"])
pending_password = pending_value[rotation_target]
active_value = json.loads(secret_chain["active"])
cdb_host = active_value["cdbHost"]
cdb_database = active_value["cdbDatabase"]
cdb_user = active_value["cdbUser"]
cdb_port = int(active_value["cdbPort"])
conn = db_connect(cdb_host, cdb_port, cdb_user, pending_password, cdb_database)
if conn is None:
raise ValueError("error_message: connection failed")
conn.close()
def update_pending(secret_chain, rotation_targets):
rotation_target = rotation_targets[0]
non_change_values = json.loads(secret_chain["active"])
cdb_host = non_change_values["cdbHost"]
cdb_database = non_change_values["cdbDatabase"]
cdb_user = non_change_values["cdbUser"]
cdb_port = non_change_values["cdbPort"]
pending = {
"cdbHost": cdb_host,
"cdbPort": cdb_port,
"cdbUser": cdb_user,
"cdbDatabase": cdb_database,
"cdbPassword": json.loads(secret_chain["pending"])[rotation_target]
}
req_body = {
"value": json.dumps(pending)
}
execute_request("/pending", req_body, "PUT")
def complete_rotation():
execute_request("/complete", {}, "POST")
def fail_rotation():
try:
execute_request("/fail", {}, "POST")
except Exception as ex:
print("[FAIL ROTATION NOTIFICATION ERROR]", ex)
def execute_request(endpoint, request_body, method):
url = BASE_URL + endpoint
print("Request url:", url)
timestamp = str(int(time.time() * 1000))
headers = {
"Content-Type": "application/json",
"x-ncp-apigw-timestamp": timestamp,
"x-ncp-iam-access-key": ACCESS_KEY,
"x-ncp-apigw-signature-v2": make_signature(method, url.replace("https://secretmanager.apigw.ntruss.com", ""), timestamp),
"SECRET-JOB-TOKEN": JOB_TOKEN
}
if method == "POST":
response = requests.post(url, headers=headers, json=request_body)
elif method == "PUT":
response = requests.put(url, headers=headers, json=request_body)
else:
raise ValueError("Invalid HTTP method")
response_body = response.json()
print("Request Body:", request_body)
print("Response Body:", response_body)
if response.status_code != 200:
raise Exception(f"Unexpected response {response.status_code}")
return response_body
def db_connect(cdb_host, cdb_port, cdb_user, cdb_pass, cdb_database):
try:
# MySQL 연결 코드를 PostgreSQL 연결 코드로 변경
# connection = mysql.connector.connect(
# host=cdb_host,
# port=cdb_port,
# user=cdb_user,
# password=cdb_pass,
# database=cdb_database
# )
connection = psycopg2.connect(
host=cdb_host,
port=cdb_port,
user=cdb_user,
password=cdb_pass,
dbname=cdb_database
)
print("Database connection established successfully")
return connection
except Error as e:
print("Database connection failed:", e)
return None
Action 실행 전 필수 설정 중 하나로 Cloud Functions이 Cloud DB for PostgreSQL에 연결할 수 있도록 네트워크 설정을 해야 합니다. Cloud DB for PostgreSQL의 ACG(Access Control Group)에서 Cloud Functions이 실행되는 서브넷 대역을 허용해주세요. Cloud Functions이 Cloud DB for PostgreSQL에 접근하여 패스워드를 변경할 수 있도록요!
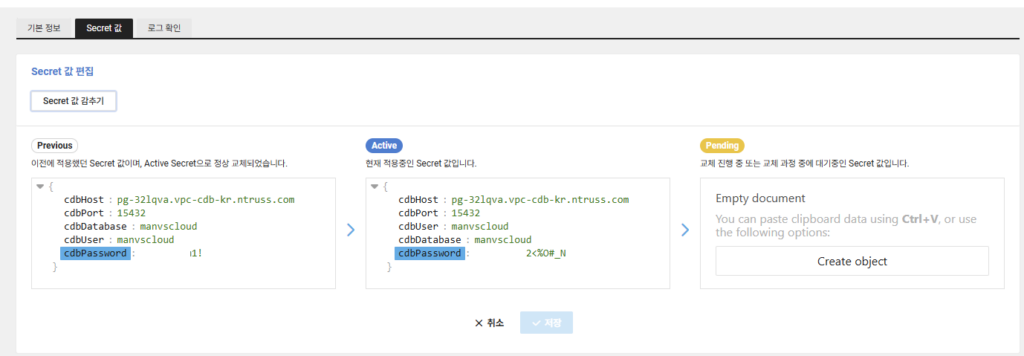
모든 설정이 완료되었다면 Secret Manager에서 수동으로 [교체 실행] 버튼을 클릭하여 전체 프로세스를 테스트해볼 수 있습니다. 정상적으로 Secret이 교체되었다면 아래와 같이 ‘cdbPassword’ 부분이 변경되어 이전 패스워드가 [Previous]에 새로 변경된 패스워드가 [Active]에 있는 것을 알 수 있습니다. (Secret 교체 후 변경된 패스워드로도 접속해보세요!)
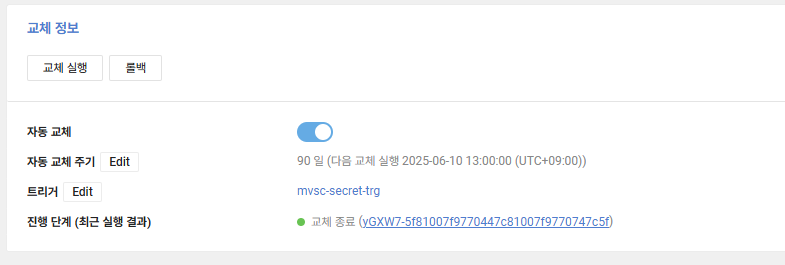
또한 교체가 정상적으로 진행되었다면 아래와 같이 진행 단계에서 오류 없이 정상 교체 종료 상태를 볼 수 있습니다. 만약 실패했다면 로그 확인이 가능하니 로그를 확인하여 원인 파악도 할 수 있습니다.
Personal Comments
이 포스팅에서는 네이버 클라우드의 Secret Manager를 사용하여 Cloud DB for PostgreSQL의 패스워드를 안전하고 자동화된 방식으로 관리하는 방법을 알아보았습니다.
Secret Manager와 Cloud Functions의 조합은 클라우드 환경에서 자격 증명 관리를 현대화하고 보안을 강화하는 강력한 방법입니다. 이러한 접근 방식은 금융, 의료, 공공 부문과 같이 규제가 엄격한 산업에서 특히 유용하며 보안 모범 사례를 준수하는 데 큰 도움이 됩니다.
Secret Manager의 활용은 단순히 데이터베이스 패스워드 관리에 국한되지 않습니다. API 키, OAuth 클라이언트 시크릿, 인증서 등 다양한 보안 자격 증명을 관리하는 데도 동일한 패턴을 적용할 수 있는 점 참고하면 좋을 것같습니다 🙂
긴 글 읽어주셔서 감사합니다.