
안녕하세요 MANVSCLOUD 김수현입니다.
머신러닝과 인공지능 기술이 빠르게 발전하고 이제는 이러한 기술들이 일상 속에서 함께하는 경우가 많습니다.
비록 제가 클라우드 엔지니어지만 AI/ML 기술의 발전에 따라 이 분야에도 자연스럽게 관심이 생겼습니다. 더 넓은 범위의 클라우드 서비스를 다루고 싶은 욕구가 커졌고 이를 위한 학습이 필요하다고 느꼈습니다. 처음 머신러닝을 배우는 입문자 입장에서 이론적인 개념들은 즉각적으로 이해하기 어려웠기에 빠르게 실제 프로젝트를 통한 경험으로 흥미를 얻고자 했습니다.
예전같았으면 AI/ML에 대한 지식이 거의 없고 개발자가 아니라는 점이 시작하는 데 큰 장벽으로 느꼈겠지만 요즘은 바이브 코딩이 일상이라 엔지니어 입장에서도 의지만 있다면 무엇이든 시작할 수 있다고 생각합니다.
오늘 포스팅에서는 AI/ML 경험이 없던 제가 네이버 클라우드 환경을 활용하여 돼지감자를 식별하는 딥러닝 기반 추론 모델을 개발하며 스터디했던 과정을 소개하고자 합니다.
스터디 개요
- 이미지 분류 모델 개발: 돼지감자와 다른 식물을 구분할 수 있는 딥러닝 모델 구축
- 클라우드 기반 학습 환경 구성: 네이버 클라우드 플랫폼을 활용한 머신러닝 인프라 구축
- 실시간 추론 서비스 구현: 사용자가 업로드한 이미지를 분석하여 돼지감자 여부를 판별하는 시스템 개발
본론 #1 학습
돼지감자 데이터셋은 AI-Hub에서 가져왔기때문에 국내 IP에서만 다운로드하므로 머신러닝 학습과 추론을 위한 환경은 네이버 클라우드 플랫폼을 선택했습니다. 또한 개인 테스트이므로 비용적인 측면을 고려하여 GPU 대신 CPU 환경에서 작업을 진행했습니다.
참고로 AWS EC2에서도 데이터를 다운로드 해봤는데 AWS EC2가 서울 리전에 있어도 해외 IP로 인식되어 접근이 차단되는 문제가 발생합니다. 이런 지역 제한 문제를 해결하기 위해 네이버 클라우드 플랫폼을 선택하는 것은 하나의 좋은 선택지가 될 수 있습니다.
- 서버 스펙:
- 운영체제: Ubuntu 22.04
- vCPU: 4
- Memory: 8GB
비용 효율성을 위해 최소한의 서버 스펙으로 시작했지만 이로 인한 학습 시간 증가와 메모리 부족 문제를 해결하는 과정이 오히려 좋은 학습 경험이 되었습니다.
sudo apt update && sudo apt upgrade -y sudo apt install -y python3 python3-pip python3-venv unzip wget
Ubuntu 서버에 필요한 기본 패키지들을 설치했고 프로젝트의 의존성을 독립적으로 관리하기 위해 Python 가상환경을 설정했습니다.
python3 -m venv poison-env source poison-env/bin/activate
이후 딥러닝 모델 개발에 필요한 주요 패키지들을 설치했습니다.
pip install torch torchvision matplotlib pandas scikit-learn opencv-python
PyTorch를 메인 프레임워크로 선택한 이유는 다음과 같습니다.
- 직관적인 API와 풍부한 문서화
- 동적 계산 그래프를 통한 유연한 모델링
- 전이학습을 위한 다양한 사전 학습 모델 제공
- 활발한 커뮤니티 지원
데이터셋은 국내 AI-Hub에서 제공하는 ‘동의보감 약초 이미지 AI 데이터’를 활용했습니다.
AI Hub에는 무료 데이터셋을 제공하고 있어 공부하기에 아주 좋습니다! AI Hub 짱짱!
AI-Hub Shell을 이용해 데이터를 다운로드하는 과정은 다음과 같습니다.
(datasetkey는 데이터마다 넘버가 다르므로 원하는 데이터셋 다운로드 시 변경하면 되겠습니다.)
# 다운로드
wget https://api.aihub.or.kr/api/aihubshell.do
# 실행 권한 추가
chmod +x aihubshell.do
# 전역 실행을 위한 bin 등록
cp -avp aihubshell.do /usr/bin/aihubshell
# 데이터셋 다운로드
aihubshell -mode d -datasetkey 612 -aihubapikey '{API_KEY}'
저는 데이터셋에서 돼지감자 이미지를 선택적으로 다운로드하여 작업 디렉토리에 정리했고 이후 학습과 검증을 위한 디렉토리 구조를 다음과 같이 설정했습니다.
# 작업 디렉토리 생성 mkdir -p /poison_data/dataset/train/helianthus_tuberosus mkdir -p /poison_data/dataset/val/helianthus_tuberosus # 부정 샘플을 위한 디렉토리 생성 mkdir -p /poison_data/dataset/train/not_helianthus_tuberosus mkdir -p /poison_data/dataset/val/not_helianthus_tuberosus
디렉토리를 생성한 후 원본 데이터셋을 압축 해제하고 학습/검증 세트로 분할했습니다.
# 훈련 데이터 압축 해제 cd /poison_data/180.동의보감_약초_이미지_AI데이터/01.데이터/1.Training/원천데이터 unzip -O cp949 "/poison_data/180.동의보감_약초_이미지_AI데이터/01.데이터/1.Training/원천데이터/TS_돼지감자.zip" -d /poison_data/dataset/train/helianthus_tuberosus # 검증 데이터 압축 해제 cd /poison_data/180.동의보감_약초_이미지_AI데이터/01.데이터/2.Validation/원천데이터 unzip -O cp949 "/poison_data/180.동의보감_약초_이미지_AI데이터/01.데이터/2.Validation/원천데이터/VS_돼지감자.zip" -d /poison_data/dataset/val/helianthus_tuberosus
또한 부정 샘플(negative samples)로는 수박 이미지를 사용했습니다.
아무래도 해당 데이터 자체가 돼지감자를 구분하는 데이터가 아니라 동의보감 데이터라 돼지감자이다, 아니다로 구분하기에는 어려움이 있어서 테스트로 수박 이미지를 사용해보았습니다.
# 훈련 데이터 압축 해제 (수박 - 부정 샘플) cd /poison_data/180.동의보감_약초_이미지_AI데이터/01.데이터/1.Training/원천데이터 unzip -O cp949 "/poison_data/180.동의보감_약초_이미지_AI데이터/01.데이터/1.Training/원천데이터/TS_수박.zip" -d /poison_data/dataset/train/not_helianthus_tuberosus # 검증 데이터 압축 해제 (수박 - 부정 샘플) cd /poison_data/180.동의보감_약초_이미지_AI데이터/01.데이터/2.Validation/원천데이터 unzip -O cp949 "/poison_data/180.동의보감_약초_이미지_AI데이터/01.데이터/2.Validation/원천데이터/VS_수박.zip" -d /poison_data/dataset/val/not_helianthus_tuberosus
데이터 준비가 끝난 후 모델의 일반화 능력을 향상시키기 위해 다양한 데이터 증강 기법은 아래와 같이 적용했습니다.
- RandomHorizontalFlip/VerticalFlip: 이미지의 좌우/상하 반전을 통해 방향에 불변한 특성 학습
- RandomRotation: 회전된 이미지에 대한 인식 능력 향상
- RandomResizedCrop: 다양한 크기와 비율의 이미지에 대한 적응력 강화
- ColorJitter: 색상, 밝기, 대비 변화에 강건한 모델 구축
- RandomGrayscale: 흑백 이미지에 대한 대응 능력 개선
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.3),
transforms.RandomRotation(30),
transforms.RandomResizedCrop(224, scale=(0.8, 1.0)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomGrayscale(p=0.1),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
또한 이미지 분류를 위해 ResNet18 모델을 아래와 같은 이유로 선택했고 이진 분류 문제에 맞게 수정했습니다.
- 잔차 연결(Residual Connections): 깊은 신경망에서 발생하는 기울기 소실 문제를 효과적으로 해결
- 사전 학습된 가중치 활용: ImageNet 데이터셋으로 사전 학습된 가중치를 활용한 전이학습 용이
- 적절한 모델 크기: 상대적으로 가벼운 모델 크기로 CPU 환경에서도 학습 가능 (이 이유가 가장 큼)
- 높은 성능: 상대적으로 단순한 구조임에도 높은 이미지 분류 성능 제공
def create_model(num_classes=2):
model = models.resnet18(pretrained=True)
# 특성 추출 레이어의 가중치를 고정하지 않고 학습 가능하도록 설정
for param in model.parameters():
param.requires_grad = True
# 완전 연결 레이어를 이진 분류에 맞게 교체
num_features = model.fc.in_features
model.fc = nn.Sequential(
nn.Dropout(0.6), # 과적합 방지를 위한 Dropout 레이어
nn.Linear(num_features, num_classes)
)
return model
학습 코드는 아래와 같이 작성했습니다.
import os
import random
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
import torchvision.transforms.functional as TF
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image, ImageDraw, ImageFilter
import time
from datetime import datetime
import gc
# 랜덤 시드 설정
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed()
# 개선된 데이터셋 클래스 정의
class ImprovedDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.image_files = []
# 돼지감자 이미지 (positive samples)
ja_dir = os.path.join(root_dir, "helianthus_tuberosus")
if os.path.exists(ja_dir):
for dirpath, dirnames, filenames in os.walk(ja_dir):
for filename in filenames:
if filename.lower().endswith(('.jpg', '.jpeg', '.png')):
self.image_files.append((os.path.join(dirpath, filename), 1)) # 1은 돼지감자 클래스
# 돼지감자가 아닌 이미지 (negative samples) - 실제 이미지
neg_dir = os.path.join(root_dir, "not_helianthus_tuberosus")
if os.path.exists(neg_dir):
for dirpath, dirnames, filenames in os.walk(neg_dir):
for filename in filenames:
if filename.lower().endswith(('.jpg', '.jpeg', '.png')):
self.image_files.append((os.path.join(dirpath, filename), 0)) # 0은 돼지감자 아님 클래스
# 데이터 이미지 파일 확인 출력
positive_count = sum(1 for _, label in self.image_files if label == 1)
negative_count = sum(1 for _, label in self.image_files if label == 0)
print(f"데이터셋 크기: {len(self.image_files)} 이미지 (돼지감자: {positive_count}, 돼지감자 아님: {negative_count})")
if self.image_files:
print(f"첫 번째 이미지 경로 예시: {self.image_files[0][0]}")
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_path, label = self.image_files[idx]
try:
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
return image, label
except Exception as e:
print(f"이미지 로드 실패: {img_path} - {e}")
# 오류 발생 시 빈 이미지 반환 (학습 진행을 위해)
dummy_image = Image.new('RGB', (224, 224), color='gray')
if self.transform:
dummy_image = self.transform(dummy_image)
return dummy_image, label
# 원래의 JerusalemArtichokeDataset 클래스는 유지 (기존 코드와의 호환성을 위해)
class JerusalemArtichokeDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.image_files = []
# 돼지감자 이미지 파일 수집 (하위 디렉토리 포함)
ja_dir = os.path.join(root_dir, "helianthus_tuberosus")
if os.path.exists(ja_dir):
for dirpath, dirnames, filenames in os.walk(ja_dir):
for filename in filenames:
if filename.lower().endswith(('.jpg', '.jpeg', '.png')):
self.image_files.append((os.path.join(dirpath, filename), 1)) # 1은 돼지감자 클래스
# 데이터 이미지 파일이 많지 않으므로 확인 출력
print(f"데이터셋 크기: {len(self.image_files)} 이미지")
print(f"첫 번째 이미지 경로 예시: {self.image_files[0][0] if self.image_files else 'None'}")
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_path, label = self.image_files[idx]
try:
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
return image, label
except Exception as e:
print(f"이미지 로드 실패: {img_path} - {e}")
# 오류 발생 시 빈 이미지 반환 (학습 진행을 위해)
dummy_image = Image.new('RGB', (224, 224), color='gray')
if self.transform:
dummy_image = self.transform(dummy_image)
return dummy_image, label
# 가짜 부정 샘플 생성 함수 (실제 부정 이미지가 부족한 경우 보완용)
def generate_dummy_negatives_in_batches(dataset, num_samples, transform, batch_size=100):
"""훈련용 가짜 부정 샘플을 배치 단위로 생성합니다."""
width, height = 224, 224
# 전체 샘플 수 제한
num_samples = min(num_samples, 1000) # 최대 1000개로 제한
print(f"생성할 가짜 부정 샘플 수: {num_samples}")
# 배치 단위로 처리
all_negatives = []
for batch_start in range(0, num_samples, batch_size):
batch_end = min(batch_start + batch_size, num_samples)
print(f"배치 생성 중: {batch_start+1}-{batch_end}/{num_samples}")
batch_negatives = []
for i in range(batch_start, batch_end):
if i % 3 == 0:
# 간단한 도형 이미지 (복잡도 낮춤)
img = Image.new('RGB', (width, height), color=(
random.randint(100, 200),
random.randint(100, 200),
random.randint(100, 200)
))
# 간단한 도형 한 개만 추가
draw = ImageDraw.Draw(img)
shape_type = random.choice(['rectangle', 'ellipse'])
color = (
random.randint(0, 255),
random.randint(0, 255),
random.randint(0, 255)
)
x1 = random.randint(0, width-1)
y1 = random.randint(0, height-1)
x2 = random.randint(x1, width)
y2 = random.randint(y1, height)
if shape_type == 'rectangle':
draw.rectangle([x1, y1, x2, y2], fill=color)
else:
draw.ellipse([x1, y1, x2, y2], fill=color)
else:
# 단순 칼라 이미지
img = Image.new('RGB', (width, height), color=(
random.randint(100, 200),
random.randint(100, 200),
random.randint(100, 200)
))
# 변환 적용
img_tensor = transform(img)
batch_negatives.append((img_tensor, 0)) # 0은 '돼지감자 아님' 클래스
# 배치 추가 및 메모리 관리
all_negatives.extend(batch_negatives)
# 명시적 메모리 정리
del batch_negatives
gc.collect()
return all_negatives
class CombinedDataset(Dataset):
"""돼지감자 데이터셋과 생성된 부정 샘플을 결합하는 데이터셋"""
def __init__(self, positive_dataset, negative_samples):
self.positive_dataset = positive_dataset
self.negative_samples = negative_samples
def __len__(self):
return len(self.positive_dataset) + len(self.negative_samples)
def __getitem__(self, idx):
if idx < len(self.positive_dataset):
return self.positive_dataset[idx]
else:
return self.negative_samples[idx - len(self.positive_dataset)]
# 이미지 변환 정의 - 데이터 증강 강화
def get_transforms():
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.3),
transforms.RandomRotation(30),
transforms.RandomResizedCrop(224, scale=(0.8, 1.0)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomGrayscale(p=0.1),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
return train_transform, val_transform
# 모델 정의 - 정규화 강화
def create_model(num_classes=2):
model = models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = True
num_features = model.fc.in_features
model.fc = nn.Sequential(
nn.Dropout(0.6), # 드롭아웃 비율 증가
nn.Linear(num_features, num_classes)
)
return model
# 모델 학습 함수
def train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, num_epochs=10, save_dir='models'):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"학습에 사용되는 장치: {device}")
model = model.to(device)
best_model_wts = None
best_acc = 0.0
train_losses = []
val_losses = []
train_accs = []
val_accs = []
for epoch in range(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}')
print('-' * 10)
# 학습 단계
model.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in train_loader:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = running_corrects.double() / len(train_loader.dataset)
train_losses.append(epoch_loss)
train_accs.append(epoch_acc.item())
print(f'Train Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# 검증 단계
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in val_loader:
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(val_loader.dataset)
epoch_acc = running_corrects.double() / len(val_loader.dataset)
val_losses.append(epoch_loss)
val_accs.append(epoch_acc.item())
print(f'Val Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# ReduceLROnPlateau 스케줄러는 검증 손실을 기반으로 학습률 조정
if scheduler is not None:
if isinstance(scheduler, torch.optim.lr_scheduler.ReduceLROnPlateau):
scheduler.step(epoch_loss) # 검증 손실 전달
else:
scheduler.step()
# 최고 성능 모델 저장
if epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model.state_dict().copy()
# 현재 최고 성능 모델 저장
os.makedirs(save_dir, exist_ok=True)
torch.save(model.state_dict(), os.path.join(save_dir, 'best_model.pth'))
print(f"최고 성능 모델 저장: {os.path.join(save_dir, 'best_model.pth')}")
print()
# 메모리 관리를 위한 가비지 컬렉션
gc.collect()
torch.cuda.empty_cache() if torch.cuda.is_available() else None
print(f'Best val Acc: {best_acc:.4f}')
# 최고 성능 모델 가중치 불러오기
model.load_state_dict(best_model_wts)
# 학습 결과 시각화
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs+1), train_losses, label='Train Loss')
plt.plot(range(1, num_epochs+1), val_losses, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs+1), train_accs, label='Train Accuracy')
plt.plot(range(1, num_epochs+1), val_accs, label='Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Training and Validation Accuracy')
plt.tight_layout()
plt.savefig(os.path.join(save_dir, 'training_results.png'))
return model
def main():
# 1. 데이터 로딩
train_dir = "/poison_data/dataset/train"
val_dir = "/poison_data/dataset/val"
model_dir = "models"
os.makedirs(model_dir, exist_ok=True)
train_transform, val_transform = get_transforms()
# 개선된 데이터셋 사용 (실제 부정 샘플 포함)
print("데이터셋 로딩 중...")
train_dataset = ImprovedDataset(train_dir, transform=train_transform)
val_dataset = ImprovedDataset(val_dir, transform=val_transform)
# 실제 부정 샘플이 부족한 경우, 가짜 부정 샘플 추가
if sum(1 for _, label in train_dataset.image_files if label == 0) < 100:
print("실제 부정 샘플이 부족합니다. 가짜 부정 샘플을 추가합니다.")
# 돼지감자 이미지만 추출
train_positive_only = [(img, label) for img, label in train_dataset.image_files if label == 1]
# 가짜 부정 샘플 생성
fake_negatives = generate_dummy_negatives_in_batches(train_dataset, len(train_positive_only) // 2, train_transform, batch_size=100)
# 모든 샘플 합치기
combined_samples = train_dataset.image_files + [(tensor, label) for tensor, label in fake_negatives]
# 데이터셋 재구성
train_dataset.image_files = combined_samples
print(f"합쳐진 데이터셋 크기: {len(train_dataset.image_files)}")
print(f"최종 학습 데이터셋 크기: {len(train_dataset)} 이미지")
print(f"최종 검증 데이터셋 크기: {len(val_dataset)} 이미지")
# 배치 크기와 워커 수 조정
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True, num_workers=1)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False, num_workers=1)
# 2. 모델 생성
model = create_model(num_classes=2) # 돼지감자vs기타 이진 분류
# 3. 손실 함수, 옵티마이저, 스케줄러 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4) # 가중치 감쇠 추가
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=3, verbose=True)
# 4. 모델 학습
model = train_model(
model, train_loader, val_loader,
criterion, optimizer, scheduler,
num_epochs=20, # 에포크 수 증가
save_dir=model_dir
)
# 5. 최종 모델 저장
torch.save(model.state_dict(), os.path.join(model_dir, 'jerusalem_artichoke_model.pth'))
print(f"최종 모델 저장: {os.path.join(model_dir, 'jerusalem_artichoke_model.pth')}")
if __name__ == "__main__":
main()
먼저 CPU 환경에서 대용량 이미지 데이터셋을 학습시키기 위해 다음과 같은 기법들을 적용했습니다.
1) 메모리 관리: 주기적인 가비지 컬렉션 호출로 메모리 사용량 최적화
import gc gc.collect() # 메모리 정리
2) 배치 크기 최적화: 메모리 제한을 고려한 배치 크기 설정
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
3) 체크포인트 저장: 주기적인 모델 저장으로 학습 중단 시 복구 가능성 확보
torch.save(model.state_dict(), f'models/model_epoch_{epoch}.pth')
4) 조기 종료(Early Stopping): 과적합 방지 및 최적 모델 선정을 위한 조기 종료 구현
위 기법들을 추가하게 된 것 중 특히 메모리 관리 부분을 가장 많이 고민했었는데… 그 이유가 학습 중에 계속 메모리 부족으로 Process Kill이 되어버려서… 그렇다고 개인 테스트이므로 인스턴스 크기를 높일 순 없었기에 최대한 CPU만으로 학습하고자 했습니다.
학습 데이터의 구성은 아래와 같습니다.
- 학습 데이터:
- 돼지감자 이미지(positive): 약 36.3GB, 7,566개 이미지
- 수박 이미지(negative): 약 11.3GB, 4,032개 이미지
- 총 데이터셋 크기: 약 47.6GB, 11,598개 이미지
- 검증 데이터:
- 돼지감자 이미지: 943개
- 수박 이미지: 501개
- 총 검증 데이터: 1,444개 이미지
본론 #2 추론
import os
import sys
import torch
import torchvision.transforms as transforms
from PIL import Image
import io
import boto3
from botocore.client import Config
import matplotlib.pyplot as plt
from datetime import datetime
import time
import json
from torch.utils.data import Dataset, DataLoader
from torchvision import models
import torch.nn as nn
import argparse
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 폰트 경로 지정 및 등록
font_path = '/usr/share/fonts/truetype/nanum/NanumGothic.ttf' # 예시
fontprop = fm.FontProperties(fname=font_path)
plt.rcParams['font.family'] = fontprop.get_name()
# S3 설정
S3_ENDPOINT = "https://kr.object.ncloudstorage.com"
S3_ACCESS_KEY = "{OBJECTSTORAGE_권한_ACCESSKEY}"
S3_SECRET_KEY = "{OBJECTSTORAGE_권한_SECRETKEY}"
S3_BUCKET = "{NCLOUD_OBJECTSTORAGE_BUCKET_NAME}"
# 모델 파일 경로 (위 학습 실행 후 생성된 모델로 지정)
MODEL_PATH = 'models/best_model.pth'
# 판별 임계값 설정
CONFIDENCE_THRESHOLD = 0.8 # 80% 이상의 확신이 있을 때만 돼지감자로 판별
# 이미지 전처리 변환
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 모델 구조 정의
def create_model(num_classes=2):
model = models.resnet18(pretrained=False)
num_features = model.fc.in_features
model.fc = nn.Sequential(
nn.Dropout(0.6),
nn.Linear(num_features, num_classes)
)
return model
# S3 클라이언트 설정
def setup_s3_client(endpoint_url=S3_ENDPOINT, access_key=S3_ACCESS_KEY, secret_key=S3_SECRET_KEY):
s3_client = boto3.client(
's3',
endpoint_url=endpoint_url,
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
config=Config(signature_version='s3v4')
)
return s3_client
# S3 버킷 내 이미지 목록 가져오기
def list_images_in_bucket(s3_client, bucket_name, prefix=""):
try:
response = s3_client.list_objects_v2(Bucket=bucket_name, Prefix=prefix)
if 'Contents' in response:
return [obj['Key'] for obj in response['Contents'] if obj['Key'].lower().endswith(('.jpg', '.jpeg', '.png'))]
return []
except Exception as e:
print(f"S3 버킷에서 이미지 목록을 가져오는 중 오류 발생: {e}")
return []
# S3에서 이미지 가져오기
def get_image_from_s3(s3_client, bucket_name, image_key):
try:
response = s3_client.get_object(Bucket=bucket_name, Key=image_key)
image_content = response['Body'].read()
image = Image.open(io.BytesIO(image_content)).convert('RGB')
return image
except Exception as e:
print(f"S3에서 이미지를 가져오는 중 오류 발생: {e}")
return None
# 임계값을 적용한 이미지 추론 함수
def predict_image_with_threshold(model, image, transform, threshold=CONFIDENCE_THRESHOLD):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
model.eval()
image_tensor = transform(image).unsqueeze(0).to(device)
with torch.no_grad():
outputs = model(image_tensor)
probs = torch.nn.functional.softmax(outputs, dim=1)
prob_positive = probs[0][1].item() # 돼지감자일 확률
# 임계값 적용
if prob_positive >= threshold:
prediction = 1 # 돼지감자
else:
prediction = 0 # 돼지감자 아님
return prediction, prob_positive
# 기존 추론 함수 (임계값 없음, 이전 코드와의 호환성을 위해 유지)
def predict_image(model, image, transform):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
model.eval()
image_tensor = transform(image).unsqueeze(0).to(device)
with torch.no_grad():
outputs = model(image_tensor)
probs = torch.nn.functional.softmax(outputs, dim=1)
prob, predicted = torch.max(probs, 1)
return predicted.item(), prob.item()
# 추론 결과 시각화 및 저장
def visualize_prediction(image, prediction, probability, output_dir, filename):
plt.figure(figsize=(8, 8))
plt.imshow(image)
# 영어로 결과 표시 (한글 폰트 문제 해결)
result_en = "Jerusalem Artichoke" if prediction == 1 else "Not Jerusalem Artichoke"
plt.title(f'Prediction: {result_en}, Probability: {probability:.2f}')
plt.axis('off')
os.makedirs(output_dir, exist_ok=True)
output_path = os.path.join(output_dir, f'prediction_{filename}')
plt.savefig(output_path)
plt.close()
result_info = {
"image": filename,
"prediction": "jerusalem_artichoke" if prediction == 1 else "not_jerusalem_artichoke",
"probability": float(probability),
"result_image": output_path
}
return result_info, output_path
# 모델 로드
def load_model(model_path):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = create_model(num_classes=2)
try:
model.load_state_dict(torch.load(model_path, map_location=device))
model.to(device)
model.eval()
print(f"모델을 성공적으로 로드했습니다: {model_path}")
return model
except Exception as e:
print(f"모델 로드 중 오류 발생: {e}")
return None
# 감시 및 처리 로직
def monitor_and_process(s3_endpoint, s3_access_key, s3_secret_key, bucket_name, interval=30, output_dir="results", threshold=CONFIDENCE_THRESHOLD):
"""
S3 버킷을 주기적으로 감시하고 새 이미지를 처리합니다.
"""
# 모델 로드
model = load_model(MODEL_PATH)
if model is None:
return
# S3 클라이언트 설정
s3_client = setup_s3_client(s3_endpoint, s3_access_key, s3_secret_key)
# 이미 처리된 이미지 추적
processed_images = set()
print(f"S3 버킷 '{bucket_name}' 감시를 시작합니다...")
print(f"임계값: {threshold} (이 값 이상의 확률에서만 돼지감자로 판별)")
try:
while True:
# 버킷 내 이미지 목록 가져오기
image_keys = list_images_in_bucket(s3_client, bucket_name)
# 새 이미지 처리
for key in image_keys:
if key not in processed_images:
print(f"새 이미지 발견: {key}")
# 이미지 다운로드
image = get_image_from_s3(s3_client, bucket_name, key)
if image is None:
continue
# 이미지 추론 (임계값 적용)
prediction, probability = predict_image_with_threshold(model, image, transform, threshold)
# 결과 저장
filename = os.path.basename(key)
result_info, output_path = visualize_prediction(image, prediction, probability, output_dir, filename)
# JSON 결과 저장
result_json_path = os.path.join(output_dir, f"result_{filename.split('.')[0]}.json")
with open(result_json_path, 'w', encoding='utf-8') as f:
json.dump(result_info, f, ensure_ascii=False, indent=2)
# 처리 로그
result_text = "돼지감자" if prediction == 1 else "돼지감자 아님"
print(f"이미지 '{key}' 처리 결과: {result_text} (확률: {probability:.2f})")
print(f"결과 이미지: {output_path}")
print(f"결과 JSON: {result_json_path}")
# 처리 완료 표시
processed_images.add(key)
# 대기
print(f"{datetime.now().strftime('%Y-%m-%d %H:%M:%S')} - 다음 확인 간격 대기 중... ({interval}초)")
time.sleep(interval)
except KeyboardInterrupt:
print("감시를 중단합니다.")
except Exception as e:
print(f"오류 발생: {e}")
# 단일 이미지 처리 (S3)
def process_s3_image(s3_endpoint, s3_access_key, s3_secret_key, bucket_name, image_key, output_dir="results", threshold=CONFIDENCE_THRESHOLD):
# 모델 로드
model = load_model(MODEL_PATH)
if model is None:
return
# S3 클라이언트 설정
s3_client = setup_s3_client(s3_endpoint, s3_access_key, s3_secret_key)
# 이미지 다운로드
image = get_image_from_s3(s3_client, bucket_name, image_key)
if image is None:
print(f"이미지를 가져올 수 없습니다: {image_key}")
return
# 이미지 추론 (임계값 적용)
prediction, probability = predict_image_with_threshold(model, image, transform, threshold)
# 결과 저장
filename = os.path.basename(image_key)
result_info, output_path = visualize_prediction(image, prediction, probability, output_dir, filename)
# JSON 결과 저장
result_json_path = os.path.join(output_dir, f"result_{filename.split('.')[0]}.json")
with open(result_json_path, 'w', encoding='utf-8') as f:
json.dump(result_info, f, ensure_ascii=False, indent=2)
# 처리 로그
result_text = "돼지감자" if prediction == 1 else "돼지감자 아님"
print(f"이미지 '{image_key}' 처리 결과: {result_text} (확률: {probability:.2f})")
print(f"임계값: {threshold} (확률이 이 값 이상이면 돼지감자로 판별)")
print(f"결과 이미지: {output_path}")
print(f"결과 JSON: {result_json_path}")
# 로컬 이미지 처리
def process_local_image(image_path, output_dir="results", threshold=CONFIDENCE_THRESHOLD):
# 모델 로드
model = load_model(MODEL_PATH)
if model is None:
return
# 이미지 로드
try:
image = Image.open(image_path).convert('RGB')
except Exception as e:
print(f"이미지를 열 수 없습니다: {e}")
return
# 이미지 추론 (임계값 적용)
prediction, probability = predict_image_with_threshold(model, image, transform, threshold)
# 결과 저장
filename = os.path.basename(image_path)
result_info, output_path = visualize_prediction(image, prediction, probability, output_dir, filename)
# JSON 결과 저장
result_json_path = os.path.join(output_dir, f"result_{filename.split('.')[0]}.json")
with open(result_json_path, 'w', encoding='utf-8') as f:
json.dump(result_info, f, ensure_ascii=False, indent=2)
# 처리 로그
result_text = "돼지감자" if prediction == 1 else "돼지감자 아님"
print(f"이미지 '{image_path}' 처리 결과: {result_text} (확률: {probability:.2f})")
print(f"임계값: {threshold} (확률이 이 값 이상이면 돼지감자로 판별)")
print(f"결과 이미지: {output_path}")
print(f"결과 JSON: {result_json_path}")
def main():
parser = argparse.ArgumentParser(description="돼지감자 이미지 추론 서비스")
parser.add_argument("--mode", choices=["local", "s3", "monitor"], required=True,
help="실행 모드: local(로컬 이미지), s3(S3 이미지), monitor(S3 감시)")
parser.add_argument("--image", help="처리할 이미지 경로(local 모드) 또는 키(s3 모드)")
parser.add_argument("--s3-endpoint", default=S3_ENDPOINT,
help="S3 엔드포인트 URL")
parser.add_argument("--s3-access-key", default=S3_ACCESS_KEY,
help="S3 액세스 키")
parser.add_argument("--s3-secret-key", default=S3_SECRET_KEY,
help="S3 시크릿 키")
parser.add_argument("--s3-bucket", default=S3_BUCKET,
help="S3 버킷 이름")
parser.add_argument("--threshold", type=float, default=CONFIDENCE_THRESHOLD,
help=f"판별 임계값 (기본값: {CONFIDENCE_THRESHOLD})")
parser.add_argument("--interval", type=int, default=30,
help="S3 감시 간격(초)")
parser.add_argument("--output-dir", default="results",
help="결과 저장 디렉토리")
args = parser.parse_args()
# 결과 디렉토리 생성
os.makedirs(args.output_dir, exist_ok=True)
if args.mode == "local":
if not args.image:
parser.error("local 모드에는 --image 인자가 필요합니다.")
process_local_image(args.image, args.output_dir, args.threshold)
elif args.mode == "s3":
if not args.image:
parser.error("s3 모드에는 --image 인자가 필요합니다.")
process_s3_image(
args.s3_endpoint, args.s3_access_key, args.s3_secret_key,
args.s3_bucket, args.image, args.output_dir, args.threshold
)
elif args.mode == "monitor":
monitor_and_process(
args.s3_endpoint, args.s3_access_key, args.s3_secret_key,
args.s3_bucket, args.interval, args.output_dir, args.threshold
)
if __name__ == "__main__":
main()
네이버 클라우드의 Object Storage를 활용하여 이미지를 저장하고 추론하는 시스템을 구축했습니다.
def setup_s3_client(endpoint, access_key, secret_key):
session = boto3.session.Session()
s3_client = session.client(
's3',
endpoint_url=endpoint,
aws_access_key_id=access_key,
aws_secret_access_key=secret_key
)
return s3_client
def get_image_from_s3(s3_client, bucket_name, image_key):
response = s3_client.get_object(Bucket=bucket_name, Key=image_key)
image_content = response['Body'].read()
image = Image.open(BytesIO(image_content))
return image
사용자가 업로드한 이미지를 실시간으로 처리하는 모니터링 모드를 구현했기 때문에 Object Storage를 실시간으로 모니터링하고, 새로운 이미지가 업로드 되면 해당 이미지가 몇퍼센트 확률로 돼지감자인지 알려주도록 했습니다. 즉, 추론 결과를 시각적으로 확인할 수 있도록 원본 이미지에 예측 결과를 표시하고 저장하는 기능도 함께 구현했습니다.
def monitor_s3_bucket(s3_client, bucket_name, interval, output_dir, model, transform, threshold):
processed_images = set()
while True:
try:
response = s3_client.list_objects_v2(Bucket=bucket_name)
if 'Contents' in response:
for obj in response['Contents']:
key = obj['Key']
# 이미지 파일이고 아직 처리되지 않은 경우
if key.lower().endswith(('.png', '.jpg', '.jpeg', '.gif')) and key not in processed_images:
print(f"새 이미지 발견: {key}")
# 이미지 처리
process_s3_image(s3_client, bucket_name, key, output_dir, model, transform, threshold)
processed_images.add(key)
print(f"{datetime.now().strftime('%Y-%m-%d %H:%M:%S')} - 다음 확인 간격 대기 중... ({interval}초)")
time.sleep(interval)
except Exception as e:
print(f"오류 발생: {str(e)}")
time.sleep(interval)
def add_prediction_to_image(image, prediction, probability):
draw = ImageDraw.Draw(image)
# 결과 텍스트 생성
result_text = "돼지감자" if prediction == 1 else "돼지감자 아님"
probability_text = f"확률: {probability:.2f}"
# 이미지 하단에 결과 표시
font_size = max(15, int(image.width / 30))
# ... 텍스트 그리기 코드 ...
return image
학습과 추론을 통해 결과를 분석해본 결과 아래와 같이 여러 사실을 알게 되었습니다.
- 돼지감자만 학습할 경우 돼지감자, 일반 감자, 생강 3개의 이미지를 넣고 학습된 모델을 이용하여 추론했는데 모두 돼지 감자라고 판별한다.
- 돼지감자 외 다른 것(수박)을 not_helianthus_tuberosus 데이터로 함께 학습한 결과 돼지감자와 다른 것(수박)을 구분할 수 있다. 즉, 수박은 돼지감자가 아니라고 명확하게 구분한다.
- 이 테스트에서 학습 및 검증 손실이 초기에 급격히 감소하고 점차 안정화되었다.
- 또한 에포크 20 기준 손실값 0.05 이하로 낮아졌다.
- 해당 데이터셋으로 학습했을 때 학습 손실과 검증 손실의 차이가 작아 과적합이 크게 발생하지 않았다.
- 학습 및 검증 정확도가 지속적으로 상승하여 최종 97% 이상 달성하기도 했다.
- 검증 정확도에 약간의 변동이 있으나 전반적으로 상승세를 유지했다.



| 이미지 종류 | 돼지감자로 판별한 확률 | 결과 해석 |
|---|---|---|
| 돼지감자 | 100% | 정확한 판별 |
| 토마토 | 100% | 오인식(긍정 오류) |
| 감자 | 89% | 오인식(긍정 오류) |
| 수박 | 2% | 정확한 판별 |
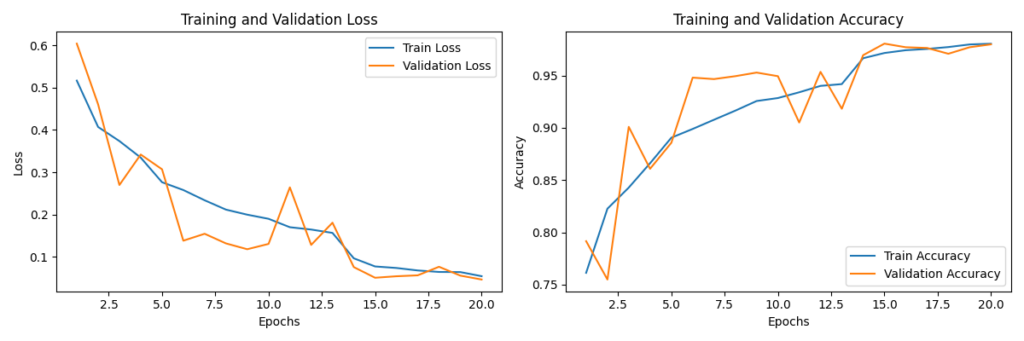
→ 돼지감자(약 36.3GB)만 학습시켰을 때 8시간 30분 소요됨. (epoch 15로 설정함)
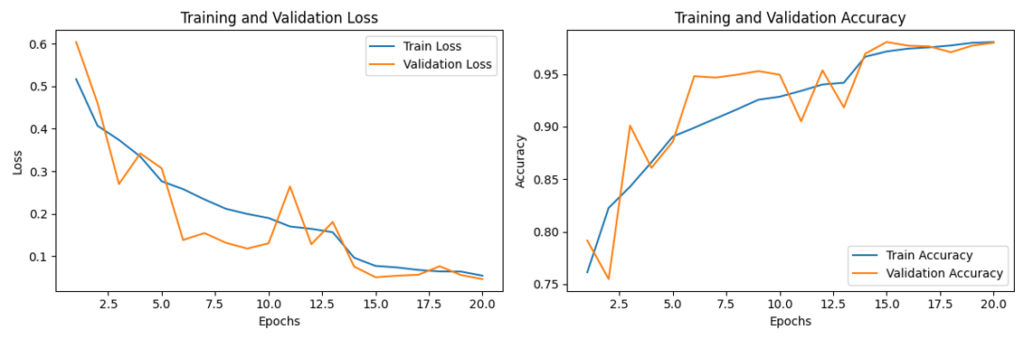
→ 돼지감자(약 36.3GB)와 수박(약 11.3GB) 2개를 학습 시켰을 때 48시간 45분이 소요됨. (epoch 20으로 설정함)
- 한계점
1) 제한된 부정 샘플
: 수박 이미지만을 부정 샘플로 사용하여 모델이 “돼지감자 vs 수박”의 이분법적 학습을 함
: 이로 인해 토마토, 감자 등 학습되지 않은 작물은 여전히 돼지감자로 잘못 판별됨
: 추가적인 데이터 학습과 연구를 하고 싶었으나 스토리지 부족 및 아래 이유로 많은 시간을 소요하게 됨…
2) CPU 학습의 한계
: 대용량 데이터셋 학습에 긴 시간 소요 (약 48시간)
: 메모리 제한으로 인한 배치 크기 제약과 빈번한 메모리 관리 필요
Personal Comments
이번 스터디는 클라우드 엔지니어에서 ML 엔지니어로 영역을 확장해가는 첫 단계였습니다. 처음에는 생소했던 개념들이 실제 해보는 경험을 통해 점차 명확해지는 과정이 매우 보람찼습니다.
저와 같이 ML을 처음 접하는 클라우드 엔지니어나 IT 종사자들에게 도움이 되길 바랍니다. 가장 중요한 것은 두려움 없이 첫 발을 내딛는 것입니다. 비록 완벽하지 않더라도 실제 프로젝트를 통한 경험이 가장 빠른 학습 방법임을 이번 스터디를 통해 다시 한번 확인할 수 있었습니다.
긴 글 읽어주셔서 감사합니다.