
안녕하세요 MANVSCLOUD 김수현입니다.
최근 생성형 AI의 발전과 함께 자연어 처리 기술이 급속도로 발전하고 있습니다.
ChatGPT, Claude, HyperCLOVA X 등 다양한 AI 모델들이 등장하면서 이들의 한국어 처리 능력에 대한 관심도 높아지고 있습니다. 특히 네이버클라우드의 HyperCLOVA X는 한국어에 특화된 모델이라는 점에서 주목받고 있는데요.
과연 한국어 처리에 있어 실제로 더 효율적일까요?
이 질문에 답하기 위해서는 먼저 ‘토큰화(Tokenization)’라는 개념부터 이해하고자 합니다.
토큰화는 AI 모델이 텍스트를 처리하는 방식에 직접적인 영향을 미치며 특히 비용적인 측면에서도 중요한 요소인데 토큰의 수가 많아질수록 API 사용 비용이 증가하기 때문입니다.
한국어는 영어와는 달리 복잡한 문법 구조와 조사, 어미 변화 등으로 인해 토큰화 과정이 훨씬 까다롭습니다. 이러한 특성은 AI 모델의 성능과 효율성에 직접적인 영향을 미치게 되는데요.
이번 포스팅에서 토큰화란 무엇인지 그리고 HyperCLOVA X와 타 AI 모델들 간 한국어 토큰량을 비교해보고자 합니다.
Tokenization

- 토큰화의 개념과 중요성
토큰화(Tokenization)는 텍스트를 의미 있는 작은 단위로 나누는 과정입니다. 여기서 토큰(Token)이란 자연어 처리를 위해 하나의 단어를 세분화한 단어 조각을 의미하는데요.
이는 AI 모델이 텍스트를 이해하고 처리하는 기본 단위가 됩니다.
예를 들어 ‘맛있어’라는 단어는 ‘맛’과 ‘있어’라는 두 개의 토큰으로 나뉠 수 있습니다. 이러한 토큰화는 단순히 단어를 나누는 것 이상의 의미를 가지는데 이는 AI 모델의 처리 효율성과 직접적인 연관이 있기 때문입니다.
- 한국어 토큰화의 특수성
한국어 토큰화가 특별히 주목받는 이유는 한국어만의 독특한 언어적 특성 때문입니다. 영어와 달리 한국어는 다음과 같은 특징들을 가지고 있습니다.
한국어에서는 ‘그가’, ‘그를’, ‘그에게’, ‘그와’ 같이 하나의 단어에 다양한 조사가 결합됩니다. 이는 토큰화 과정에서 추가적인 처리를 필요로 하며 각 조사를 별도의 토큰으로 인식해야 할지 아니면 함께 처리할지에 대한 결정이 필요합니다.
또한 한국어 토큰화에서는 형태소라는 개념이 매우 중요합니다. 형태소는 의미를 가진 가장 작은 언어 단위로 자립 형태소(명사, 동사의 어간 등)와 의존 형태소(조사, 어미 등)로 구분됩니다. 효율적인 토큰화를 위해서는 이러한 형태소 단위의 적절한 분리가 필수적입니다.
HyperCLOVA X는 한국어에 특화된 토큰화 방식을 채택하고 있습니다.
– HyperCLOVA X: 한국어의 특성을 고려한 형태소 기반 토큰화
– ChatGPT/Claude: 범용적인 BPE(Byte Pair Encoding) 기반 토큰화
예시 문장: “오늘 날씨가 정말 좋네요”
– HyperCLOVA X: 4-5개 토큰
– 글로벌 모델: 6-7개 토큰
(이는 예시일 뿐이며 실제 토큰 수는 아래 ‘토큰 사용량 비교’ 부분에서 자세히 알아보겠습니다)
추가로 토큰 수는 API 사용 비용과 직결되는데요.
HyperCLOVA X의 한국어 특화 토큰화는 다음과 같은 장점을 제공할 수 있습니다.
– 더 적은 토큰 수로 동일한 내용 처리 가능
– 한국어 문맥 이해도 향상
– API 호출당 처리할 수 있는 텍스트량 증가
다만 실제 비용 효율성은 사용 사례와 규모에 따라 달라질 수 있으며 단순히 토큰 수만으로는 판단할 수 없는 부분이 있습니다.
토큰 사용량 비교
- 테스트 문장
: 테스트에 사용할 문장은 간단하게 애국가 1절을 사용하기로 했습니다.
동해 물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세 무궁화 삼천리 화려 강산 대한 사람 대한으로 길이 보전하세
- Claude 3.5 Sonnet (Tokens : 79)
: Lunary(https://lunary.ai/anthropic-tokenizer)와 Token Counter(https://token-counter.app/anthropic/claude-3.5-sonnet) 사이트를 기준으로 활용했습니다.
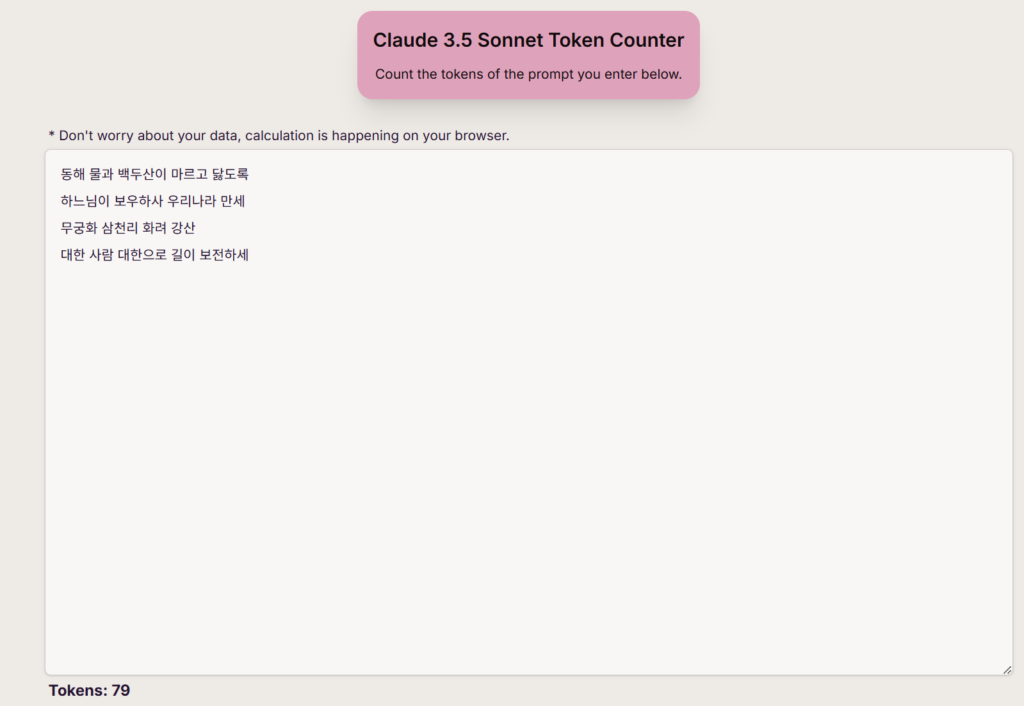

Claude의 경우 상당히 많은 토큰이 사용되었고 대부분의 한국어의 의미를 잘 파악하지 못하는 것으로 확인되었습니다. (그래서 다들 Claude가 너무 비용이 많이 나온다고 하는구나…)
- ChatGPT 4o (Tokens : 48)
: Openai에서 제공하는 Tokenizer를 사용했습니다. (https://platform.openai.com/tokenizer)
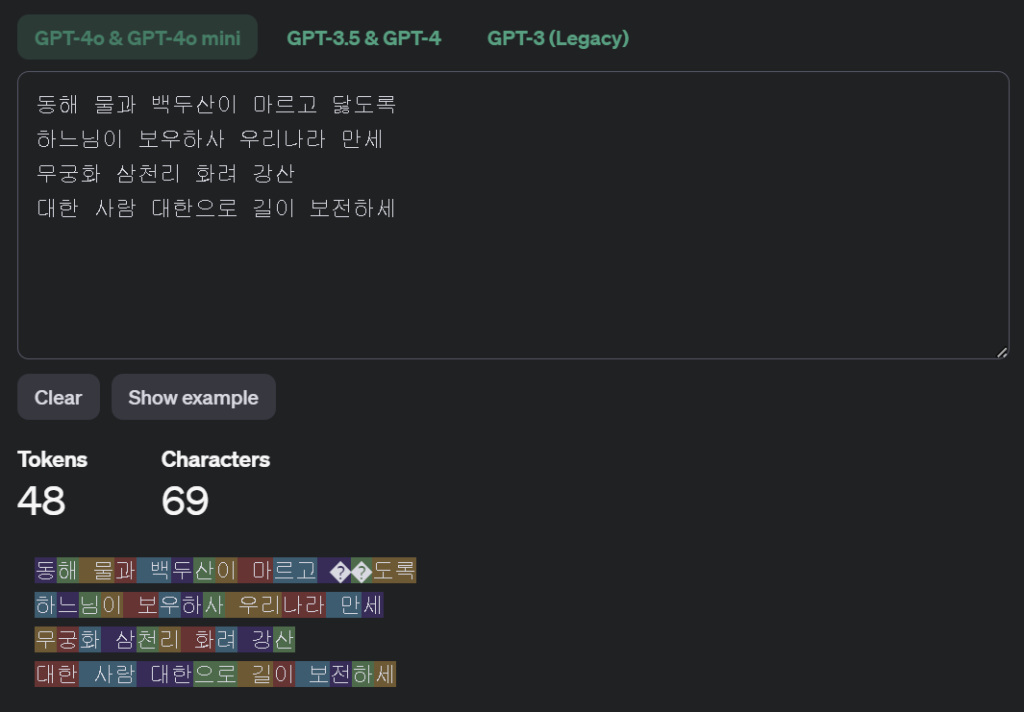
GPT는 생각보다 Token수가 적어서 놀랬습니다.
(너… 한국어 성능 꽤 좋구나?)
- HyperCLOVA X (Tokens : 33)
: CLOVA Studio의 Chat Completions v1 API를 활용했습니다.
: 코드는 개인 테스트 서버에서 임의로 만들어두고 활용하던 코드를 가져왔습니다.
# -*- coding: utf-8 -*-
import base64
import json
import http.client
class CompletionExecutor:
def __init__(self, host, api_key, api_key_primary_val, request_id):
self._host = host
self._api_key = api_key
self._api_key_primary_val = api_key_primary_val
self._request_id = request_id
def _send_request(self, completion_request):
headers = {
'Content-Type': 'application/json; charset=utf-8',
'X-NCP-CLOVASTUDIO-API-KEY': self._api_key,
'X-NCP-APIGW-API-KEY': self._api_key_primary_val,
'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id
}
conn = http.client.HTTPSConnection(self._host)
conn.request('POST', '/v1/api-tools/chat-tokenize/HCX-003', json.dumps(completion_request), headers)
response = conn.getresponse()
result = json.loads(response.read().decode(encoding='utf-8'))
conn.close()
return result
def execute(self, completion_request):
res = self._send_request(completion_request)
if res['status']['code'] == '20000':
# Find the user message and extract its content and count
for message in res['result']['messages']:
if message['role'] == 'user':
return f"Content : {message['content']}\nCount : {message['count']}"
return 'Error'
if __name__ == '__main__':
completion_executor = CompletionExecutor(
host='clovastudio.apigw.ntruss.com',
api_key='{API_KEY}',
api_key_primary_val='{API_KEY_PRI}',
request_id='{REQUEST_ID}'
)
# 파일에서 role과 content, user 읽기(이 과정에서는 user가 사용하는 텍스트만 사용)
with open('/root/billing/token_sys', 'r') as sys_file:
sys = sys_file.read().strip()
with open('/root/billing/token_user', 'r') as user_file:
user = user_file.read().strip()
with open('/root/billing/token_assistant', 'r') as assistant_file:
assistant = assistant_file.read().strip()
request_data = {
"messages": [
{
"role": "system",
"content": sys
},
{
"role": "user",
"content": user
},
{
"role": "assistant",
"content": assistant
},
]
}
response_text = completion_executor.execute(request_data)
print(response_text)

역시 예상대로 HyperCLOVA X가 토큰 수가 가장 적게 나왔습니다.
결과는 아래와 같이 HyperCLOVA X가 가장 적은 토큰으로 한국어 문맥을 이해하고 텍스트를 처리했다고 정리할 수 있습니다.
▶ Claude 3.5 Sonnet (Tokens : 79) > ChatGPT 4o (Tokens : 48) > HyperCLOVA X (Tokens : 33)
또한 토큰 수는 경제적으로도 매우 중요하므로 INPUT 기준으로 비용을 비교해보았습니다.
(환율 1달러당 1400원 기준)
- HyperCLOVA X(HCX-DASH-001) 기준 토큰 당 0.001 원
- HyperCLOVA X(HCX-003) 기준 토큰 당 0.005 원
- Claude 3.5 Sonnet 기준 토큰 당 0.0042 원
- ChatGPT 4o 기준 토큰 당 0.0035원
여기서 위 문장(애국가)을 처리한 토큰 수를 곱하여 최종 토큰 비용을 계산해보겠습니다.
- HyperCLOVA X(HCX-DASH-001) : 0.033 원
- HyperCLOVA X(HCX-003) : 0.165 원
- Claude 3.5 Sonnet : 0.3318 원
- ChatGPT 4o : 0.168 원
즉, 생성형 AI 모델별 애국가를 처리한 토큰 비용은 다음과 같이 HyperCLOVA X(HCX-DASH-001)가 가장 저렴한 것으로 확인되었습니다.
▶ Claude 3.5 Sonnet > ChatGPT 4o > HyperCLOVA X(HCX-003) > HyperCLOVA X(HCX-DASH-001)
위 토큰 비교 테스트는 적은 양의 문장으로 테스트해서 크게 비용차이가 없어보일 수 있으나 애국가와 같은 문장이 1000만개 정도 존재한다면 누구는 약 332만원을 지불하게 될 것이고 또 다른 누구는 33만원의 토큰 비용이 낼 것입니다.
물론 이는 애국가 기준이며 어떤 문장인지에 따라서 또 토큰 차이는 더 줄어들 수도 있고 더 늘어날 수도 있습니다. 하지만 우리는 사용할 생성형 AI가 언어의 성능이 좋아진 것만으로 좋아할 것이 아니라 토큰 성능이 얼마나 좋은지까지 보아야 생성형 AI로 비용 효율적인 서비스를 만들 수 있을 것입니다.
Personal Comments
지금까지 HyperCLOVA X와 함께 한국어 토큰화의 특성과 중요성을 살펴보았습니다. HyperCLOVA X는 한국어의 언어적 특성을 고려한 토큰화 방식을 통해 더 효율적인 처리가 가능하며 특히 토큰 사용량 측면에서 글로벌 모델들과 비교하여 상대적인 강점을 보입니다.
물론 토큰화 효율성만으로 모델의 우수성을 판단할 수는 없습니다.
실제 성능, 안정성, 비용 대비 효용, 서비스 지원 등을 종합적으로 고려해야 하므로 한국어 중심 서비스 개발에 있어 매력적인 선택지로 HyperCLOVA X를 포함하되 실제 서비스에 도입하기 위해서 프로젝트의 전반적인 요구사항에 적합한지 테스트가 진행되어야 할 것입니다.
긴 글 읽어주셔서 감사합니다.