
안녕하세요. MANVSCLOUD 김수현입니다.
최근 몇 년간 인공지능(AI) 기술은 급격히 발전하며 다양한 분야에서 그 활용도가 높아지고 있습니다. AI에 대한 사람들의 관심도 함께 증가하면서 연구와 개발이 활발하게 진행되고 있는데요. 이러한 AI 기술의 발전과 함께 단순히 AI 모델을 사용하는 것만으로는 한계가 있음을 느끼고 보다 신뢰할 수 있는 답변을 제공하기 위한 새로운 접근법들이 등장하고 있습니다.
특히 최신 데이터를 기반으로 더욱 정확한 정보를 제공하기 위해 AI 모델과 최신 데이터 소스를 어떻게 결합하여 신뢰도 있는 답변을 제공할지 많은 연구가 되고 있습니다.
저는 이러한 흐름 속에서 네이버 클라우드 플랫폼의 CLOVA Studio를 활용해 법률 판례 탐색기를 간단하게 개발보며 학습해보았습니다. 단순히 CLOVA Studio만 사용하는 대신 RAG(Retrieval-Augmented Generation)를 함께 사용하여 최신화된 데이터를 기반으로 신뢰도를 있는 답변을 제공하고자 했습니다.
네이버 클라우드 플랫폼을 활용하여 RAG 파이프라인을 구축하고 이를 CLOVA Studio와 연동하여 서비스를 만들었던 과정을 Cloud Architect 관점에서 공유드리겠습니다.
해당 포스트 작성을 위해 사용된 RAG는 Native RAG만 적용한 점 참고 부탁드립니다.
#1 서비스 소개

‘포켓법도감’이라는 이름의 법률 판례 탐색기(Legal Case Finder) 서비스를 만들어보았습니다.
이 법률 판례 탐색기는 AI 모델 HyperCLOVA X에서 발생할 수 있는 할루시네이션(잘못된 정보 생성)을 최소화하기 위해 RAG(Retrieval-Augmented Generation) 기술을 도입하여 보다 정확하고 신뢰할 수 있는 법률 정보를 제공하는 것을 목표로 했습니다.
할루시네이션 문제를 해결하기 위한 여러 가지 방법이 존재하지만 이 과정에서는 Tuning과 Skill Trainer 대신 RAG를 선택했는데요. Tuning의 경우 직접 데이터를 만들어야 하는데 다양한 사건별 판례를 매번 만들고 학습 시키기에 사실상 큰 어려움이 있습니다. 또한 Skill Trainer의 경우 API를 가져와 분석하고 제공하기에 빠르게 답변을 제공받을 수 없어 신속한 응답을 원했기에 적합한 선택지라 판단하지 않았습니다.
포켓법도감은 서버리스 아키텍처(Serverless Architecture)로 구현했습니다.
Cloud Functions를 활용하여 제한된 실행 시간 안에 모든 동작이 완료되도록 설계되었으며 이를 통해 비용 효율성을 극대화하면서도 높은 성능을 유지할 수 있었습니다. RAG를 통해 할루시네이션 문제를 해결하고 사용자에게 신뢰할 수 있는 답변을 제공할 수 있도록 했습니다.
데이터베이스는 네이버 클라우드에서 제공하는 관리형 PostgreSQL의 pgvector 기능을 활성화하여 VectorDB로 사용했고 HyperCLOVA X의 엔진으로는 HCX-003보다 경량화된 HCX-DASH-001을 사용하여 더 빠른 응답 속도를 얻을 수 있도록 했습니다.
포켓법도감은 테스트 환경이나 토이 프로젝트에 적합하도록 설계했기 때문에 아무래도 저와 같이 비용 부담을 최소화하면서도 쉽게 운영 및 관리할 수 있는 가벼운 테스트 아키텍처 구현이 필요하다면 도움이 될 것같습니다.
#2 서비스 소개
포켓법도감의 서비스 구조는 최신 법률 판례 데이터를 신속하고 정확하게 사용자에게 제공하기 위해 체계적으로 설계되었습니다. 이 서비스는 서버리스 아키텍처를 기반으로 구축되었으며 매일 주기적으로 최신 판례 데이터를 업데이트하고 사용자의 질의에 대한 응답을 제공합니다.
※ Flow
포켓법도감의 RAG(Cloud Functions – Action)는 매일 주기적으로 동작하여 VectorDB에 최신 판례 데이터를 업데이트합니다. 이 과정을 진행하기 위해 네이버 클라우드의 관리형 PostgreSQL의 pgvector 기능 활성화 했습니다. 이를 통해 사용자는 항상 최신화된 데이터를 바탕으로 법률 정보를 제공받을 수 있습니다.
또한 간단한 오브젝트 스토리지 PDF 파일 업로드와 사용자 질의(User Query)를 처리하는 API Gateway 주소를 포함하고 있습니다. 로컬 환경에서 원하는 내용과 디자인을 수정한 후 Push하면, CI/CD 파이프라인이 동작하여 반영됩니다. 추가로 네이버 클라우드의 CDN 서비스인 Global Edge를 사용하여 캐싱 기능 활용으로 사용자 UI를 더욱 빠르게 제공할 수 있도록 하였습니다.
사용자가 질의를 하면 해당 질의는 Embedding 후 최신 데이터가 포함된 VectorDB에서 유사도가 가장 높은 데이터 Top K 개수만큼 얻은 후 HyperCLOVA X LLM(HCX-DASH-001)을 거쳐 답변을 제공합니다. 이 모든 동작은 관리형 데이터베이스와 서버리스 서비스로 처리되므로 사용한 만큼만 비용이 발생하며 관리 포인트를 최소화하여 효율적인 운영이 가능합니다.
※ Architecture
- Frontend
포켓법도감의 프론트엔드는 Vue.js를 사용하여 간단하게 구현되었습니다. 로컬에서 Push하면, CI/CD 파이프라인을 통해 자동으로 빌드(Build) 및 배포(Deploy)되며, 업데이트된 파일은 오브젝트 스토리지에 업로드됩니다. 이를 통해 손쉽게 서비스 업데이트를 진행할 수 있으며, 글로벌 엣지(CDN) 서비스를 통해 빠르고 안정적인 서비스 제공이 가능합니다.
// 배포 전 “포켓법도감” 만 적혀져 있는 상태

// app.vue에서 <h1>포켓법도감</h1>을 <h1>포켓법도감(법률 판례 탐색기)</h1>로 변경 후 git push 진행
// 아래와 같이 자동으로 Build 및 Deploy 진행
// 큰 작업 없이 변경 및 Push로 간단하게 반영
- Backend
백엔드에서는 메인 RAG와 사용자 질의(User Query) 부분을 Cloud Functions(웹 액션)으로 사용할 수 있도록 코드가 변경되었습니다. 사용자 질의와 PDF 파일 업로드는 각각 API Gateway와 연동되어 처리됩니다. 이로 인해 백엔드에서는 모든 동작이 서버리스 방식으로 수행되며, 특정 시간 안에 모든 작업이 완료되도록 설계되었습니다.
- Main RAG
메인 RAG는 포켓법도감의 핵심적인 부분으로, 사용자가 신뢰할 수 있는 고품질의 답변을 제공하는 데 중점을 두고 있습니다. 최신 판례 데이터를 확보하기 위해 OpenAPI(국가법령정보 공동활용 API)를 통해 최신 판례 데이터만을 추가하도록 설정되었습니다. 이를 위해 prncYd(선고일자 검색)를 활용하여 최신 데이터만을 가져오며, Cron 트리거를 사용하여 하루에 한 번씩 업데이트되도록 설정하였습니다. 이렇게 함으로써 대량의 데이터를 한꺼번에 처리하지 않으면서도 Cloud Functions의 Time Out 문제를 방지할 수 있었습니다.
- User Query

사용자가 실제로 질의를 하고 답변을 받는 핵심 영역은 User Query 부분입니다.
사용자는 PDF 파일을 업로드할 수 있으며 PDF 파일의 내용이 많을 경우 요약 기능을 통해 내용을 축약할 수 있습니다. 이 과정에서 CLOVA Studio(Summarization API)는 원하는 방향으로 요약이 되지 않아 CLOVA Summary 활용해봤습니다.
사용자 질의와 PDF 파일 내용을 벡터화하여 VectorDB에 검색 후 HyperCLOVA X LLM을 통해 최종 답변을 제공합니다. 이 과정에서 사용되는 엔진은 경량화된 HCX-DASH-001으로 빠르고 정확한 응답을 가능하게 합니다.
// Cloud Functions + API Gateway로 PDF 파일을 Object Storage에 업로드
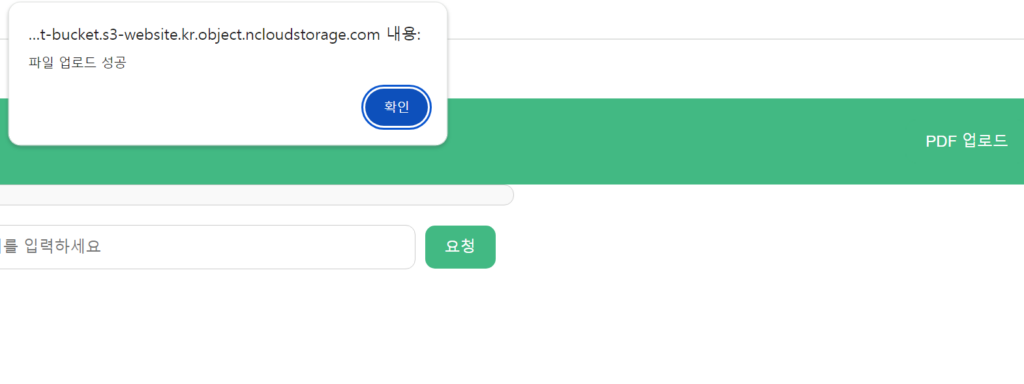
// 업로드된 PDF 파일을 요약 및 참고하여 답변 생성
※ Result
이 서비스는 PDF 업로드, 사용자 질의, RAG의 모든 Action이 별도로 분리되어 Cloud Functions의 최대 실행 시간 이내에 동작하게 설계되었습니다. 이를 통해 TimeOut 문제를 방지하면서도 신속한 서비스를 제공할 수 있습니다. 또한 Source Commit, Build, Deploy Pipeline을 통해 간단하고 쉬운 배포 및 관리가 가능하며 Global Edge를 활용해 빠른 서비스 제공 및 Server가 아닌 Cloud Functions을 사용하여 고정적인 비용이 발생하지 않고 사용한 만큼만 비용이 발생하기에 사용자가 없는 경우에도 비용 부담을 줄일 수 있는 효율적인 구조를 갖추고 있습니다.
즉, 이 아키텍처로 구성된 서비스는 사용자가 없더라도 Cloud DB for PostgreSQL(DB) 비용 월 113,760원만 발생하게 됩니다.
#3 질문/답변 비교
포켓법도감은 일반적으로 제공되는 LLM와 비교하여 성능과 정확도 면에서 큰 차별성을 보여줍니다. 이를 검증하기 위해 제가 만든 포켓법도감과 네이버 클라우드의 대표적인 AI 모델인 HCX-003 그리고 Claude 3 Opus를 비교하여 그 성능을 검증해보겠습니다.
음주운전 관련 판례에 대해 실제 사건 번호가 존재하는지 확인하는 테스트를 진행했고 그 결과를 아래와 같이 공유드립니다.
- CLOVA Studio – 플레이그라운드 – HCX-003
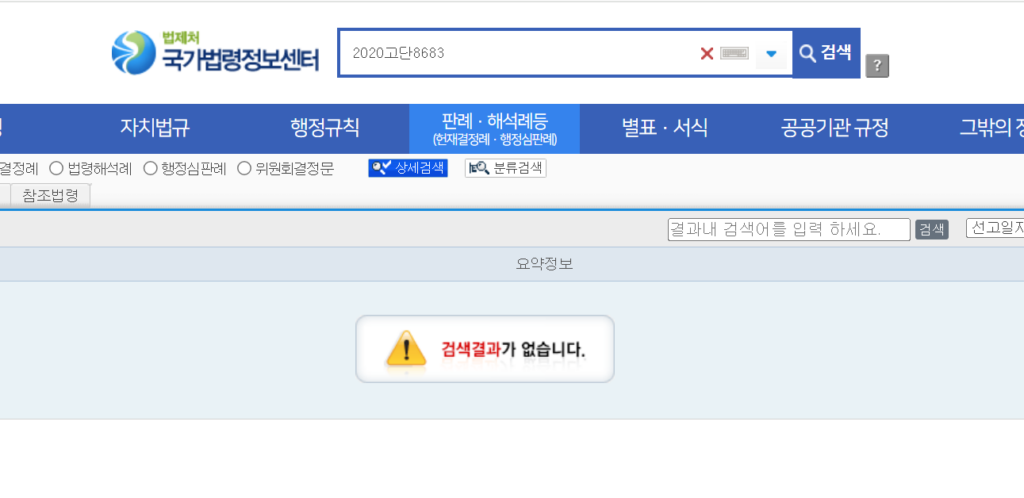
첫 번째로 CLOVA Studio의 플레이그라운드에서 HCX-003 엔진을 사용하여 음주운전 관련 판례를 질문해보았습니다. 질문 시 아래와 같이 답변을 주지만 해당 판례를 실제 국가법령정보센터에 검색 시 존재하지 않는 사건 번호였습니다. 이는 HCX-003 엔진이 정확한 데이터를 바탕으로 하지 않고 생성된 정보를 제공했기 때문입니다.
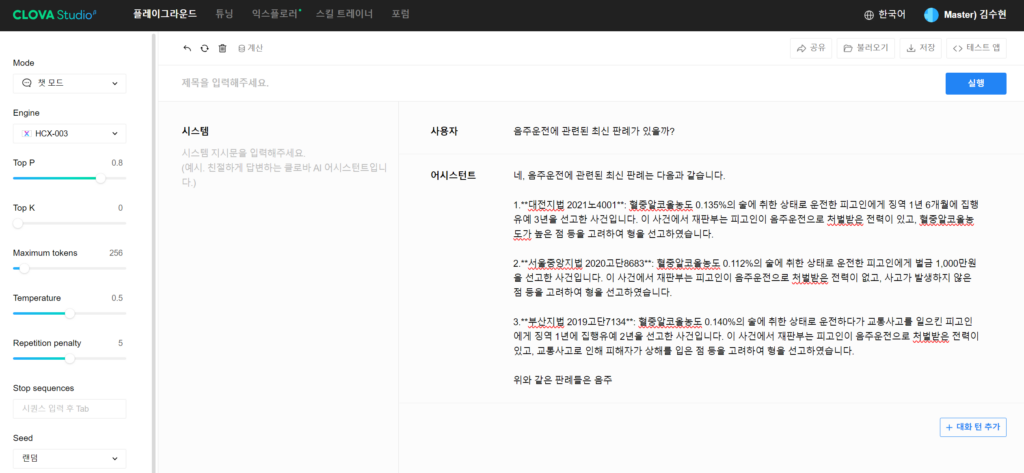
- Claude 3 Opus
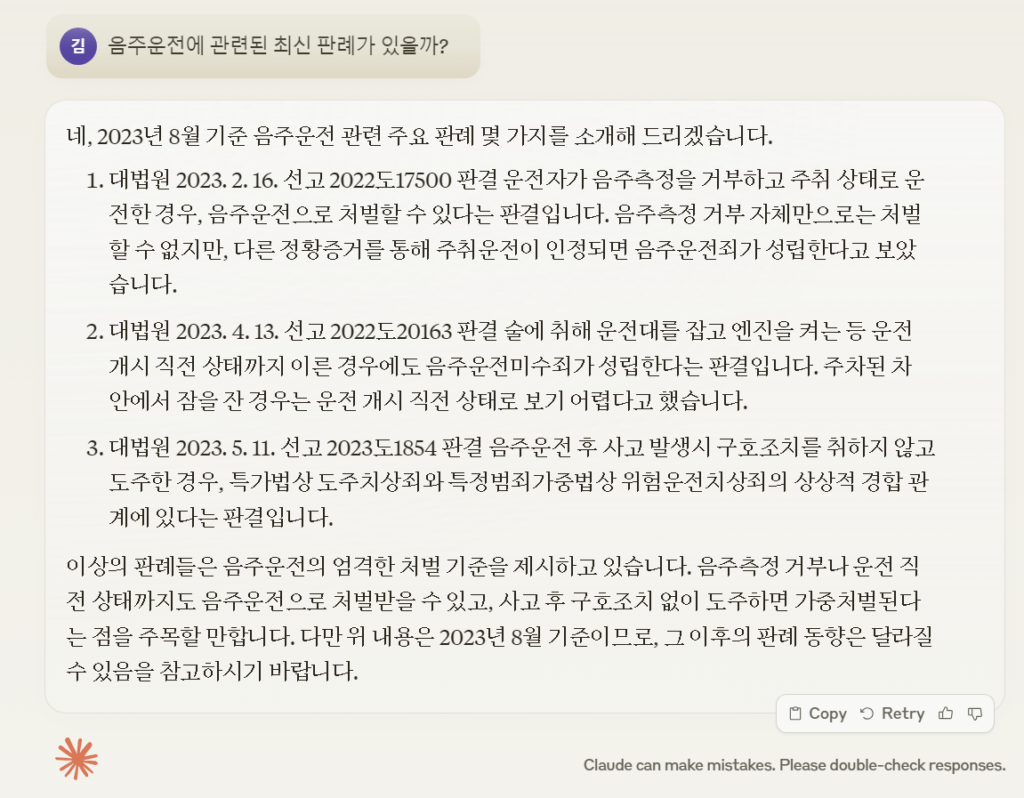
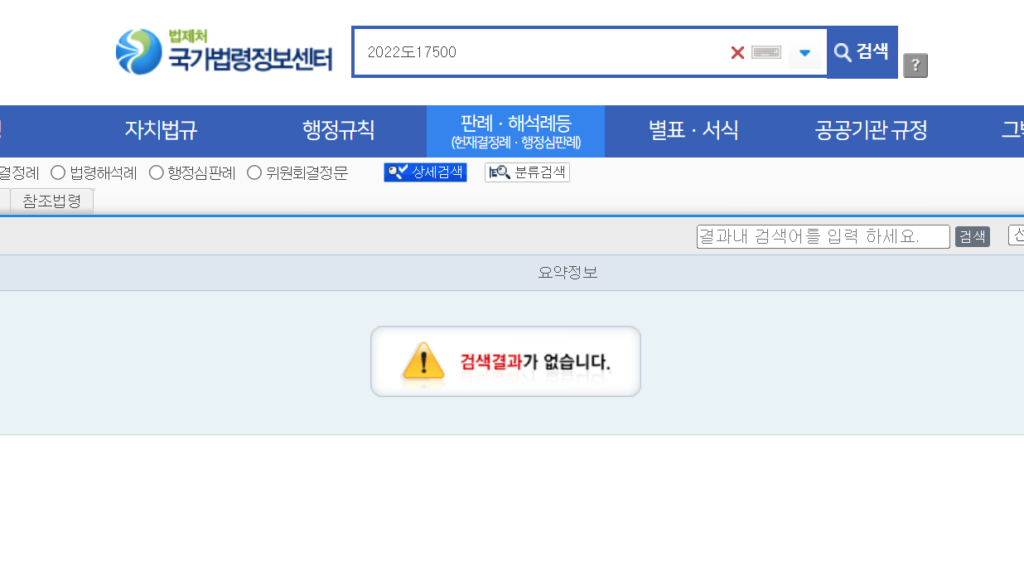
두 번째로 최근 ChatGPT의 라이벌이자 특정 영역에서는 더 좋은 성능을 보여주고 있는 Anthropic사의 Claude로 테스트를 진행했습니다. Claude 3 Opus를 사용하여 동일한 질문을 해보았습니다. 그러나 Claude 역시 음주운전 관련 판례에 대한 질문에 답변을 제공했으나 제공된 사건 번호를 국가법령정보센터에서 검색했을 때 실제로 존재하지 않는 사건 번호임이 밝혀졌습니다.
- 포켓법도감(법률 판례 탐색기) – HCX-DASH-001, RAG Pipeline
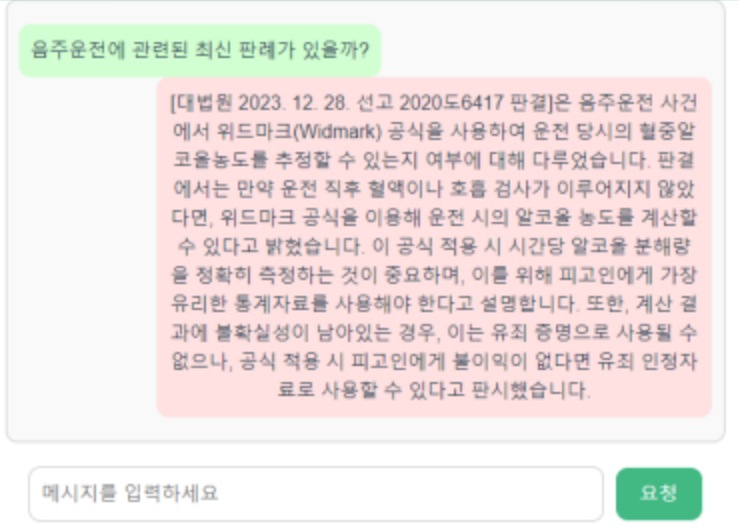
마지막으로 제가 만든 포켓법도감을 사용하여 음주운전 관련 판례를 질문해보았습니다. 포켓법도감은 HyperCLOVA X의 경량화 모델은 HCX-DASH-001를 사용했음에도 불구하고 RAG Pipeline을 통해 최신화된 데이터를 기반으로 답변을 생성하여 신뢰할 수 있는 정보를 제공받을 수 있었습니다. 위와 같이 동일한 질문을 진행했을 때 실제로 포켓법도감에서 제공한 사건 번호를 국가법령정보센터에서 검색해본 결과 실제로 존재하는 판례가 확인되었으며 내용 역시 일치함을 알 수 있었습니다.
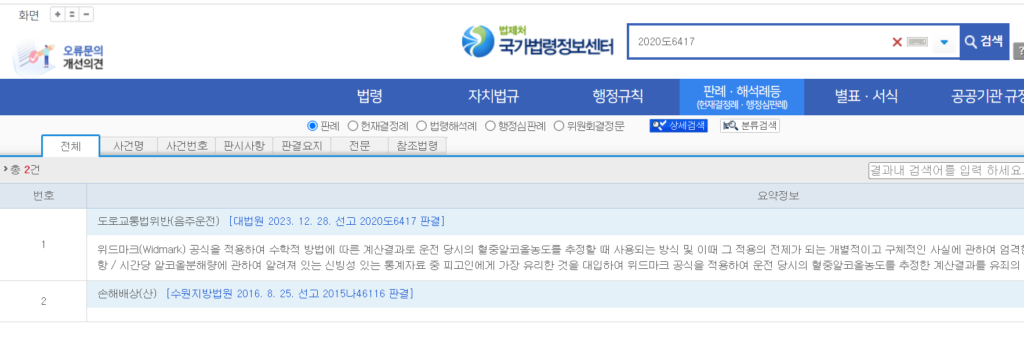
이 테스트를 통해 최근에 나오는 언어 모델들이 경량화 되어 나오는지도 알 것같습니다.
얼마 전까지만 해도 “우리 모델은 몇백억 개, 몇천억 개의 방대한 파라미터를 가진 대규모 언어 모델(LLM)이다” 라며 거대한 언어 모델을 내세운 반면 최근에는 경량화 모델들이 많이 나오고 있습니다. 아무리 거대한 LLM이 나온다고 해도 지속적으로 새로운 데이터를 학습해야만 한다면 결국 거대해진 데이터로 인해 속도와 비용만 더욱 커질 것입니다. 그리고 이런 거대한 LLM이라도 실시간에 가까운 최신 데이터를 얻을 수 없기 때문에 경량화된 모델이 나오거나 특수 목적에 맞는, 개인화 또는 특정 기업 특성에 맞는 가벼운 모델이 개발되는 것이라 생각됩니다. 실제로 HCX-003과 HCX-DASH-001 두 모델의 속도 측정해봤을 때 실제 서비스에 적용하면 좋을 것같은 모델은 HCX-DASH-001이었습니다.
어차피 최신화 정보나 특수한 데이터의 경우 아무리 좋다는 모델을 갖다 놔도 할루시네이션을 만들어낼 것이니 조금 섬세한 작업이 필요한 건 파인 튜닝을 통해 조금 조정하고 RAG를 구축해서 실시간 정보 검색을 통해 답변 신뢰도를 높이자 이겁니다.
Personal Comments
이번 테스트를 통해 결국 실시간 정보 검색, 특정 기업 데이터 정보 이런 것들은 HCX, GPT 등과 같은 언어 모델은 크게 중요하지 않은 것같다는 결론에 도달했습니다. 오히려 해당하는 언어 모델의 강점을 파악할 필요가 있습니다. 대표적으로 HCX의 경우 한국어를 잘 한다고 알려져 있습니다.
하지만 최근에는 HCX 외에도 다양한 언어 모델들의 한국어 능력이 상승하고 있는데요.
HCX의 강점은 한국어 뿐만 아니라 한국 역사, 한국 문화, 법, 한국의 세부적인 지리, 주소 등에 더 강하다는 것이죠. 따라서 동일하게 RAG 파이프라인을 구축하더라도 Vector DB에서 얻은 데이터를 결국 LLM이 답변을 만들어 제공해야 하는데 조금 더 한국적인 느낌으로 답변 제공이 필요하다면 GPT나 Llama보다 HCX가 더욱 효율적이라는 것입니다.
※ 예시
“과랑 과랑혼 벳디 일 호젠 호난 속았수다”라는 제주도 사투리의 의미를 아래와 같이 각각 질문해 보았습니다.
- ChatGPT 4o
: “사람이 많은 곳에서 일하느라 정신이 없었어요.”

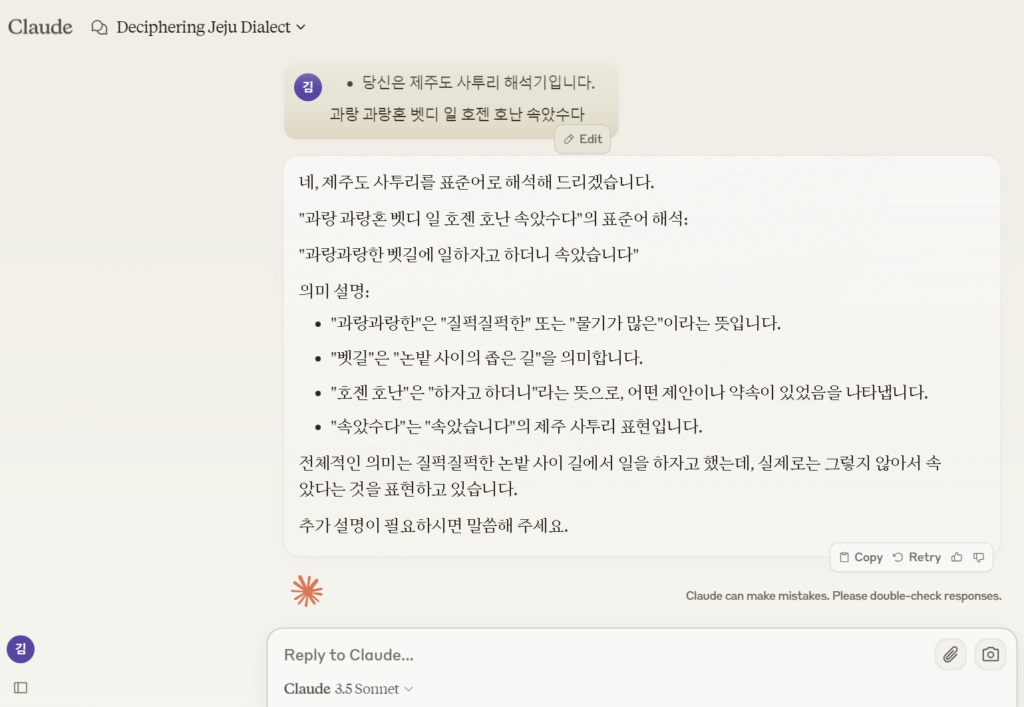
- Claude 3.5 Sonnet
: “과랑과랑한 벳길에 일하자고 하더니 속았습니다”
- HCX-DASH-001
: “쨍쨍한 햇볕에 일하려고 하니 수고하셨습니다”
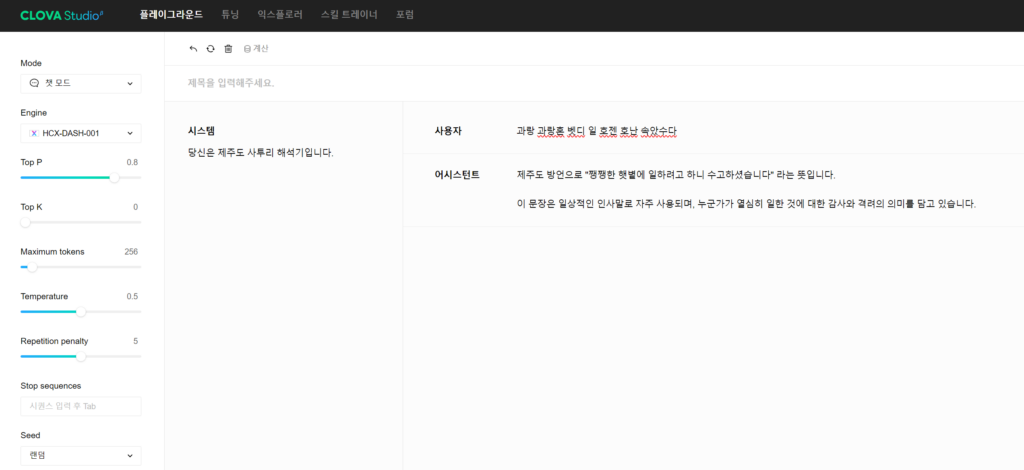
HyperCLOVA X의 HCX-DASH-001 모델을 통해서만 정확한 답변을 받을 수 있었습니다.
즉, “{Vector DB에서 얻은 제주도 언어 데이터}를 표준어로 번역해줘” 라던가, “{Vector DB에서 얻은 데이터}를 제주도 언어로 변경해줘” 같은 서비스가 필요하다면 HCX가 조금 더 우월한 성능을 보일 수 밖에 없는 강점이 있다는 겁니다.
따라서 각 언어 모델별 강점을 테스트하고 서비스에 적용할 필요가 있다는 점을 말하고자 합니다.
다음 포스팅에서는 CLOVA Studio의 문단 나누기(Chunking) API 파헤치기, HCX-003와 HCX-DASH-001 속도 비교 등 더욱 흥미로운 주제로 준비해보겠습니다.
긴 글 읽어주셔서 감사합니다.