
안녕하세요. MANVSCLOUD 김수현입니다.
지난 “CLOVA AI : 한국에 특화된 인공지능” 포스팅에서 CLOVA Speech를 사용하여 영상 속 음성 및 음성을 텍스트로 변환해보았는데요.
이번 포스팅에서는 인공신경망 기반의 기계 번역 기술을 활용한 Papago Translation 서비스에 대해 알아보려고 합니다.
AI 기술의 진보는 우리의 일상 속에 깊숙이 자리 잡고 있는데 그중에서도 기계 번역은 세계를 더욱 가까이 연결하는 중요한 역할을 하고 있습니다.
Papago Translation를 사용해보며 AI와 언어의 미래에 대해 생각해 보는 시간을 가져보도록 하겠습니다.
Papago Translation
Papago Translation은 인공신경망 기반의 기계 번역 서비스로, 현대 기술의 진보를 반영한 효율적인 언어 해석 솔루션을 제공합니다. 이 서비스를 이용하여 복잡한 언어 패턴과 문맥을 분석하여 높은 수준의 정확도와 자연스러운 번역을 실현할 수 있는데요.
어떻게 하면 Papago Translation으로 다양한 언어의 장벽을 효과적으로 넘어설 수 있을까요?
그리고 어떻게 인공신경망을 통해 언어의 미묘한 뉘앙스까지 포착하는지 궁금하시지 않나요?
바로 인공신경망 기반의 기계 번역, 즉 Neural Machine Translation(NMT)을 활용하는 것입니다.
이 기술은 인간의 언어 습득 방식을 모방하여 복잡한 언어 패턴과 문맥을 더욱 정교하게 분석할 수 있는데요. 아무래도 전통적인 규칙 기반 번역보다 유연하다보니 실제 인간이 사용하는 언어에 가까운 결과를 제공합니다.
NMT는 대규모 언어 데이터를 학습하여 문맥, 어휘, 문법 구조를 파악하고 이를 바탕으로 번역을 수행할 수 있습니다. Papago Translation은 이러한 NMT 기술을 기반으로 다양한 기능을 제공하기 때문에 텍스트 번역 기능을 통해 일상적인 대화나 전문적인 문서를 번역할 수 있으며 문서 번역 기능은 원본 문서의 레이아웃을 유지하면서 내용을 정확하게 번역합니다.
또한 웹 번역 기능으로 인터넷 상의 다양한 자료를 쉽고 빠르게 이해할 수 있습니다.
웹 페이지 번역의 경우 Papago만의 태그 복원 기술이 있어 웹 번역의 정확도를 더욱 높이고 있습니다. 그 외 언어 감지 기능을 이용하여 사용자가 입력하는 텍스트(언어)를 자동으로 감지하고 번역 과정을 간소화할 수도 있구요.
Papago Translation은 이처럼 고도화된 기술력과 사용자 친화적인 인터페이스를 통해 언어 장벽을 허물고 세계적으로 연결된 커뮤니케이션의 가능성을 더욱 확장시키고 사용자 친화적인 인터페이스로 언어 학습 및 소통의 편리함을 제공하고 있습니다.
“CLOVA AI : 한국에 특화된 인공지능” 포스팅에서 음성 언어를 문자 데이터로 전환하는 STT(Speech-to-Text) 서비스인 CLOVA Speech를 활용해보았었는데요.
CLOVA Speech를 이용하여 변환된 텍스트를 이제 Papago Translation을 이용하여 다른 언어로번역을 해보도록 하겠습니다.
Hands On Lab
CLOVA Speech를 통해 변환된 텍스트은 Obejct Storage에 결과 파일로 저장할 수 있는데요.
이 Hands On Lab 과정에서는 Object Storage에 저장된 결과 파일(.json)을 읽어 Papago Translation로 번역하는 것까지 진행해보도록 하겠습니다.
Papago Translation 서비스는 카테고리에서 [AI Services] – [Papago Translation]를 선택하여 사용할 수 있습니다.
서비스를 사용하기 위해서는 먼저 Subscription(상품 이용 신청) 과정이 우선 시 되어야하며 사용할 API를 선택하여 원하는 기능만 사용할 수 있습니다.
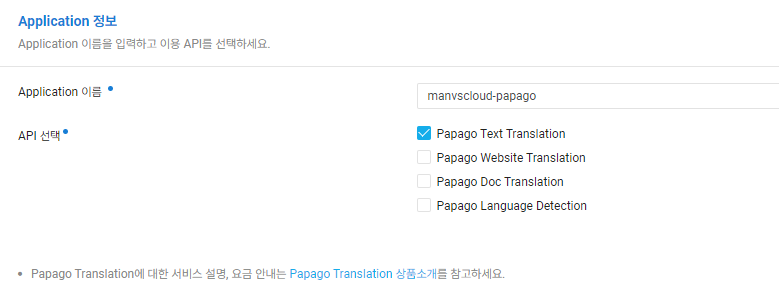
이 과정에서는 Papago Text Translation을 기능만 사용됩니다.
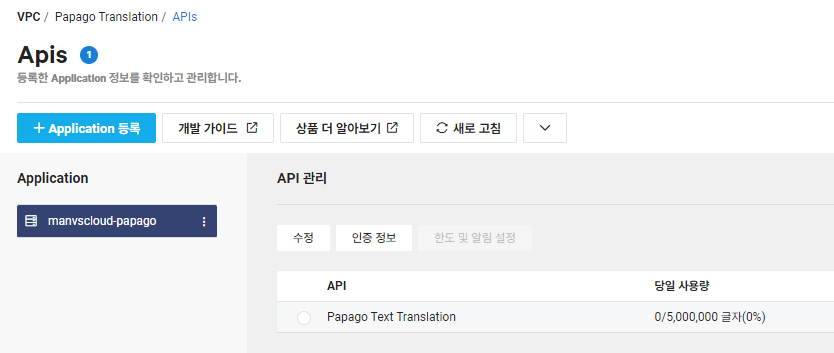
Papago Translation – APIs에서 등록한 Application을 선택하면 위 이미지와 같이 [수정]을 통해 기능을 선택하여 사용할 API를 더 추가하거나 제거할 수 있습니다.
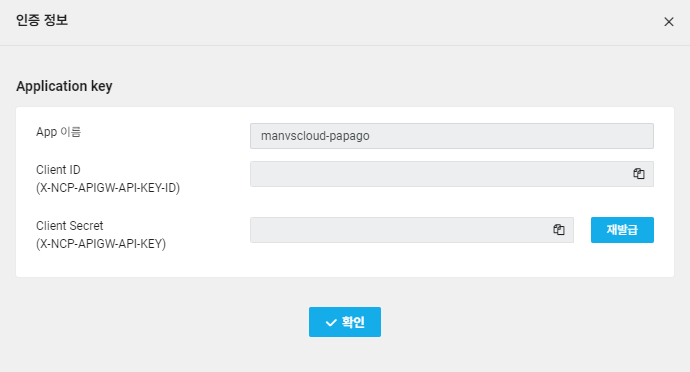
또한 [인증 정보]를 선택하면 해당 Application에 대한 Key를 확인할 수 있습니다.
Client ID 및 Client Secret은 실습 시 필수이며 해당 Key 정보가 외부에 유출될 경우 큰 피해로 이어질 수 있으므로 철저히 관리할 필요가 있습니다.
이제 Papago Translation을 사용하여 텍스트를 다른 언어로 번역해보도록 하겠습니다.
Object Storage에 있는 텍스트 파일을 따로 다운로드하지 않고 읽는 방법은 위 URL을 참고하시기 바랍니다. 해당 Hands On Lab에는 이 과정에 대해 설명없이 코드에 포함되어 있습니다.
import hashlib
import hmac
import datetime
import requests
import urllib.parse
import xml.etree.ElementTree as ET
import json
import os
import sys
import urllib.request
def get_hash(key, msg):
return hmac.new(key, msg.encode('utf-8'), hashlib.sha256).digest()
def create_signed_headers(headers):
signed_headers = []
for k in sorted(headers):
signed_headers.append('%s;' % k)
return ''.join(signed_headers)[:-1]
def create_standardized_headers(headers):
signed_headers = []
for k in sorted(headers):
signed_headers.append('%s:%s\n' % (k, headers[k]))
return ''.join(signed_headers)
def create_standardized_query_parameters(request_parameters):
standardized_query_parameters = []
if request_parameters:
for k in sorted(request_parameters):
standardized_query_parameters.append('%s=%s' % (k, urllib.parse.quote(request_parameters[k], safe='')))
return '&'.join(standardized_query_parameters)
else:
return ''
class ObjectStorageSample:
def __init__(self):
self.region = 'kr-standard'
self.endpoint = 'https://kr.object.ncloudstorage.com'
self.host = 'kr.object.ncloudstorage.com'
self.access_key = '[ACCESS_KEY_ID]' # Object Storage 권한이 있는 ACCESS_KEY_ID
self.secret_key = '[SECRET_KEY]' # Object Storage 권한이 있는 SECRET_KEY
self.payload_hash = 'UNSIGNED-PAYLOAD'
self.hashing_algorithm = 'AWS4-HMAC-SHA256'
self.service_name = 's3'
self.request_type = 'aws4_request'
self.time_format = '%Y%m%dT%H%M%SZ'
self.date_format = '%Y%m%d'
def _create_credential_scope(self, date_stamp):
return date_stamp + '/' + self.region + '/' + self.service_name + '/' + self.request_type
def _create_canonical_request(self, http_method, request_path, request_parameters, headers):
standardized_query_parameters = create_standardized_query_parameters(request_parameters)
standardized_headers = create_standardized_headers(headers)
signed_headers = create_signed_headers(headers)
canonical_request = (http_method + '\n' +
request_path + '\n' +
standardized_query_parameters + '\n' +
standardized_headers + '\n' +
signed_headers + '\n' +
self.payload_hash)
return canonical_request
def _create_string_to_sign(self, time_stamp, credential_scope, canonical_request):
string_to_sign = (self.hashing_algorithm + '\n' +
time_stamp + '\n' +
credential_scope + '\n' +
hashlib.sha256(canonical_request.encode('utf-8')).hexdigest())
return string_to_sign
def _create_signature_key(self, date_stamp):
key_date = get_hash(('AWS4' + self.secret_key).encode('utf-8'), date_stamp)
key_string = get_hash(key_date, self.region)
key_service = get_hash(key_string, self.service_name)
key_signing = get_hash(key_service, self.request_type)
return key_signing
def _create_authorization_header(self, headers, signature_key, string_to_sign, credential_scope):
signed_headers = create_signed_headers(headers)
signature = hmac.new(signature_key, string_to_sign.encode('utf-8'), hashlib.sha256).hexdigest()
return (self.hashing_algorithm + ' ' +
'Credential=' + self.access_key + '/' + credential_scope + ', ' +
'SignedHeaders=' + signed_headers + ', ' +
'Signature=' + signature)
def _sign(self, http_method, request_path, headers, time, request_parameters=None):
time_stamp = time.strftime(self.time_format)
date_stamp = time.strftime(self.date_format)
credential_scope = self._create_credential_scope(date_stamp)
canonical_request = self._create_canonical_request(http_method, request_path, request_parameters, headers)
string_to_sign = self._create_string_to_sign(time_stamp, credential_scope, canonical_request)
signature_key = self._create_signature_key(date_stamp)
headers['authorization'] = self._create_authorization_header(headers, signature_key, string_to_sign, credential_scope)
def list_objects(self, bucket_name, request_parameters=None):
http_method = 'GET'
time = datetime.datetime.utcnow()
time_stamp = time.strftime(self.time_format)
headers = {'x-amz-date': time_stamp,
'x-amz-content-sha256': self.payload_hash,
'host': self.host}
request_path = '/%s' % bucket_name
self._sign(http_method, request_path, headers, time, request_parameters)
request_url = self.endpoint + request_path
r = requests.get(request_url, headers=headers, params=request_parameters)
if r.status_code == 200:
root = ET.fromstring(r.content)
objects = []
for content in root.findall('{http://s3.amazonaws.com/doc/2006-03-01/}Contents'):
key = content.find('{http://s3.amazonaws.com/doc/2006-03-01/}Key').text
if key.endswith('.json'):
last_modified = content.find('{http://s3.amazonaws.com/doc/2006-03-01/}LastModified').text
objects.append({'Key': key, 'LastModified': last_modified})
objects.sort(key=lambda x: x['LastModified'], reverse=True)
return objects
else:
return []
def read_json_object(self, bucket_name, object_name):
http_method = 'GET'
time = datetime.datetime.utcnow()
time_stamp = time.strftime(self.time_format)
headers = {'x-amz-date': time_stamp,
'x-amz-content-sha256': self.payload_hash,
'host': self.host}
request_path = '/%s/%s' % (bucket_name, object_name)
self._sign(http_method, request_path, headers, time)
request_url = self.endpoint + request_path
r = requests.get(request_url, headers=headers)
if r.status_code == 200:
content = json.loads(r.content.decode('utf-8'))
# 'text' 키에 해당하는 내용만 반환
return content.get('text', '')
if __name__ == '__main__':
sample = ObjectStorageSample()
objects = sample.list_objects('[BUCKET_NAME]', {'max-keys': '10'})
if objects:
most_recent_object = objects[0] # 가장 최신의 .json 파일
text_to_translate = sample.read_json_object('[BUCKET_NAME]', most_recent_object['Key'])
# 네이버 Papago Text Translation API 사용
client_id = "[CLIENT_ID]" # 클라이언트 ID
client_secret = "[CLIENT_SECRET]" # 클라이언트 Secret
encText = urllib.parse.quote(text_to_translate)
data = "source=ko&target=en&text=" + encText
url = "https://naveropenapi.apigw.ntruss.com/nmt/v1/translation"
request = urllib.request.Request(url)
request.add_header("X-NCP-APIGW-API-KEY-ID", client_id)
request.add_header("X-NCP-APIGW-API-KEY", client_secret)
response = urllib.request.urlopen(request, data=data.encode("utf-8"))
rescode = response.getcode()
if(rescode == 200):
response_body = response.read()
translated_text = json.loads(response_body.decode('utf-8'))['message']['result']['translatedText']
print(translated_text)
else:
print("Error Code:" + rescode)
위 코드는 Python 3.8.18 버전 기준으로 작성되었으며 한국어를 영어로 변환하는 코드입니다. 또한 Object Storage에 저장된 파일은 CLOVA Speech를 사용하여 음성 언어가 텍스트로 변환된 결과 파일(.json)을 기준으로 파싱되었습니다. 동일한 기준이 아니라면 코드 수정이 필요할 수 있습니다.
코드에 포함된 [ACCESS_KEY_ID], [SECRET_KEY], [BUCKET_NAME], [CLIENT_ID], [CLIENT_SECRET]는 각 항목에 맞게 수정이 필요합니다.
- [ACCESS_KEY_ID] : Object Storage에 대한 권한을 보유한 Sub Account의 Access Key
- [SECRET_KEY] : Object Storage에 대한 권한을 보유한 Sub Account의 Secret Key
- [BUCKET_NAME] : CLOVA Speech를 사용하여 텍스트로 변환된 .json파일이 있는 Object Storage의 Bucket Name
- [CLIENT_ID] : Papago Translation의 Application Key 중 Client ID
- [CLIENT_SECRET] : Papago Translation의 Application Key 중 Client Secret
아래는 Object Storage에 저장된 .json 파일 중 “text” 부분에 대한 내용은 아래와 같습니다.
"text":"네이버 클라우드 플랫폼은 네이버가 지난 20년간 쌓아온 기술력을 담은 퍼블릭 클라우드 서비스입니다. 네이버가 국내 최대 포털 사이트로 자리 잡고 라인 메신저가 전 세계에서 사랑받기 길러낸 기술력을 이제 여러분들도 네이버 클라우드 플랫폼을 통해 손쉽게 이용하실 수 있습니다. 대기업은 물론 공공기관 교육금융 금리고 게임 산업까지 네이버 클라우드 플랫폼의 손길이 필요한 곳 어디든 네이버의 기술력을 손쉽게 적용할 수 있습니다. 지원이 필요한 스타트업과 학생들도 네이버 클라우드 플랫폼의 생태계 안에서 함께 성장하고 있습니다. 그렇다면 고객들은 어떤 부분에서 네이버 클라우드 플랫폼에 매력을 느끼고 있을까요. csa 스타 골드 인증을 획득하여 클라우드 기술력을 세계적으로 인정받았으며 csap 인증 취득으로 국내 공공기관 서비스 제공 자격을 갖추게 되었습니다. 뿐만 아니라 24시간 365일 고객 지원으로 다양한 이슈에 발 빠르게 대처하고 있습니다. 클라우드 서비스에서 발생하는 이슈는 고객의 비즈니스와 직결되는 만큼 밀착 지원이 필요하죠 한국에 본사를 두고 있기 때문에 국내 비즈니스에 특화된 지원 프로그램은 타사와는 차별화된 고객 경험을 제공하고 있습니다. 또한 비즈니스에 꼭 필요한 서비스를 모두 갖춘 서비스 포트폴리오 역시 네이버 클라우드 플랫폼이 많은 기업들에게 각광받고 있는 이유입니다. 기본적인 인프라 상품군부터 네이버의 기술력이 집약된 지도 챗봇 음성인식과 같은 api 서비스와 ai 모니터링 보안 상품까지 고객의 안정적인 서비스에 필요한 다양한 상품 라인업을 갖추고 있습니다. 네이버 한 바퀴를 도는 도움을 주고 있습니다. 네이버 클라우드 플랫폼의 진짜 도전은 이제부터 시작입니다. 더 많은 비즈니스와 만나 네이버와 함께 성장할 수 있도록 하고자 합니다. 또 하이브리드 클라우드를 통해 각종 규제와 정책의 이유로 클라우드 도입이 어려운 고객에게 적합한 데이터센터 환경을 직접 제공하면서 더 많은 비즈니스와 만나 성장을 도울 것입니다. 네이버 클라우드 플랫폼이 여러분과 함께 하겠습니다."
“text” 부분을 파싱하여 Papago Translation 서비스가 동작하면 다음과 같이 결과를 얻을 수 있습니다.
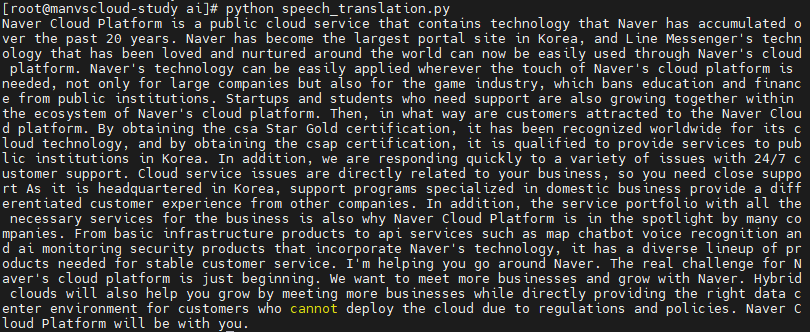
Naver Cloud Platform is a public cloud service that contains technology that Naver has accumulated over the past 20 years. Naver has become the largest portal site in Korea, and Line Messenger's technology that has been loved and nurtured around the world can now be easily used through Naver's cloud platform. Naver's technology can be easily applied wherever the touch of Naver's cloud platform is needed, not only for large companies but also for the game industry, which bans education and finance from public institutions. Startups and students who need support are also growing together within the ecosystem of Naver's cloud platform. Then, in what way are customers attracted to the Naver Cloud platform. By obtaining the csa Star Gold certification, it has been recognized worldwide for its cloud technology, and by obtaining the csap certification, it is qualified to provide services to public institutions in Korea. In addition, we are responding quickly to a variety of issues with 24/7 customer support. Cloud service issues are directly related to your business, so you need close support As it is headquartered in Korea, support programs specialized in domestic business provide a differentiated customer experience from other companies. In addition, the service portfolio with all the necessary services for the business is also why Naver Cloud Platform is in the spotlight by many companies. From basic infrastructure products to api services such as map chatbot voice recognition and ai monitoring security products that incorporate Naver's technology, it has a diverse lineup of products needed for stable customer service. I'm helping you go around Naver. The real challenge for Naver's cloud platform is just beginning. We want to meet more businesses and grow with Naver. Hybrid clouds will also help you grow by meeting more businesses while directly providing the right data center environment for customers who cannot deploy the cloud due to regulations and policies. Naver Cloud Platform will be with you.
번역 수준은 이미 papago.naver.com(파파고)를 사용해봤다면 아시겠지만 상당히 높은 수준으로 번역을 잘 해줍니다. 물론 좋은 결과를 얻기 위해서는 원본 데이터(기존 텍스트)가 중요하지만요.
이 Hands On을 통해서 우리는 CLOVA Speech로 음성 언어를 텍스트로 변환했을 때 Papago Translation으로 번역까지 할 수 있는 방법을 배웠습니다.
Personal Comments
Papago Translation 서비스의 모든 기능을 사용하지는 않았지만 다양한 기능이 있음을 알았고 서비스를 어떻게 활용할 수 있는지 하나의 실습을 통해 알아보았습니다.
STT(Speech-to-Text) 기술과 결합하여 음성을 텍스트로 변환하고 이를 다양한 언어로 번역하는 과정을 최대한 이 포스팅에 담아보려고 했는데요. 이를 통해 언어의 장벽을 넘어서는 데 AI가 어떻게 기여할 수 있는지 확인할 수 있었습니다.
이러한 기술의 진보는 우리가 세계와 소통하는 방식을 혁신적으로 변화시키고 있습니다.
이 포스팅을 통해 우리는 동영상이나 녹음 파일을 Object Storage로 저장시키고 저장된 음성 파일을 CLOVA Speech를 이용하여 텍스트 파일로 변환하고 이어서 번역까지 자동화할 수 있게 되었습니다. 다음 포스팅은 번역된 텍스트를 다시 음성으로 변환하는 CLOVA Voice 서비스에 대해 알아보도록 하겠습니다.
긴 글 읽어주셔서 감사합니다.
