
안녕하세요. MANVSCLOUD 김수현입니다.
클라우드 컴퓨팅과 함께 비용 관리는 더욱 핵심 과제가 되었습니다.
예측 불가능한 비용 증가는 기업의 예산을 크게 초과할 수 있으며 이는 재정적 위험으로 이어질 수 있으며 이제는 많은 유저들이 비용에 대한 관심을 갖기 시작했습니다.
AWS의 경우에는 AWS Cost Anomaly Detection 기능을 활용할 수 있습니다.
그렇다면 네이버 클라우드에서는 어떻게 비용을 예측하고 비교하고 이상 탐지를 할 수 있을까요? 우선 네이버 클라우드의 경우 현재 비용 이상 탐지에 대한 서비스 또는 기능을 기본적으로 제공하지 않고 있으며 Cloud Insight를 통한 비용 모니터링 및 알림 설정 역시 불가능한 상황입니다.
이러한 제약에도 불구하고 클라우드 비용 관리의 중요성은 날로 증가하고 있으니 서비스 또는 기능이 없다고 관심을 갖지 않는 것은 잘못되었다고 봅니다. 따라서 네이버 클라우드 환경에서 비용 이상 탐지 시스템을 구축한 아이디어를 공유드리고자 합니다.
다행히도 네이버 클라우드에서 제공하는 비용 관련 API를 활용하면 사용자가 직접 비용 이상 탐지 시스템을 구현할 수 있습니다. 이 글에서는 네이버 클라우드 환경에서 어떻게 비용 이상 탐지 시스템을 구축하고 비용 예측 및 알림을 받을 수 있는지 알아보겠습니다.
“전체 과정을 모두 공유하기에 내용이 방대하여 이 포스트에서는 InfluxDB 등 소프트웨어 설치 과정 및 전체 코드를 공유하지 않습니다. 따라서 아이디어와 프로세스를 이해하신 후 응용하여 직접 구현해보시는 것을 권장합니다.”
Cost Anomaly Detection
클라우드 환경에서의 비용 관리는 점점 더 복잡해지고 있습니다.
FinOps는 이러한 복잡성을 관리하기 위한 체계적인 접근 방식을 제공합니다.
그 중에서도 비용 이상 탐지는 FinOps의 중요한 관행 중 하나입니다.

비용 이상 탐지가 가능하다면 예상치 못한 또는 예측하지 못한 클라우드 비용 및 사용량 불규칙성을 적시에 감지, 식별, 경고 및 관리하여 비용 효율적인 클라우드 운영할 수 있으며 사전에 큰 비용이 발생할 수 있는 위험 요소를 사전에 파악할 수 있습니다. 따라서 비용 이상 탐지는 단순한 모니터링 그 이상의 의미를 가집니다.
결국 비용 이상이란 “예상치 못한 또는 설명할 수 없는 클라우드 비용의 변동”으로 정의할 수 있는데 다음과 같은 형태로 비용 이상이 나타날 수 있습니다.
- 갑작스러운 비용 증가
- 지속적인 비용 상승 추세
- 예상보다 높은 비용
- 비정상적으로 낮은 비용
위 형태와 같이 과거 지출 패턴을 고려했을 때 예상 했던 것보다 큰 폭의 클라우드 지출 변동이 있다면 이는 이상 현상이라 볼 수 있는데요.
클라우드 비용 이상을 관리하는 것은 예산 초과 방지, 비용 최적화 기회 식별, 보안 문제 조기 발견 (비정상적인 사용량은 보안 침해의 징후일 수 있음), 비즈니스 인사이트 제공의 이유로 중요합니다.
결국 비용 이상 탐지를 하려면 클라우드 사용량 및 비용 데이터를 지속적으로 수집되어야 하고 수집된 데이터를 분석하여 비정상적인 패턴을 식별해야합니다.
이후 탐지된 이상을 분류하고 중요도에 따라 우선순위를 지정할 수 있을 것입니다.
또한 이상이 발생했다면 근본 원인을 파악하기 위한 상세 조사를 수행하고 필요한 조치를 취하여 문제를 해결하거나 비용을 최적화하는 것까지 우리는 이 모든 과정을 프로세스로 만들고 지속적으로 개선해 나갈 수 있습니다.
이제 데이터를 수집하고 수집된 데이터를 분석 후 알림을 하는 부분을 어떻게 구현했는지 공유드리도록 하겠습니다.
How?
이 시스템을 구현하기 위해 네이버 클라우드 API, InfluxDB, Facebook Prophet, Slack을 이용했으며 제가 구현한 네이버 클라우드 비용 이상 탐지 시스템의 핵심은 아래 5가지 입니다.
- 네이버 클라우드 API를 통한 데이터 수집
- InfluxDB를 사용한 시계열 데이터 저장
- Facebook Prophet을 활용한 비용 예측
- 예측값과 실제값 비교를 통한 이상 탐지
- Slack을 통한 실시간 알림
1. 데이터 수집
네이버 클라우드 API를 사용하여 비용 데이터를 수집합니다.
사용된 주요 API는 다음과 같습니다.
- getProductDemandCostList: 서비스별 사용 비용
- getDemandCostList: 해당 계정의 총 사용 비용
“참고로 네이버 클라우드 비용 API는 매일 오전 7시경 반영되어 매일 오전 7시 이후 배치성으로 1회 수집되도록 했습니다.”
수집된 데이터는 InfluxDB에 저장합니다. InfluxDB는 시계열 데이터베이스로 시간에 따른 데이터 저장 및 조회에 최적화되어 있고 대량의 시계열 데이터를 빠르게 쿼리하고 집계 가장 적합하다기 때문에 사용하게 되었습니다.
다음은 비용을 InfluxDB에 저장하는 일부 예제 코드입니다.
from influxdb_client import InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
from datetime import datetime, timezone
def write_total_cost_to_influxdb(data, client, bucket, org):
write_api = client.write_api(write_options=SYNCHRONOUS)
total_cost = data['getDemandCostListResponse']['demandCostList'][0]['useAmount']
point = (
Point("ncloud_billing")
.tag("service", "totalcost")
.tag("code", "TOTAL")
.field("use_amount", float(total_cost))
.time(datetime.now(timezone.utc))
)
try:
write_api.write(bucket=bucket, org=org, record=point)
print(f"Total cost data written: use_amount = {total_cost}")
except Exception as e:
print(f"Error writing total cost data: {str(e)}")
# 데이터가 정상적으로 저장되었는지 확인하는 함수
def verify_data_written(client, bucket, org):
query = f'''
from(bucket:"{bucket}")
|> range(start: -5m)
|> filter(fn: (r) => r._measurement == "ncloud_billing")
|> group(columns: ["service", "code"])
|> last()
'''
result = client.query_api().query(query=query, org=org)
print("Verifying written data:")
if not result:
print("No data found in the last 5 minutes.")
for table in result:
for record in table.records:
print(f" {record.values.get('_time')}: {record.values.get('_field')} = {record.values.get('_value')} (Service: {record.values.get('service')}, Code: {record.values.get('code')})")
2. 데이터 예측 및 이상 탐지
이 과정에서 Facebook Prophet이 사용되었는데 Prophet은 시계열 예측을 위해 특별히 설계된 도구로 비용 이상 탐지 시스템에 매우 적합한 특성을 가지고 있습니다. Prophet의 경우 선형 및 비선형 트렌드를 모두 처리할 수 있는데 클라우드 비용은 종종 비선형적으로 변화하므로 적합합니다. 무엇보다 복잡한 시계열 모델링 과정을 자동화하므로 데이터 과학 전문가가 아니어도 쉽게 사용할 수 있다보니 사용하기 적합하다고 판단했습니다.
아래 일부 코드와 같이 수집된 데이터를 바탕으로 Facebook Prophet을 사용하여 미래 비용을 예측하고 실제 비용과 비교하여 이상을 탐지할 수 있도록 했습니다.
from prophet import Prophet
import pandas as pd
def get_all_services():
client = InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG)
query_api = client.query_api()
query = f'''
from(bucket:"{INFLUX_BUCKET}")
|> range(start: -30d) # 최근 30일 데이터 조회
|> filter(fn: (r) => r._measurement == "ncloud_billing")
|> group(columns: ["service"])
|> distinct(column: "service")
'''
result = query_api.query(query=query)
client.close()
services = [record.values.get('service') for table in result for record in table.records]
return services
def get_influxdb_data(service):
client = InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG)
query_api = client.query_api()
query = f'''
from(bucket:"{INFLUX_BUCKET}")
|> range(start: -30d) # 최근 30일 데이터 조회
|> filter(fn: (r) => r._measurement == "ncloud_billing" and r.service == "{service}")
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
'''
result = query_api.query_data_frame(query=query)
client.close()
if result.empty:
return pd.DataFrame()
df = result[["_time", "use_amount"]].copy()
df.columns = ["ds", "y"] # Prophet 모델에 맞게 컬럼명 변경
df['ds'] = pd.to_datetime(df['ds']).dt.tz_localize(None) # 시간대 정보 제거
return df
def detect_anomalies_and_forecast(df, service, threshold_percent=30, forecast_days=3):
if df.empty or len(df) < 2:
return []
model = Prophet(daily_seasonality=True)
model.fit(df)
future = model.make_future_dataframe(periods=forecast_days, freq='D') # 3일 후까지 예측
forecast = model.predict(future)
# InfluxDB에 확장된 예측 데이터 쓰기
client = InfluxDBClient(url=INFLUX_URL, token=INFLUX_TOKEN, org=INFLUX_ORG)
write_extended_forecast_to_influxdb(client, service, forecast)
client.close()
# 이상 탐지 로직
last_forecast = forecast.iloc[-forecast_days-1] # 현재 날짜의 예측값
last_actual = df.iloc[-1] # 가장 최근의 실제 데이터
expected_value = last_forecast['yhat']
actual_value = last_actual['y']
lower_bound = expected_value * (1 - threshold_percent/100) # 30% 이하는 이상으로 간주
upper_bound = expected_value * (1 + threshold_percent/100) # 30% 이상은 이상으로 간주
if actual_value < lower_bound or actual_value > upper_bound:
return [(service, actual_value, lower_bound, upper_bound, expected_value)]
return []
def write_extended_forecast_to_influxdb(client, service, forecast):
write_api = client.write_api(write_options=SYNCHRONOUS)
for _, row in forecast.iterrows():
point = (
Point("ncloud_billing_forecast")
.tag("service", service)
.field("predicted_amount", float(row['yhat']))
.field("lower_bound", float(row['yhat_lower']))
.field("upper_bound", float(row['yhat_upper']))
.time(row['ds'])
)
write_api.write(bucket=INFLUX_BUCKET, org=INFLUX_ORG, record=point)
print(f"Extended forecast for {service} written to InfluxDB")
3. 이상 탐지 알림
Slack WebHook 알림은 너무 잘 알려져있어서 사실 크게 설명드릴 부분이 없을 것같습니다.
다음 일부 코드와 같이 이상이 탐지되면 Slack을 통해 알림을 보내도록 해줬습니다.
import requests
import json
def send_slack_alert(anomalies):
if not anomalies:
return
message = "⚠️ 비용 이상 탐지 알림:\n\n"
for service, actual, lower, upper, expected in anomalies:
message += f"*서비스:* {service}\n"
message += f"*실제 비용:* {actual:.2f}\n"
message += f"*예상 비용:* {expected:.2f}\n"
message += f"*허용 범위:* {lower:.2f} ~ {upper:.2f}\n"
percent_diff = ((actual - expected) / expected) * 100
message += f"*차이:* {percent_diff:.2f}%\n\n"
payload = {"text": message}
try:
response = requests.post(
SLACK_WEBHOOK_URL,
data=json.dumps(payload),
headers={'Content-Type': 'application/json'}
)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"Slack 메시지 전송 오류: {str(e)}")
여기서 제가 제시한 비용 이상 탐지 시스템 구현 방법은 기본적인 아이디어와 접근 방식을 보여주는 것입니다. 서론에 언급했듯 전체 과정을 모두 공유하기에는 내용이 방대하여 이 포스트에서는 InfluxDB 등 소프트웨어 설치 과정 및 전체 코드를 공유하지 않았습니다.
이 시스템을 구현하는데 퇴근 시간을 활용하여 3일 정도 소요한 것같습니다.
따라서 이 시스템을 어렵지 않게 구현하고 여러분의 특정 요구사항에 맞게 커스터마이징하는 것도 가능할 것입니다.
커스터마이징 아이디어는 아래와 같이 고려해볼 수 있을 것같습니다.
- 알림 시스템을 Slack 외의 다른 플랫폼으로 확장
- Grafana를 이용한 실시간 모니터링 대시보드 구축
- 자동화된 리소스 조정 기능 추가
- 다양한 머신러닝 모델을 활용한 예측 정확도 향상
- 비용 최적화를 위한 구체적인 액션 아이템 제안 기능 추가
이러한 아이디어들을 바탕으로 가장 적합한 비용 이상 탐지 및 관리 시스템을 구축한 후 실제로 사용할 수 있는 비용 프로세스를 만들어 나가시기 바랍니다. 이 시스템을 통해 더욱 비용 효율적인 네이버 클라우드 환경으로 최적화가 가능해질 것입니다.
Result
- InfluxDB에서 비용 데이터 조회 시
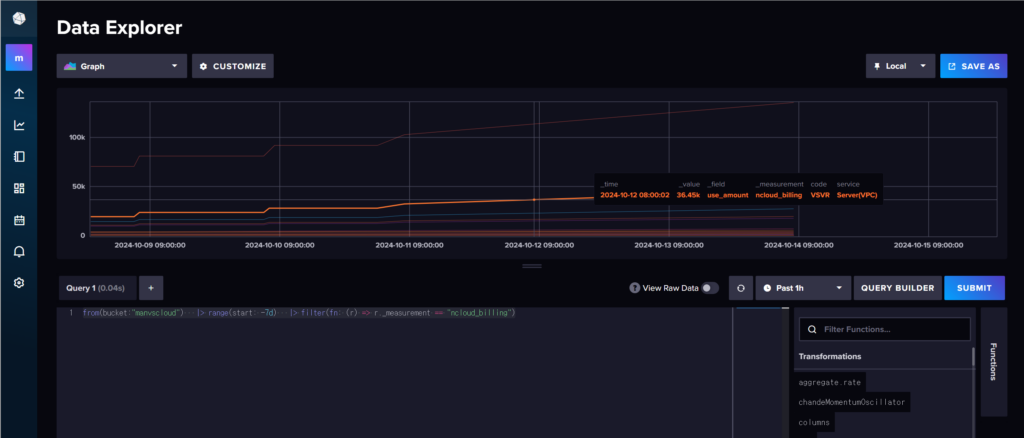
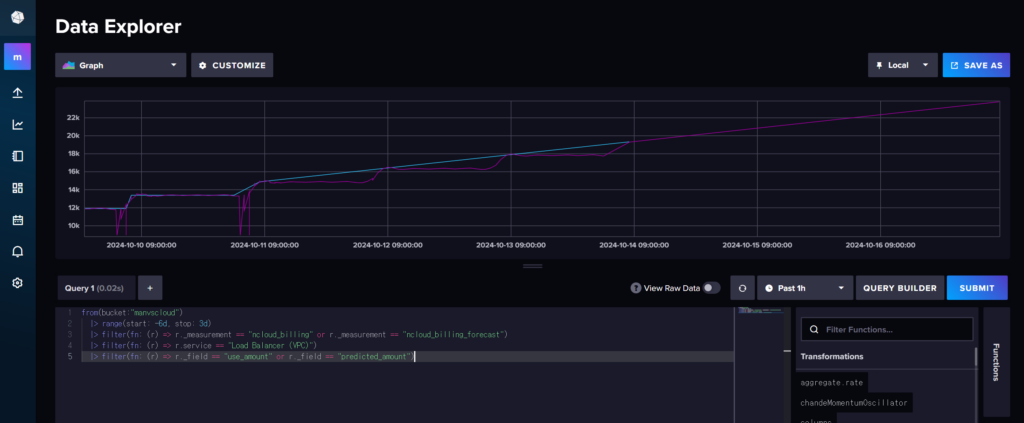
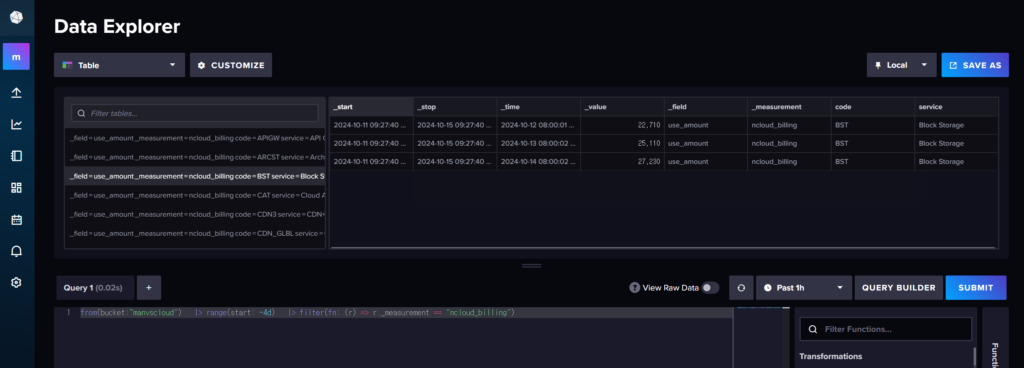
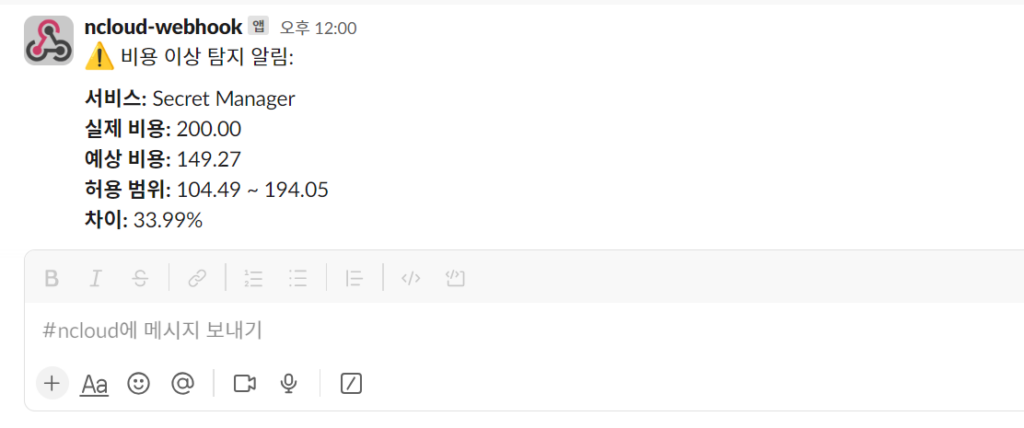
- Slack으로 받아보는 비용 이상 탐지 알림
: 10월 경 네이버 클라우드의 Secret Manager 요금이 유료화 되었을 때 저는 비용 이상 탐지 시스템을 통해 알게 되었습니다.
: Secret Manager의 비용이 갑자기 상승하면서 Slack 알림이 발생
(비용 이상 탐지 GOAT!를 외친 날)
Personal Comments
구현된 비용 이상 탐지 시스템은 예상치 못한 또는 예측하지 못한 클라우드 비용 이벤트를 적시에 감지, 식별, 명확히 하고, 경고하고 관리하여 비즈니스, 비용 또는 기타에 대한 부정적인 영향을 최소화할 것입니다. 지속적인 모니터링, 분석, 그리고 최적화를 통해 클라우드 환경에서 최대의 가치를 창출할 수 있습니다. 비용 이상 탐지는 이러한 지속적인 개선 과정의 중요한 부분이며 앞으로 더욱 발전된 기술과 방법론을 통해 더 나은 클라우드 관리가 가능해질 것입니다.
다음 포스트 “[NCLOUD] 네이버 클라우드에서 비용 이상 탐지를 추구하면 안 되는 걸까 #2”에서는 Grafana를 활용해 비용 모니터링 대시보드 구현 및 대시보드를 Slack으로 전달 그리고 생성형 AI를 활용해 자동화된 비용 보고서를 생성하는 법까지 다룰 예정입니다.
이를 통해 더욱 강력하고 직관적인 비용 관리 시스템을 구축하는 방법을 공유드려보겠습니다.
긴 글 읽어주셔서 감사합니다.